稀疏隨機投影#
- class sklearn.random_projection.SparseRandomProjection(n_components='auto', *, density='auto', eps=0.1, dense_output=False, compute_inverse_components=False, random_state=None)[來源]#
透過稀疏隨機投影減少維度。
稀疏隨機矩陣是稠密隨機投影矩陣的替代方案,可保證相似的嵌入品質,同時更節省記憶體並允許更快地計算投影資料。
如果我們將
s = 1 / density記為隨機矩陣的成分,則從以下位置提取-sqrt(s) / sqrt(n_components) with probability 1 / 2s 0 with probability 1 - 1 / s +sqrt(s) / sqrt(n_components) with probability 1 / 2s
在使用者指南中閱讀更多內容。
在 0.13 版本中新增。
- 參數:
- n_componentsint 或 ‘auto’,預設值 = ‘auto’
目標投影空間的維度。
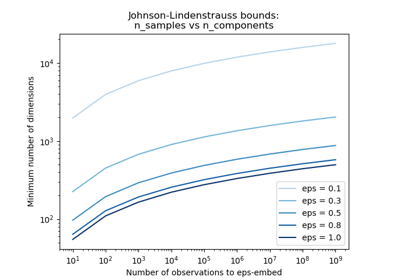
n_components 可以根據資料集中樣本的數量和 Johnson-Lindenstrauss 引理給定的界限自動調整。在這種情況下,嵌入的品質由
eps參數控制。應該注意的是,Johnson-Lindenstrauss 引理可以產生對所需元件數量非常保守的估計,因為它沒有對資料集的結構做出任何假設。
- densityfloat 或 ‘auto’,預設值 = ‘auto’
隨機投影矩陣中非零成分在範圍 (0, 1] 內的比例。
如果 density = ‘auto’,則該值設定為 Ping Li 等人建議的最小密度:1 / sqrt(n_features)。
如果您想要重現 Achlioptas, 2001 的結果,請使用密度 (density) = 1 / 3.0。
- eps浮點數 (float), 預設值=0.1
當 n_components 設定為 ‘auto’ 時,根據 Johnson-Lindenstrauss 引理控制嵌入品質的參數。此值必須嚴格為正數。
較小的值會產生較好的嵌入效果,並在目標投影空間中產生較高的維度 (n_components) 數量。
- dense_output布林值 (bool), 預設值=False
如果為 True,即使輸入和隨機投影矩陣都是稀疏的,也要確保隨機投影的輸出是一個密集的 NumPy 陣列。實際上,如果組件的數量很小,投影數據中的零組件數量將會非常小,使用密集的表示法在 CPU 和記憶體方面會更有效率。
如果為 False,則當輸入為稀疏時,投影數據會使用稀疏表示法。
- compute_inverse_components布林值 (bool), 預設值=False
透過在擬合期間計算組件的偽逆矩陣來學習逆變換。請注意,即使訓練數據是稀疏的,偽逆矩陣也始終是一個密集的陣列。這表示可能需要一次在小批次的樣本上呼叫
inverse_transform,以避免耗盡主機上的可用記憶體。此外,計算偽逆矩陣不適用於大型矩陣。- random_state整數 (int), RandomState 實例或 None, 預設值=None
控制用於在擬合時產生投影矩陣的偽隨機數產生器。傳遞一個整數可以在多次函式呼叫中產生可重複的輸出。請參閱 詞彙表。
- 屬性:
- n_components_整數 (int)
當 n_components="auto" 時計算出的組件的實際數量。
- components_形狀為 (n_components, n_features) 的稀疏矩陣
用於投影的隨機矩陣。稀疏矩陣將採用 CSR 格式。
- inverse_components_形狀為 (n_features, n_components) 的 ndarray
組件的偽逆矩陣,僅當
compute_inverse_components為 True 時才會計算。新增於 1.1 版本。
- density_範圍在 0.0 - 1.0 的浮點數 (float)
當 density = "auto" 時計算出的實際密度。
- n_features_in_整數 (int)
在 fit 期間看到的特徵數量。
新增於 0.24 版本。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有都是字串的特徵名稱時才會定義。新增於 1.0 版本。
另請參閱
高斯隨機投影透過高斯隨機投影減少維度。
參考文獻
[1]Ping Li, T. Hastie 和 K. W. Church, 2006, “Very Sparse Random Projections”. https://web.stanford.edu/~hastie/Papers/Ping/KDD06_rp.pdf
[2]D. Achlioptas, 2001, “Database-friendly random projections”, https://cgi.di.uoa.gr/~optas/papers/jl.pdf
範例
>>> import numpy as np >>> from sklearn.random_projection import SparseRandomProjection >>> rng = np.random.RandomState(42) >>> X = rng.rand(25, 3000) >>> transformer = SparseRandomProjection(random_state=rng) >>> X_new = transformer.fit_transform(X) >>> X_new.shape (25, 2759) >>> # very few components are non-zero >>> np.mean(transformer.components_ != 0) np.float64(0.0182...)
- fit(X, y=None)[原始碼]#
產生稀疏隨機投影矩陣。
- 參數:
- X形狀為 (n_samples, n_features) 的 {ndarray, 稀疏矩陣}
訓練集:僅使用形狀來根據上述論文中引用的理論找到最佳的隨機矩陣維度。
- y忽略
未使用,此處為了 API 一致性而依慣例存在。
- 回傳:
- self物件
BaseRandomProjection 類別實例。
- fit_transform(X, y=None, **fit_params)[原始碼]#
擬合資料,然後轉換它。
使用可選參數
fit_params將轉換器擬合到X和y,並回傳X的轉換版本。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
輸入樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列 (array-like), 預設值=None
目標值(對於無監督轉換為 None)。
- **fit_params字典 (dict)
額外的擬合參數。
- 回傳:
- X_new形狀為 (n_samples, n_features_new) 的 ndarray 陣列
轉換後的陣列。
- get_feature_names_out(input_features=None)[原始碼]#
取得轉換的輸出特徵名稱。
輸出的特徵名稱會以小寫的類別名稱作為前綴。例如,如果轉換器輸出 3 個特徵,則輸出的特徵名稱為:
["class_name0", "class_name1", "class_name2"]。- 參數:
- input_features字串或 None 的類陣列 (array-like),預設值=None
僅用於使用
fit中看到的名稱來驗證特徵名稱。
- 回傳:
- feature_names_out字串物件的 ndarray
轉換後的特徵名稱。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看關於路由機制如何運作的 使用者指南。
- 回傳:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deep布林值 (bool), 預設值=True
如果為 True,則會回傳此估算器的參數以及其中包含的子物件(這些子物件也是估算器)。
- 回傳:
- paramsdict
參數名稱對應到它們的值。
- inverse_transform(X)[原始碼]#
將資料投影回原始空間。
返回一個陣列 X_original,其轉換結果會是 X。請注意,即使 X 是稀疏的,X_original 也是密集的:這可能會使用大量 RAM。
如果
compute_inverse_components為 False,則會在每次調用inverse_transform時計算組件的反向,這可能會很耗費成本。- 參數:
- X形狀為 (n_samples, n_components) 的 {類陣列, 稀疏矩陣}
要轉換回來的資料。
- 回傳:
- X_original形狀為 (n_samples, n_features) 的 ndarray
重建的資料。
- set_output(*, transform=None)[原始碼]#
設定輸出容器。
有關如何使用 API 的範例,請參閱 介紹 set_output API。
- 參數:
- transform{“default”, “pandas”, “polars”}, 預設值=None
設定
transform和fit_transform的輸出格式。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換設定保持不變
在 1.4 版本中新增:新增了
"polars"選項。
- 回傳:
- self估算器實例
估算器實例。