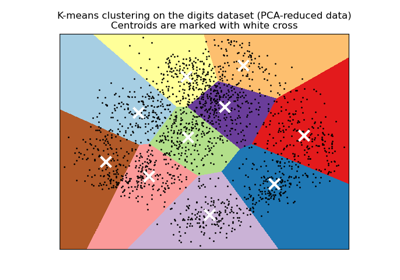
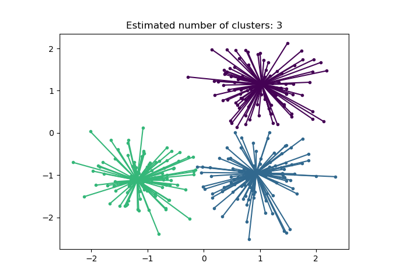
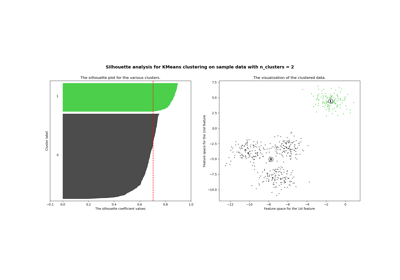
輪廓係數 (silhouette_score)#
- sklearn.metrics.silhouette_score(X, labels, *, metric='euclidean', sample_size=None, random_state=None, **kwds)[原始碼]#
計算所有樣本的平均輪廓係數。
輪廓係數 (Silhouette Coefficient) 的計算方式是使用每個樣本的平均群內距離 (intra-cluster distance)(
a)和平均最近群距離 (mean nearest-cluster distance)(b)。樣本的輪廓係數為(b - a) / max(a, b)。更明確地說,b是指樣本與其非屬的最近群集之間的距離。請注意,輪廓係數僅在標籤數量滿足2 <= n_labels <= n_samples - 1的條件下定義。此函數返回所有樣本的平均輪廓係數。若要取得每個樣本的值,請使用
silhouette_samples。最佳值為 1,最差值為 -1。接近 0 的值表示群集重疊。負值通常表示樣本被分配到錯誤的群集,因為有其他群集更相似。
請在使用者指南中閱讀更多資訊。
- 參數:
- X形狀為 (n_samples_a, n_samples_a) 的類陣列或稀疏矩陣 (如果 metric == "precomputed") 或 (n_samples_a, n_features) (其他情況)
樣本之間的成對距離陣列,或特徵陣列。
- labels形狀為 (n_samples,) 的類陣列
每個樣本的預測標籤。
- metricstr 或可調用物件,預設為 ‘euclidean’
在計算特徵陣列中實例之間的距離時使用的度量。如果 metric 是字串,則它必須是
pairwise_distances允許的選項之一。如果X本身就是距離陣列,請使用metric="precomputed"。- sample_sizeint,預設為 None
在隨機子集的資料上計算輪廓係數時要使用的樣本大小。如果
sample_size is None,則不使用取樣。- random_stateint、RandomState 實例或 None,預設為 None
決定選擇樣本子集的隨機數產生。當
sample_size is not None時使用。傳遞 int 以在多個函數呼叫中獲得可重現的結果。請參閱詞彙表。- **kwds可選的關鍵字參數
任何其他參數都直接傳遞給距離函數。如果使用 scipy.spatial.distance 度量,則參數仍取決於度量。請參閱 scipy 文件以取得用法範例。
- 返回:
- silhouettefloat
所有樣本的平均輪廓係數。
參考文獻
範例
>>> from sklearn.datasets import make_blobs >>> from sklearn.cluster import KMeans >>> from sklearn.metrics import silhouette_score >>> X, y = make_blobs(random_state=42) >>> kmeans = KMeans(n_clusters=2, random_state=42) >>> silhouette_score(X, kmeans.fit_predict(X)) np.float64(0.49...)