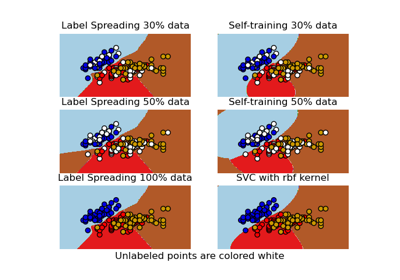
SelfTrainingClassifier#
- class sklearn.semi_supervised.SelfTrainingClassifier(estimator=None, base_estimator='deprecated', threshold=0.75, criterion='threshold', k_best=10, max_iter=10, verbose=False)[原始碼]#
自訓練分類器。
此元估計器允許給定的監督式分類器作為半監督式分類器運作,使其能夠從未標記的資料中學習。它透過迭代預測未標記資料的偽標籤,並將它們加入訓練集來實現此功能。
分類器將持續迭代,直到達到 max_iter,或在前一次迭代中沒有偽標籤加入訓練集為止。
請參閱使用者指南以取得更多資訊。
- 參數:
- estimator估計器物件
一個實作
fit和predict_proba的估計器物件。呼叫fit方法將會擬合傳遞的估計器的複製版本,該複製版本將儲存在estimator_屬性中。1.6 版本新增: 新增
estimator以取代base_estimator。- base_estimator估計器物件
一個實作
fit和predict_proba的估計器物件。呼叫fit方法將會擬合傳遞的估計器的複製版本,該複製版本將儲存在estimator_屬性中。自 1.6 版本起已棄用:
base_estimator在 1.6 版本中已棄用,並將在 1.8 版本中移除。請改用estimator。- thresholdfloat,預設值=0.75
與
criterion='threshold'一起使用的決策門檻。應在 [0, 1) 範圍內。當使用'threshold'準則時,應使用良好校準的分類器。- criterion{‘threshold’、‘k_best’},預設值=‘threshold’
用於選擇要加入訓練集的標籤的選擇準則。如果為
'threshold',則將預測機率高於threshold的偽標籤加入資料集。如果為'k_best',則將預測機率最高的k_best個偽標籤加入資料集。當使用「threshold」準則時,應使用良好校準的分類器。- k_bestint,預設值=10
每次迭代要加入的樣本數量。僅當
criterion='k_best'時使用。- max_iterint 或 None,預設值=10
允許的最大迭代次數。應大於或等於 0。如果為
None,分類器將會持續預測標籤,直到沒有新的偽標籤加入,或是所有未標記的樣本都已標記為止。- verbosebool,預設值=False
啟用詳細輸出。
- 屬性:
- estimator_估計器物件
已擬合的估計器。
- classes_ndarray 或形狀為 (n_classes,) 的 ndarray 列表
每個輸出的類別標籤。(取自訓練過的
estimator_)。- transduction_形狀為 (n_samples,) 的 ndarray
用於分類器最終擬合的標籤,包括擬合期間加入的偽標籤。
- labeled_iter_形狀為 (n_samples,) 的 ndarray
每個樣本被標記的迭代次數。當樣本的迭代次數為 0 時,表示樣本已在原始資料集中標記。當樣本的迭代次數為 -1 時,表示樣本在任何迭代中都未被標記。
- n_features_in_int
在擬合期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在擬合期間看到的特徵名稱。僅當
X具有所有字串的特徵名稱時定義。在 1.0 版本中新增。
- n_iter_int
自訓練的回合數,也就是基底估計器在訓練集的重新標記變體上擬合的次數。
- termination_condition_{‘max_iter’、‘no_change’、‘all_labeled’}
停止擬合的原因。
'max_iter':n_iter_達到max_iter。'no_change': 沒有預測到新的標籤。'all_labeled': 在達到max_iter之前,所有未標記的樣本都已標記。
另請參閱
LabelPropagation標籤傳播分類器。
LabelSpreading用於半監督式學習的標籤擴散模型。
參考文獻
範例
>>> import numpy as np >>> from sklearn import datasets >>> from sklearn.semi_supervised import SelfTrainingClassifier >>> from sklearn.svm import SVC >>> rng = np.random.RandomState(42) >>> iris = datasets.load_iris() >>> random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3 >>> iris.target[random_unlabeled_points] = -1 >>> svc = SVC(probability=True, gamma="auto") >>> self_training_model = SelfTrainingClassifier(svc) >>> self_training_model.fit(iris.data, iris.target) SelfTrainingClassifier(...)
- decision_function(X, **params)[原始碼]#
呼叫
estimator的決策函數。- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
代表資料的陣列。
- **paramsdict,str -> object
要傳遞給底層估計器的
decision_function方法的參數。1.6 版本新增: 只有在
enable_metadata_routing=True時才可用,可以使用sklearn.set_config(enable_metadata_routing=True)來設定。請參閱中繼資料路由使用者指南以取得更多詳細資訊。
- 傳回:
- y形狀為 (n_samples, n_features) 的 ndarray
estimator的決策函數的結果。
- fit(X, y, **params)[原始碼]#
使用
X、y作為訓練資料來擬合自訓練分類器。- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
代表資料的陣列。
- y形狀為 (n_samples,) 的 {類陣列,稀疏矩陣}
代表標籤的陣列。未標記的樣本應具有標籤 -1。
- **paramsdict
要傳遞給底層估計器的參數。
1.6 版本新增: 只有在
enable_metadata_routing=True時才可用,可以使用sklearn.set_config(enable_metadata_routing=True)來設定。請參閱中繼資料路由使用者指南以取得更多詳細資訊。
- 傳回:
- self物件
已擬合的估算器。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,了解路由機制的運作方式。
於 1.6 版本新增。
- 傳回:
- routingMetadataRouter
一個封裝路由資訊的
MetadataRouter。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
如果為 True,將傳回此估算器及其包含的子物件(也是估算器)的參數。
- 傳回:
- paramsdict
參數名稱對應到其值的字典。
- predict(X, **params)[原始碼]#
預測
X的類別。- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
代表資料的陣列。
- **paramsdict,str -> object
要傳遞給底層估算器的
predict方法的參數。1.6 版本新增: 只有在
enable_metadata_routing=True時才可用,可以使用sklearn.set_config(enable_metadata_routing=True)來設定。請參閱中繼資料路由使用者指南以取得更多詳細資訊。
- 傳回:
- y形狀為 (n_samples,) 的 ndarray
包含預測標籤的陣列。
- predict_log_proba(X, **params)[原始碼]#
預測每個可能結果的對數機率。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
代表資料的陣列。
- **paramsdict,str -> object
要傳遞給底層估算器的
predict_log_proba方法的參數。1.6 版本新增: 只有在
enable_metadata_routing=True時才可用,可以使用sklearn.set_config(enable_metadata_routing=True)來設定。請參閱中繼資料路由使用者指南以取得更多詳細資訊。
- 傳回:
- y形狀為 (n_samples, n_features) 的 ndarray
包含對數預測機率的陣列。
- predict_proba(X, **params)[原始碼]#
預測每個可能結果的機率。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
代表資料的陣列。
- **paramsdict,str -> object
要傳遞給底層估算器的
predict_proba方法的參數。1.6 版本新增: 只有在
enable_metadata_routing=True時才可用,可以使用sklearn.set_config(enable_metadata_routing=True)來設定。請參閱中繼資料路由使用者指南以取得更多詳細資訊。
- 傳回:
- y形狀為 (n_samples, n_features) 的 ndarray
包含預測機率的陣列。
- score(X, y, **params)[原始碼]#
在
estimator上呼叫 score。- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
代表資料的陣列。
- y形狀為 (n_samples,) 的類陣列
代表標籤的陣列。
- **paramsdict,str -> object
要傳遞給底層估算器的
score方法的參數。1.6 版本新增: 只有在
enable_metadata_routing=True時才可用,可以使用sklearn.set_config(enable_metadata_routing=True)來設定。請參閱中繼資料路由使用者指南以取得更多詳細資訊。
- 傳回:
- scorefloat
在
estimator上呼叫 score 的結果。