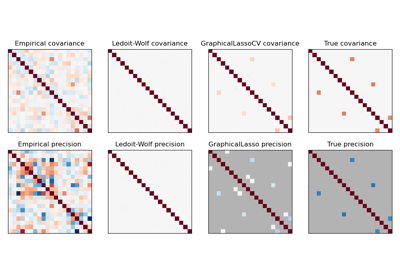
GraphicalLassoCV#
- class sklearn.covariance.GraphicalLassoCV(*, alphas=4, n_refinements=4, cv=None, tol=0.0001, enet_tol=0.0001, max_iter=100, mode='cd', n_jobs=None, verbose=False, eps=np.float64(2.220446049250313e-16), assume_centered=False)[原始碼]#
使用交叉驗證選擇 l1 懲罰的稀疏逆共變異數。
請參閱 交叉驗證估計器 的詞彙表條目。
請在 使用者指南 中閱讀更多資訊。
在 v0.20 版本中變更:GraphLassoCV 已重新命名為 GraphicalLassoCV
- 參數:
- alphasint 或形狀為 (n_alphas,) 的類陣列,dtype=float,預設值為 4
如果給定一個整數,它會固定要使用的 alpha 網格上的點數。如果給定一個列表,則會給定要使用的網格。 有關更多詳細資訊,請參閱類別文件字串中的註解。 整數的範圍為 [1, inf)。浮點數的類陣列的範圍為 (0, inf]。
- n_refinementsint,預設值為 4
網格被精煉的次數。 如果傳遞了 alpha 的明確值,則不會使用。 範圍為 [1, inf)。
- cvint、交叉驗證生成器或可迭代物件,預設值為 None
決定交叉驗證分割策略。cv 的可能輸入值為
None,使用預設的 5 折交叉驗證,
integer,指定折疊數。
一個可迭代物件,產生 (訓練,測試) 分割作為索引陣列。
對於 integer/None 輸入,會使用
KFold。請參閱 使用者指南,以了解可在此處使用的各種交叉驗證策略。
在 0.20 版本中變更:如果 cv 為 None,則
cv的預設值從 3 折變更為 5 折。- tolfloat,預設值為 1e-4
宣告收斂的容差:如果對偶間隙低於此值,則迭代會停止。範圍為 (0, inf]。
- enet_tolfloat,預設值為 1e-4
用於計算下降方向的彈性網求解器的容差。此參數控制給定列更新的搜尋方向準確度,而非整體參數估計。僅適用於 mode=’cd’。範圍為 (0, inf]。
- max_iterint,預設值為 100
最大迭代次數。
- mode{‘cd’, ‘lars’},預設值為 ‘cd’
要使用的 Lasso 求解器:座標下降或 LARS。對於非常稀疏的基礎圖,其中特徵數量大於樣本數量,請使用 LARS。其他情況請使用 cd,它在數值上更穩定。
- n_jobsint,預設值為 None
要並行執行的作業數量。除非在
joblib.parallel_backend環境中,否則None表示 1。-1表示使用所有處理器。有關更多詳細資訊,請參閱 詞彙表。在 v0.20 版本中變更:
n_jobs預設值從 1 變更為 None- verbosebool,預設值為 False
如果 verbose 為 True,則會在每次迭代時列印目標函數和對偶間隙。
- epsfloat,預設值為 eps
在計算 Cholesky 對角因數時的機器精度正規化。對於病態條件非常嚴重的系統,請增加此值。預設值為
np.finfo(np.float64).eps。在 1.3 版本中新增。
- assume_centeredbool,預設值為 False
如果為 True,則在計算之前不會將資料置中。當處理平均值接近但不完全為零的資料時非常有用。如果為 False,則會在計算之前將資料置中。
- 屬性:
- location_形狀為 (n_features,) 的 ndarray
估計的位置,即估計的平均值。
- covariance_形狀為 (n_features, n_features) 的 ndarray
估計的共變異數矩陣。
- precision_形狀為 (n_features, n_features) 的 ndarray
估計的精確度矩陣(逆共變異數)。
- costs_(目標, 對偶間隙) 對的列表
每次迭代時目標函數和對偶間隙值的列表。僅當 return_costs 為 True 時才會傳回。
在 1.3 版本中新增。
- alpha_float
選取的懲罰參數。
- cv_results_ndarray 的字典
具有索引鍵的字典
- alphas形狀為 (n_alphas,) 的 ndarray
所有已探索的懲罰參數。
- split(k)_test_score形狀為 (n_alphas,) 的 ndarray
在第 (k) 折疊的保留資料上的對數可能性評分。
在 1.0 版本中新增。
- mean_test_score形狀為 (n_alphas,) 的 ndarray
在折疊上的分數平均值。
在 1.0 版本中新增。
- std_test_score形狀為 (n_alphas,) 的 ndarray
摺疊中分數的標準差。
在 1.0 版本中新增。
- n_iter_整數
最佳 alpha 值所執行的迭代次數。
- n_features_in_整數
在 fit 期間看到的特徵數量。
在版本 0.24 中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有全部為字串的特徵名稱時才定義。在 1.0 版本中新增。
另請參閱
graphical_lassoL1 懲罰的共變異數估計器。
GraphicalLasso使用 l1 懲罰估計器的稀疏逆共變異數估計。
注意事項
最佳懲罰參數(
alpha)的搜尋是在迭代細化的網格上完成的:首先計算網格上的交叉驗證分數,然後圍繞最大值居中新的細化網格,依此類推。這裡面臨的挑戰之一是求解器可能無法收斂到良好條件的估計。然後,
alpha的對應值會顯示為遺失值,但最佳值可能接近這些遺失值。在
fit中,一旦通過交叉驗證找到最佳參數alpha,就會使用整個訓練集再次擬合模型。範例
>>> import numpy as np >>> from sklearn.covariance import GraphicalLassoCV >>> true_cov = np.array([[0.8, 0.0, 0.2, 0.0], ... [0.0, 0.4, 0.0, 0.0], ... [0.2, 0.0, 0.3, 0.1], ... [0.0, 0.0, 0.1, 0.7]]) >>> np.random.seed(0) >>> X = np.random.multivariate_normal(mean=[0, 0, 0, 0], ... cov=true_cov, ... size=200) >>> cov = GraphicalLassoCV().fit(X) >>> np.around(cov.covariance_, decimals=3) array([[0.816, 0.051, 0.22 , 0.017], [0.051, 0.364, 0.018, 0.036], [0.22 , 0.018, 0.322, 0.094], [0.017, 0.036, 0.094, 0.69 ]]) >>> np.around(cov.location_, decimals=3) array([0.073, 0.04 , 0.038, 0.143])
- error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[原始碼]#
計算兩個共變異數估計器之間的均方誤差。
- 參數:
- comp_cov形狀為 (n_features, n_features) 的類陣列
要比較的共變異數。
- norm{“frobenius”, “spectral”}, default=”frobenius”
用於計算誤差的範數類型。可用的誤差類型:- ‘frobenius’(預設):sqrt(tr(A^t.A)) - ‘spectral’:sqrt(max(eigenvalues(A^t.A)),其中 A 是誤差
(comp_cov - self.covariance_)。- scaling布林值,預設值=True
如果為 True(預設值),則平方誤差範數除以 n_features。如果為 False,則不重新縮放平方誤差範數。
- squared布林值,預設值=True
是否計算平方誤差範數或誤差範數。如果為 True(預設值),則傳回平方誤差範數。如果為 False,則傳回誤差範數。
- 回傳值:
- result浮點數
在
self和comp_cov共變異數估計器之間(在 Frobenius 範數的意義上)的均方誤差。
- fit(X, y=None, **params)[原始碼]#
將 GraphicalLasso 共變異數模型擬合到 X。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
用來計算共變異數估計的資料。
- y已忽略
未使用,為符合 API 一致性而存在。
- **params字典,預設值=None
要傳遞給 CV 分割器和 cross_val_score 函式的參數。
在版本 1.5 中新增:僅在
enable_metadata_routing=True時可用,可以使用sklearn.set_config(enable_metadata_routing=True)設定。有關更多詳細資訊,請參閱 中繼資料路由使用者指南。
- 回傳值:
- self物件
傳回實例本身。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看 使用者指南,了解路由機制的運作方式。
在版本 1.5 中新增。
- 回傳值:
- routingMetadataRouter
封裝路由資訊的
MetadataRouter。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deep布林值,預設值=True
如果為 True,將傳回此估計器和所包含的子物件(為估計器)的參數。
- 回傳值:
- params字典
對應到其值的參數名稱。
- get_precision()[原始碼]#
精度矩陣的 Getter。
- 回傳值:
- precision_形狀為 (n_features, n_features) 的類陣列
與目前共變異數物件相關聯的精度矩陣。
- mahalanobis(X)[原始碼]#
計算給定觀測值的平方馬氏距離。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
我們計算馬氏距離的觀測值。假設觀測值是從與 fit 中使用的資料相同的分佈中提取的。
- 回傳值:
- dist形狀為 (n_samples,) 的 ndarray
觀測值的平方馬氏距離。
- score(X_test, y=None)[原始碼]#
計算在估計的高斯模型下
X_test的對數似然率。高斯模型由其平均值和共變異數矩陣定義,分別以
self.location_和self.covariance_表示。- 參數:
- X_test形狀為 (n_samples, n_features) 的類陣列
我們計算其似然率的測試資料,其中
n_samples是樣本數,n_features是特徵數。X_test假設是從適合時所用資料的相同分佈中抽取的(包括中心化)。- y已忽略
未使用,為符合 API 一致性而存在。
- 回傳值:
- res浮點數
使用
self.location_和self.covariance_作為高斯模型平均值和共變異數矩陣的估計值,X_test的對數似然率。