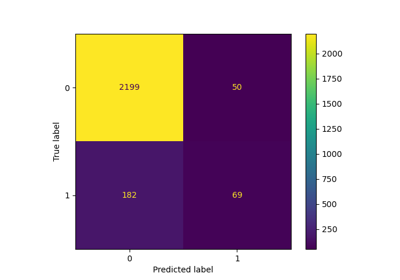
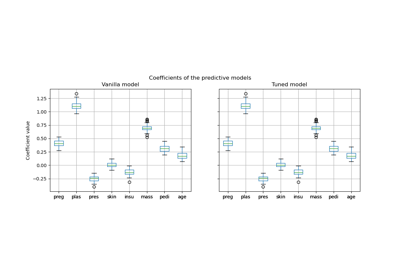
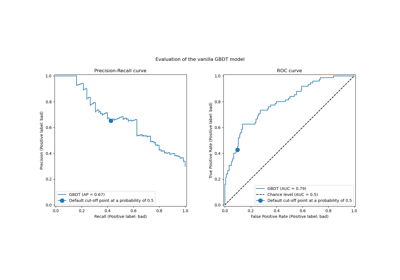
調整閾值分類器交叉驗證 (TunedThresholdClassifierCV)#
- class sklearn.model_selection.TunedThresholdClassifierCV(estimator, *, scoring='balanced_accuracy', response_method='auto', thresholds=100, cv=None, refit=True, n_jobs=None, random_state=None, store_cv_results=False)[來源]#
使用交叉驗證後調整決策閾值的分類器。
此估計器會後調整決策閾值(臨界點),該閾值用於將後驗機率估計值(即
predict_proba的輸出)或決策分數(即decision_function的輸出)轉換為類別標籤。調整是透過最佳化二元度量來完成的,可能會受到另一個度量的限制。在使用者指南中閱讀更多內容。
在 1.5 版本中新增。
- 參數:
- estimator估計器實例
我們想要最佳化在
predict期間使用的決策閾值的分類器,無論是否已擬合。- scoring字串或可呼叫物件,預設值為 “balanced_accuracy”
要最佳化的目標度量。可以是以下之一
與二元分類評分函數相關的字串(請參閱評分參數:定義模型評估規則);
使用
make_scorer建立的評分器可呼叫物件;
- response_method{“auto”, “decision_function”, “predict_proba”},預設值為 “auto”
分類器
estimator的方法,對應於我們想要尋找閾值的決策函數。它可以是如果
"auto",它會嘗試按順序為每個分類器呼叫"predict_proba"或"decision_function"。否則,為
"predict_proba"或"decision_function"之一。如果分類器未實作該方法,則會引發錯誤。
- thresholds整數或類似陣列,預設值為 100
在離散化分類器
method的輸出時要使用的決策閾值數量。傳遞一個類似陣列的物件以手動指定要使用的閾值。- cv整數、浮點數、交叉驗證產生器、可迭代物件或 “prefit”,預設值為 None
決定訓練分類器的交叉驗證拆分策略。cv 的可能輸入為
None,使用預設的 5 折分層 K 折交叉驗證;整數,以指定分層 k 折中的折數;
浮點數,以指定單次洗牌分割。浮點數應介於 (0, 1) 之間,並表示驗證集的大小;
要用作交叉驗證產生器的物件;
產生訓練、測試分割的可迭代物件;
"prefit",以略過交叉驗證。
請參閱使用者指南以瞭解此處可以使用的各種交叉驗證策略。
警告
使用
cv="prefit"並傳遞相同的資料集以擬合estimator和調整臨界點可能會導致不必要的過度擬合。您可以參考關於模型重新擬合和交叉驗證的考量以取得範例。只有在用於擬合
estimator的集合與用於調整臨界點的集合不同時,才應使用此選項(透過呼叫TunedThresholdClassifierCV.fit)。- refit布林值,預設值為 True
是否要在找到決策閾值後,在整個訓練集上重新擬合分類器。請注意,在有多個分割的交叉驗證上強制執行
refit=False會引發錯誤。同樣,refit=True與cv="prefit"結合使用也會引發錯誤。- n_jobs整數,預設值為 None
要平行執行的作業數。當
cv表示交叉驗證策略時,每個資料分割的擬合和評分會平行完成。None表示 1,除非在joblib.parallel_backend內容中。-1表示使用所有處理器。請參閱詞彙表以取得更多詳細資訊。- random_state整數、RandomState 實例或 None,預設值為 None
當
cv為浮點數時,控制交叉驗證的隨機性。請參閱詞彙表。- store_cv_resultsbool,預設為 False
是否儲存交叉驗證過程中計算的所有分數和閾值。
- 屬性:
- estimator_估計器實例
用於預測的已擬合分類器。
- best_threshold_浮點數
新的決策閾值。
- best_score_浮點數或 None
目標指標的最佳分數,在
best_threshold_處評估。- cv_results_字典或 None
一個包含交叉驗證過程中計算的分數和閾值的字典。僅在
store_cv_results=True時存在。鍵值為"thresholds"和"scores"。classes_形狀為 (n_classes,) 的 ndarray類別標籤。
- n_features_in_整數
在 fit 期間看到的特徵數量。僅當底層估計器在擬合時公開此屬性時才定義。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當底層估計器在擬合時公開此屬性時才定義。
參見
範例
>>> from sklearn.datasets import make_classification >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.metrics import classification_report >>> from sklearn.model_selection import TunedThresholdClassifierCV, train_test_split >>> X, y = make_classification( ... n_samples=1_000, weights=[0.9, 0.1], class_sep=0.8, random_state=42 ... ) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, stratify=y, random_state=42 ... ) >>> classifier = RandomForestClassifier(random_state=0).fit(X_train, y_train) >>> print(classification_report(y_test, classifier.predict(X_test))) precision recall f1-score support 0 0.94 0.99 0.96 224 1 0.80 0.46 0.59 26 accuracy 0.93 250 macro avg 0.87 0.72 0.77 250 weighted avg 0.93 0.93 0.92 250 >>> classifier_tuned = TunedThresholdClassifierCV( ... classifier, scoring="balanced_accuracy" ... ).fit(X_train, y_train) >>> print( ... f"Cut-off point found at {classifier_tuned.best_threshold_:.3f}" ... ) Cut-off point found at 0.342 >>> print(classification_report(y_test, classifier_tuned.predict(X_test))) precision recall f1-score support 0 0.96 0.95 0.96 224 1 0.61 0.65 0.63 26 accuracy 0.92 250 macro avg 0.78 0.80 0.79 250 weighted avg 0.92 0.92 0.92 250
- 屬性 classes_#
類別標籤。
- decision_function(X)[原始碼]#
使用已擬合的估計器,計算
X中樣本的決策函數。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列、稀疏矩陣
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。
- 回傳:
- 決策形狀為 (n_samples,) 的 ndarray
由已擬合估計器計算的決策函數。
- fit(X, y, **params)[原始碼]#
擬合分類器。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列、稀疏矩陣
訓練資料。
- y形狀為 (n_samples,) 的類陣列
目標值。
- **params字典
要傳遞給底層分類器的
fit方法的參數。
- 回傳:
- self物件
回傳自身的實例。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請檢查 使用者指南,了解路由機制如何運作。
- 回傳:
- routingMetadataRouter
一個封裝路由資訊的
MetadataRouter。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設為 True
若為 True,則會回傳此估計器和包含的子物件(屬於估計器)的參數。
- 回傳:
- params字典
參數名稱對應到其值的映射。
- predict(X)[原始碼]#
預測新樣本的目標。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列、稀疏矩陣
樣本,與
estimator.predict接受的格式相同。
- 回傳:
- class_labels形狀為 (n_samples,) 的 ndarray
預測的類別。
- predict_log_proba(X)[原始碼]#
使用已擬合的估計器,預測
X的對數類別機率。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列、稀疏矩陣
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。
- 回傳:
- log_probabilities形狀為 (n_samples, n_classes) 的 ndarray
輸入樣本的對數類別機率。
- predict_proba(X)[原始碼]#
使用已擬合的估計器,預測
X的類別機率。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列、稀疏矩陣
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。
- 回傳:
- probabilities形狀為 (n_samples, n_classes) 的 ndarray
輸入樣本的類別機率。
- score(X, y, sample_weight=None)[原始碼]#
回傳給定測試資料和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴格的指標,因為您要求每個樣本都必須正確預測每個標籤集。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
測試樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列
X的真實標籤。- sample_weight形狀為 (n_samples,) 的類陣列,預設為 None
樣本權重。
- 回傳:
- score浮點數
self.predict(X)相對於y的平均準確度。
- set_params(**params)[原始碼]#
設定此估計器的參數。
此方法適用於簡單的估計器以及巢狀物件(例如
Pipeline)。後者的參數格式為<component>__<parameter>,因此可以更新巢狀物件的每個元件。- 參數:
- **params字典
估計器參數。
- 回傳:
- self估計器實例
估計器實例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') TunedThresholdClassifierCV[原始碼]#
請求傳遞給
score方法的中繼資料。請注意,此方法僅在
enable_metadata_routing=True時才相關(請參閱sklearn.set_config)。請參閱 使用者指南,了解路由機制如何運作。每個參數的選項為
True:請求中繼資料,並在提供時傳遞給score。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,並且元估計器不會將其傳遞給score。None:不請求中繼資料,如果使用者提供中繼資料,元估計器會引發錯誤。str:元數據應使用此給定的別名,而不是原始名稱傳遞給元估計器。
預設值(
sklearn.utils.metadata_routing.UNCHANGED)會保留現有的請求。這允許您更改某些參數的請求,而其他參數則不更改。於 1.3 版本新增。
注意
僅當此估計器被用作元估計器的子估計器時,例如在
Pipeline內部使用時,此方法才相關。否則它不會產生任何效果。- 參數:
- sample_weightstr、True、False 或 None,預設值 = sklearn.utils.metadata_routing.UNCHANGED
用於
score中sample_weight參數的元數據路由。
- 回傳:
- self物件
更新後的物件。