AgglomerativeClustering#
- class sklearn.cluster.AgglomerativeClustering(n_clusters=2, *, metric='euclidean', memory=None, connectivity=None, compute_full_tree='auto', linkage='ward', distance_threshold=None, compute_distances=False)[原始碼]#
聚合式分群。
遞迴合併樣本資料的成對叢集;使用連結距離。
詳情請參閱使用者指南。
- 參數:
- n_clustersint 或 None,預設值=2
要尋找的叢集數量。如果
distance_threshold不是None,則必須為None。- metricstr 或可呼叫對象,預設值="euclidean"
用於計算連結的度量。可以是「euclidean」、「l1」、「l2」、「manhattan」、「cosine」或「precomputed」。如果連結是「ward」,則只接受「euclidean」。如果為「precomputed」,則需要一個距離矩陣作為 fit 方法的輸入。如果連通性為 None,連結為「single」且親和力不是「precomputed」,則可以指定任何有效的成對距離度量。
在 1.2 版本中新增。
- memorystr 或具有 joblib.Memory 介面的物件,預設值=None
用於快取樹狀結構計算的輸出。預設情況下,不進行快取。如果給定一個字串,則它是快取目錄的路徑。
- connectivity類似陣列、稀疏矩陣或可呼叫對象,預設值=None
連通性矩陣。為每個樣本定義遵循給定資料結構的相鄰樣本。它可以是連通性矩陣本身,也可以是將資料轉換為連通性矩陣的可呼叫對象,例如從
kneighbors_graph衍生而來。預設值為None,即,階層式分群演算法是非結構化的。有關使用
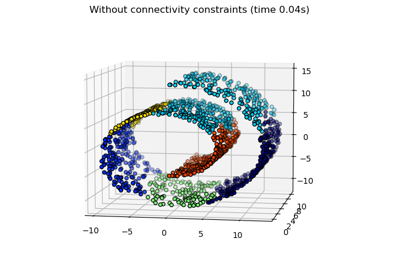
kneighbors_graph的連通性矩陣範例,請參閱 有結構和無結構的聚合式分群。- compute_full_tree「auto」或 bool,預設值='auto'
在
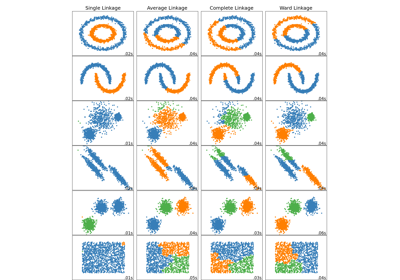
n_clusters時提早停止樹狀結構的建構。如果叢集數量與樣本數量相比不大,這有助於減少計算時間。只有在指定連通性矩陣時,此選項才有用。另請注意,當變更叢集數量並使用快取時,計算完整樹狀結構可能是有利的。如果distance_threshold不是None,則必須為True。預設情況下,compute_full_tree為「auto」,當distance_threshold不是None或n_clusters小於 100 或0.02 * n_samples的最大值時,其等於True。否則,「auto」等同於False。- linkage{‘ward’、‘complete’、‘average’、‘single’},預設值='ward'
要使用的連結準則。連結準則決定在觀察集之間使用哪個距離。該演算法將合併使此準則最小化的成對叢集。
「ward」使正在合併的叢集的變異數最小化。
「average」使用兩個集合中每個觀察值的平均距離。
「complete」或「maximum」連結使用兩個集合中所有觀察值之間的最大距離。
「single」使用兩個集合中所有觀察值之間的最小距離。
在 0.20 版本中新增:新增了「single」選項
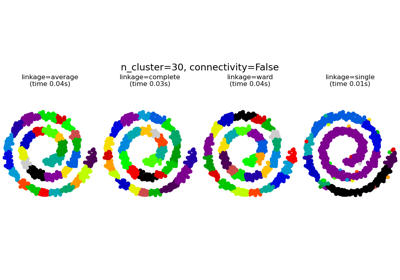
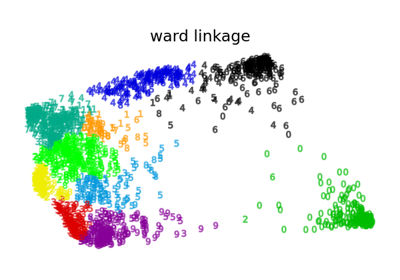
有關比較不同
linkage準則的範例,請參閱 在玩具資料集上比較不同的階層式連結方法。- distance_thresholdfloat,預設值=None
連結距離閾值,在此閾值或以上的叢集將不會合併。如果不是
None,則n_clusters必須為None,而compute_full_tree必須為True。在 0.21 版本中新增。
- compute_distancesbool,預設值=False
即使未使用
distance_threshold,也會計算叢集之間的距離。這可用於製作樹狀圖視覺化,但會引入計算和記憶體額外負荷。在 0.24 版本中新增。
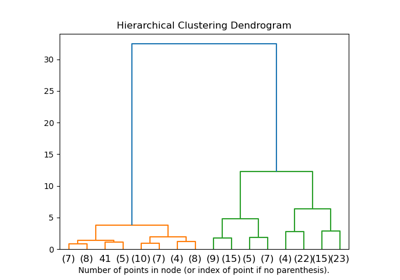
有關樹狀圖視覺化的範例,請參閱 繪製階層式分群樹狀圖。
- 屬性:
- n_clusters_int
演算法找到的叢集數量。如果
distance_threshold=None,它將等於給定的n_clusters。- labels_形狀為 (n_samples) 的 ndarray
每個點的叢集標籤。
- n_leaves_int
階層式樹狀結構中的葉子數量。
- n_connected_components_int
圖形中連通元件的估計數量。
在 0.21 版本中新增:
n_connected_components_的新增是為了取代n_components_。- n_features_in_int
在fit期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在fit期間看到的特徵名稱。僅當
X具有所有都是字串的特徵名稱時才定義。在 1.0 版本中新增。
- children_形狀為 (n_samples-1, 2) 的類似陣列
每個非葉節點的子節點。小於
n_samples的值對應於樹狀結構的葉子,這些葉子是原始樣本。大於或等於n_samples的節點i是非葉節點,並且具有子節點children_[i - n_samples]。或者,在第 i 次迭代中,合併 children[i][0] 和 children[i][1] 以形成節點n_samples + i。- distances_形狀為 (n_nodes-1,) 的類似陣列
children_中相應位置的節點之間的距離。僅當使用distance_threshold或compute_distances設定為True時才計算。
另請參閱
FeatureAgglomerationward_tree聚合式分群,但針對特徵而不是樣本。
範例
>>> from sklearn.cluster import AgglomerativeClustering >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [4, 2], [4, 4], [4, 0]]) >>> clustering = AgglomerativeClustering().fit(X) >>> clustering AgglomerativeClustering() >>> clustering.labels_ array([1, 1, 1, 0, 0, 0])
- fit(X, y=None)[原始碼]#
從特徵或距離矩陣擬合階層式分群。
- 參數:
- X類陣列 (array-like),形狀為 (n_samples, n_features) 或 (n_samples, n_samples)
用於分群的訓練實例,如果
metric='precomputed'則為實例之間的距離。- y忽略
未使用,此處僅為 API 一致性而存在。
- 回傳值:
- self物件
回傳已擬合的實例。
- fit_predict(X, y=None)[原始碼]#
擬合並回傳每個樣本的分群分配結果。
除了擬合之外,此方法也會回傳訓練集中每個樣本的分群分配結果。
- 參數:
- X形狀為 (n_samples, n_features) 或 (n_samples, n_samples) 的類陣列 (array-like)
用於分群的訓練實例,如果
affinity='precomputed'則為實例之間的距離。- y忽略
未使用,此處僅為 API 一致性而存在。
- 回傳值:
- labels形狀為 (n_samples,) 的 ndarray
分群標籤。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看 使用者指南 以了解路由機制如何運作。
- 回傳值:
- routingMetadataRequest
一個封裝路由資訊的
MetadataRequest。