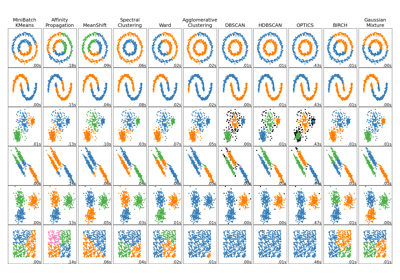
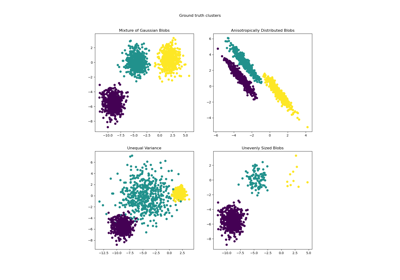
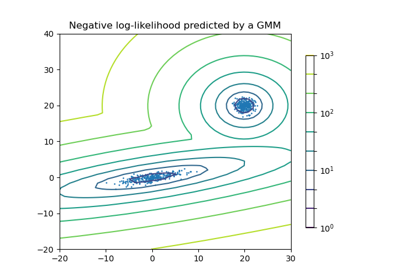
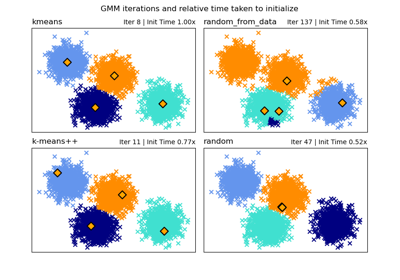
高斯混合模型#
- class sklearn.mixture.GaussianMixture(n_components=1, *, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)[source]#
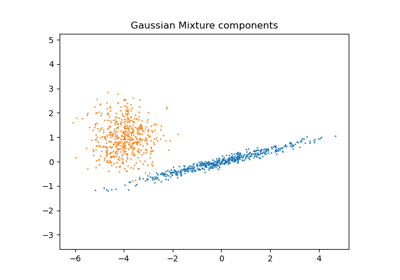
高斯混合模型。
高斯混合模型機率分佈的表示。此類別允許估計高斯混合分佈的參數。
請在使用者指南中閱讀更多資訊。
在 0.18 版本中新增。
- 參數:
- n_componentsint,預設值=1
混合成分的數量。
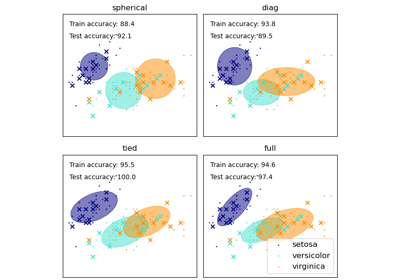
- covariance_type{‘full’, ‘tied’, ‘diag’, ‘spherical’},預設值=’full’
描述要使用之共變異數參數類型的字串。必須為以下其中之一
‘full’:每個成分都有其自己的通用共變異數矩陣。
‘tied’:所有成分共享相同的通用共變異數矩陣。
‘diag’:每個成分都有其自己的對角共變異數矩陣。
‘spherical’:每個成分都有其自己的單一變異數。
- tolfloat,預設值=1e-3
收斂閾值。當下限平均增益低於此閾值時,EM 迭代將停止。
- reg_covarfloat,預設值=1e-6
加入共變異數對角線的非負正規化。允許確保共變異數矩陣都是正數。
- max_iterint,預設值=100
要執行的 EM 迭代次數。
- n_initint,預設值=1
要執行的初始化次數。會保留最佳結果。
- init_params{‘kmeans’, ‘k-means++’, ‘random’, ‘random_from_data’},預設值=’kmeans’
用於初始化權重、均值和精度的演算法。字串必須為以下其中之一
‘kmeans’:使用 kmeans 初始化責任。
‘k-means++’:使用 k-means++ 方法初始化。
‘random’:隨機初始化責任。
‘random_from_data’:初始均值為隨機選取的資料點。
在 v1.1 版本中變更:
init_params現在接受 ‘random_from_data’ 和 ‘k-means++’ 作為初始化方法。- weights_init形狀為 (n_components, ) 的類陣列,預設值=None
使用者提供的初始權重。如果為 None,則會使用
init_params方法初始化權重。- means_init形狀為 (n_components, n_features) 的類陣列,預設值=None
使用者提供的初始均值。如果為 None,則會使用
init_params方法初始化均值。- precisions_init類陣列,預設值=None
使用者提供的初始精度(共變異數矩陣的倒數)。如果為 None,則會使用 'init_params' 方法初始化精度。形狀取決於 'covariance_type'
(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- random_stateint、RandomState 實例或 None,預設值=None
控制提供給選擇用於初始化參數的方法的隨機種子(請參閱
init_params)。此外,它還控制從擬合分佈產生隨機樣本(請參閱方法sample)。傳遞一個 int 以在多個函式呼叫中產生可重複的輸出。請參閱詞彙表。- warm_startbool,預設值=False
如果 'warm_start' 為 True,則最後一次擬合的解會用作下次呼叫 fit() 的初始化。當在類似問題上多次呼叫 fit 時,這可以加速收斂。在這種情況下,會忽略 'n_init',並且只會在第一次呼叫時進行單一初始化。請參閱詞彙表。
- verboseint,預設值=0
啟用詳細輸出。如果為 1,則會列印目前的初始化和每個迭代步驟。如果大於 1,則還會列印每個步驟所需的對數機率和時間。
- verbose_intervalint,預設值=10
在下次列印之前完成的迭代次數。
- 屬性:
- weights_形狀為 (n_components,) 的類陣列
每個混合成分的權重。
- means_形狀為 (n_components, n_features) 的類陣列
每個混合成分的均值。
- covariances_類陣列
每個混合成分的共變異數。形狀取決於
covariance_type(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_類陣列
混合中每個成分的精度矩陣。精度矩陣是共變異數矩陣的倒數。共變異數矩陣是對稱正定,因此高斯混合可以透過精度矩陣等效參數化。與共變異數矩陣相比,儲存精度矩陣在測試時計算新樣本的對數概似值會更有效率。形狀取決於
covariance_type(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_cholesky_類陣列
每個混合成分的精確度矩陣的 Cholesky 分解。精確度矩陣是共變異數矩陣的反矩陣。共變異數矩陣是對稱正定矩陣,因此高斯混合模型可以等效地由精確度矩陣參數化。儲存精確度矩陣而非共變異數矩陣,可以更有效地計算測試時新樣本的對數似然率。形狀取決於
covariance_type。(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- converged_bool
當 EM 最佳擬合達到收斂時為 True,否則為 False。
- n_iter_int
EM 最佳擬合達到收斂所使用的步驟數。
- lower_bound_float
EM 最佳擬合的對數似然率(相對於模型的訓練數據)的下限值。
- n_features_in_int
在 fit 期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有全部為字串的特徵名稱時定義。在 1.0 版本中新增。
另請參閱
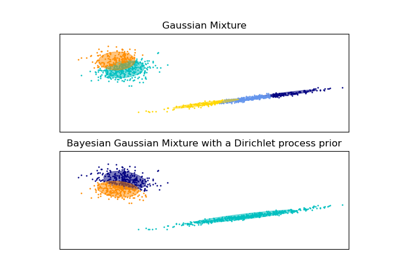
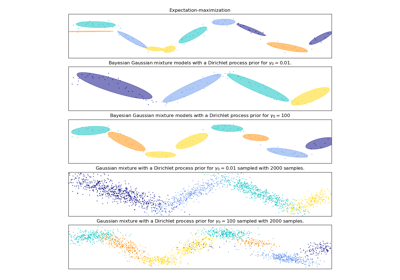
貝氏高斯混合模型使用變分推論擬合高斯混合模型。
範例
>>> import numpy as np >>> from sklearn.mixture import GaussianMixture >>> X = np.array([[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]]) >>> gm = GaussianMixture(n_components=2, random_state=0).fit(X) >>> gm.means_ array([[10., 2.], [ 1., 2.]]) >>> gm.predict([[0, 0], [12, 3]]) array([1, 0])
- aic(X)[原始碼]#
輸入 X 上當前模型的 Akaike 資訊準則。
您可以參考此數學章節,了解有關所使用 AIC 公式化的更多詳細資訊。
- 參數:
- X形狀為 (n_samples, n_dimensions) 的陣列
輸入樣本。
- 返回:
- aicfloat
越低越好。
- bic(X)[原始碼]#
輸入 X 上當前模型的貝氏資訊準則。
您可以參考此數學章節,了解有關所使用 BIC 公式化的更多詳細資訊。
- 參數:
- X形狀為 (n_samples, n_dimensions) 的陣列
輸入樣本。
- 返回:
- bicfloat
越低越好。
- fit(X, y=None)[原始碼]#
使用 EM 演算法估計模型參數。
此方法將模型擬合
n_init次,並設定使模型具有最大似然率或下限的參數。在每次試驗中,該方法會在 E 步驟和 M 步驟之間迭代max_iter次,直到似然率或下限的變化小於tol,否則會引發ConvergenceWarning。如果warm_start為True,則會忽略n_init,並且在第一次呼叫時執行單一初始化。在連續呼叫時,訓練會從上次中斷的地方開始。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
n_features 維資料點的列表。每一列對應一個單一資料點。
- y已忽略
不使用,為了 API 一致性而依照慣例存在。
- 返回:
- self物件
擬合的混合模型。
- fit_predict(X, y=None)[原始碼]#
使用 X 估計模型參數並預測 X 的標籤。
此方法將模型擬合 n_init 次,並設定使模型具有最大似然率或下限的參數。在每次試驗中,該方法會在 E 步驟和 M 步驟之間迭代
max_iter次,直到似然率或下限的變化小於tol,否則會引發ConvergenceWarning。擬合後,它會預測輸入資料點最可能的標籤。在 0.20 版本中新增。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
n_features 維資料點的列表。每一列對應一個單一資料點。
- y已忽略
不使用,為了 API 一致性而依照慣例存在。
- 返回:
- labels形狀為 (n_samples,) 的陣列
成分標籤。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,了解路由機制如何運作。
- 返回:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
若為 True,將會回傳此估算器及其包含的子物件(亦為估算器)的參數。
- 返回:
- paramsdict
參數名稱對應到其值的字典。
- predict(X)[原始碼]#
使用訓練好的模型預測 X 中資料樣本的標籤。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
n_features 維資料點的列表。每一列對應一個單一資料點。
- 返回:
- labels形狀為 (n_samples,) 的陣列
成分標籤。
- predict_proba(X)[原始碼]#
評估每個樣本的成分密度。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
n_features 維資料點的列表。每一列對應一個單一資料點。
- 返回:
- resp陣列,形狀為 (n_samples, n_components)
X 中每個樣本的每個高斯成分的密度。
- sample(n_samples=1)[原始碼]#
從已擬合的高斯分布中生成隨機樣本。
- 參數:
- n_samplesint,預設值為 1
要生成的樣本數。
- 返回:
- X陣列,形狀為 (n_samples, n_features)
隨機生成的樣本。
- y陣列,形狀為 (nsamples,)
成分標籤。
- score(X, y=None)[原始碼]#
計算給定資料 X 的每個樣本平均對數似然率。
- 參數:
- X類陣列,形狀為 (n_samples, n_dimensions)
n_features 維資料點的列表。每一列對應一個單一資料點。
- y已忽略
不使用,為了 API 一致性而依照慣例存在。
- 返回:
- log_likelihoodfloat
高斯混合模型下
X的對數似然率。