注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
高斯混合模型正弦曲線#
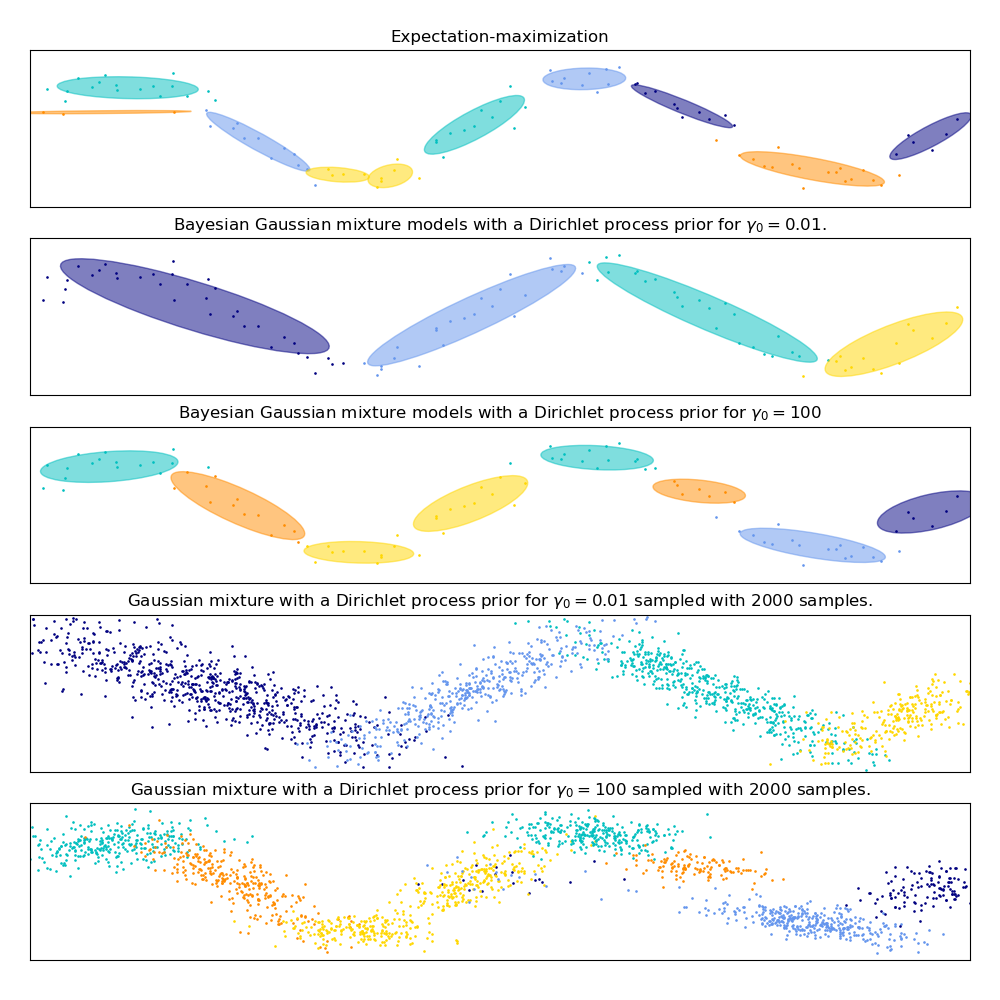
此範例示範了高斯混合模型在非從高斯隨機變數混合取樣的資料上擬合的行為。該資料集由 100 個鬆散間隔的點組成,這些點跟隨一條雜訊正弦曲線。因此,高斯分量數沒有基本真值。
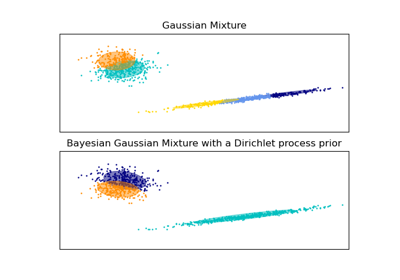
第一個模型是一個具有 10 個分量的經典高斯混合模型,使用期望最大化演算法擬合。
第二個模型是一個具有狄利克雷過程先驗的貝氏高斯混合模型,使用變分推論擬合。較低的濃度先驗值使模型偏好較少的活動分量。此模型「決定」將其建模能力集中於資料集結構的整體情況:由非對角共變異數矩陣建模的具有交替方向的點群。這些交替方向大致捕捉了原始正弦訊號的交替性質。
第三個模型也是一個具有狄利克雷過程先驗的貝氏高斯混合模型,但這次濃度先驗的值較高,使得模型有更多的自由來對資料的精細結構進行建模。結果是一個具有較多活動分量的混合,與我們任意決定將分量數固定為 10 的第一個模型類似。
哪個模型是最好的取決於主觀判斷:我們是偏好僅捕捉整體情況的模型來總結和解釋資料的大部分結構,同時忽略細節,還是我們更喜歡緊密跟隨訊號高密度區域的模型?
最後兩個面板顯示了我們如何從最後兩個模型中取樣。產生的樣本分佈看起來與原始資料分佈不完全相同。差異主要來自我們使用假設資料是由有限數量的分量高斯分量而不是連續雜訊正弦曲線產生的模型所犯的近似誤差。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import itertools
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
from scipy import linalg
from sklearn import mixture
color_iter = itertools.cycle(["navy", "c", "cornflowerblue", "gold", "darkorange"])
def plot_results(X, Y, means, covariances, index, title):
splot = plt.subplot(5, 1, 1 + index)
for i, (mean, covar, color) in enumerate(zip(means, covariances, color_iter)):
v, w = linalg.eigh(covar)
v = 2.0 * np.sqrt(2.0) * np.sqrt(v)
u = w[0] / linalg.norm(w[0])
# as the DP will not use every component it has access to
# unless it needs it, we shouldn't plot the redundant
# components.
if not np.any(Y == i):
continue
plt.scatter(X[Y == i, 0], X[Y == i, 1], 0.8, color=color)
# Plot an ellipse to show the Gaussian component
angle = np.arctan(u[1] / u[0])
angle = 180.0 * angle / np.pi # convert to degrees
ell = mpl.patches.Ellipse(mean, v[0], v[1], angle=180.0 + angle, color=color)
ell.set_clip_box(splot.bbox)
ell.set_alpha(0.5)
splot.add_artist(ell)
plt.xlim(-6.0, 4.0 * np.pi - 6.0)
plt.ylim(-5.0, 5.0)
plt.title(title)
plt.xticks(())
plt.yticks(())
def plot_samples(X, Y, n_components, index, title):
plt.subplot(5, 1, 4 + index)
for i, color in zip(range(n_components), color_iter):
# as the DP will not use every component it has access to
# unless it needs it, we shouldn't plot the redundant
# components.
if not np.any(Y == i):
continue
plt.scatter(X[Y == i, 0], X[Y == i, 1], 0.8, color=color)
plt.xlim(-6.0, 4.0 * np.pi - 6.0)
plt.ylim(-5.0, 5.0)
plt.title(title)
plt.xticks(())
plt.yticks(())
# Parameters
n_samples = 100
# Generate random sample following a sine curve
np.random.seed(0)
X = np.zeros((n_samples, 2))
step = 4.0 * np.pi / n_samples
for i in range(X.shape[0]):
x = i * step - 6.0
X[i, 0] = x + np.random.normal(0, 0.1)
X[i, 1] = 3.0 * (np.sin(x) + np.random.normal(0, 0.2))
plt.figure(figsize=(10, 10))
plt.subplots_adjust(
bottom=0.04, top=0.95, hspace=0.2, wspace=0.05, left=0.03, right=0.97
)
# Fit a Gaussian mixture with EM using ten components
gmm = mixture.GaussianMixture(
n_components=10, covariance_type="full", max_iter=100
).fit(X)
plot_results(
X, gmm.predict(X), gmm.means_, gmm.covariances_, 0, "Expectation-maximization"
)
dpgmm = mixture.BayesianGaussianMixture(
n_components=10,
covariance_type="full",
weight_concentration_prior=1e-2,
weight_concentration_prior_type="dirichlet_process",
mean_precision_prior=1e-2,
covariance_prior=1e0 * np.eye(2),
init_params="random",
max_iter=100,
random_state=2,
).fit(X)
plot_results(
X,
dpgmm.predict(X),
dpgmm.means_,
dpgmm.covariances_,
1,
"Bayesian Gaussian mixture models with a Dirichlet process prior "
r"for $\gamma_0=0.01$.",
)
X_s, y_s = dpgmm.sample(n_samples=2000)
plot_samples(
X_s,
y_s,
dpgmm.n_components,
0,
"Gaussian mixture with a Dirichlet process prior "
r"for $\gamma_0=0.01$ sampled with $2000$ samples.",
)
dpgmm = mixture.BayesianGaussianMixture(
n_components=10,
covariance_type="full",
weight_concentration_prior=1e2,
weight_concentration_prior_type="dirichlet_process",
mean_precision_prior=1e-2,
covariance_prior=1e0 * np.eye(2),
init_params="kmeans",
max_iter=100,
random_state=2,
).fit(X)
plot_results(
X,
dpgmm.predict(X),
dpgmm.means_,
dpgmm.covariances_,
2,
"Bayesian Gaussian mixture models with a Dirichlet process prior "
r"for $\gamma_0=100$",
)
X_s, y_s = dpgmm.sample(n_samples=2000)
plot_samples(
X_s,
y_s,
dpgmm.n_components,
1,
"Gaussian mixture with a Dirichlet process prior "
r"for $\gamma_0=100$ sampled with $2000$ samples.",
)
plt.show()
腳本總執行時間:(0 分鐘 0.480 秒)
相關範例