貝氏高斯混合模型#
- class sklearn.mixture.BayesianGaussianMixture(*, n_components=1, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weight_concentration_prior_type='dirichlet_process', weight_concentration_prior=None, mean_precision_prior=None, mean_prior=None, degrees_of_freedom_prior=None, covariance_prior=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)[原始碼]#
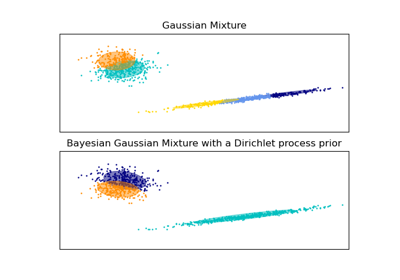
高斯混合的變分貝氏估計。
此類別允許推斷高斯混合分佈參數的近似後驗分佈。可以從數據中推斷出有效成分的數量。
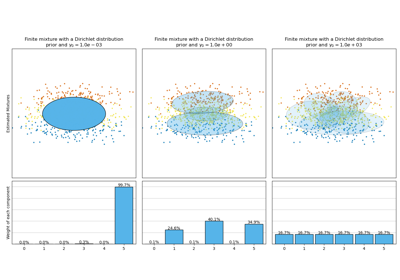
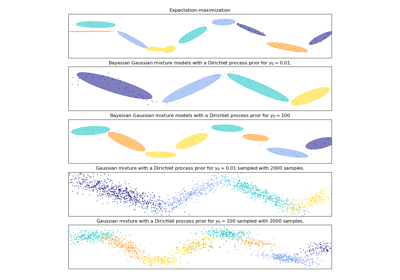
此類別針對權重分佈實作了兩種先驗類型:具有狄利克雷分佈的有限混合模型和具有狄利克雷過程的無限混合模型。在實務上,狄利克雷過程推論演算法是近似的,並且使用具有固定最大成分數的截斷分佈(稱為「斷棍表示法」)。實際使用的成分數幾乎總是取決於數據。
在 0.18 版本中新增。
請參閱 使用者指南以了解更多資訊。
- 參數:
- n_componentsint,預設值為 1
混合成分的數量。根據數據和
weight_concentration_prior的值,模型可以決定不使用所有成分,方法是將某些成分的weights_設定為非常接近零的值。因此,有效成分的數量小於 n_components。- covariance_type{‘full’, ‘tied’, ‘diag’, ‘spherical’},預設值為 ‘full’
描述要使用之共變異數參數類型的字串。必須是以下其中一個:
‘full’ (每個成分都有自己的通用共變異數矩陣),
‘tied’ (所有成分共用相同的通用共變異數矩陣),
‘diag’ (每個成分都有自己的對角共變異數矩陣),
‘spherical’ (每個成分都有自己的單一共變異數)。
- tolfloat,預設值為 1e-3
收斂閾值。當對數似然的下限平均增益(相對於模型的訓練數據)低於此閾值時,EM 迭代將停止。
- reg_covarfloat,預設值為 1e-6
新增至共變異數對角線的非負規則化。可確保共變異數矩陣都是正的。
- max_iterint,預設值為 100
要執行的 EM 迭代次數。
- n_initint,預設值為 1
要執行的初始化次數。保留對數似然下限值最高的結果。
- init_params{‘kmeans’, ‘k-means++’, ‘random’, ‘random_from_data’},預設值為 ‘kmeans’
用於初始化權重、均值和共變異數的方法。字串必須是以下其中一個:
‘kmeans’:使用 k-means 初始化責任。
‘k-means++’:使用 k-means++ 方法初始化。
‘random’:隨機初始化責任。
‘random_from_data’:隨機選取初始均值為資料點。
在 v1.1 版本中變更:
init_params現在接受 ‘random_from_data’ 和 ‘k-means++’ 作為初始化方法。- weight_concentration_prior_type{‘dirichlet_process’, ‘dirichlet_distribution’},預設值為 ‘dirichlet_process’
描述權重濃度先驗類型的字串。
- weight_concentration_priorfloat 或 None,預設值為 None
每個成分在權重分佈 (狄利克雷) 上的狄利克雷濃度。這在文獻中通常稱為 gamma。較高的濃度將更多質量放在中心,並會導致更多成分處於活動狀態,而較低的濃度參數將會導致更多質量位於混合權重單純形的邊緣。參數值必須大於 0。如果為 None,則將其設定為
1. / n_components。- mean_precision_priorfloat 或 None,預設值為 None
平均值分佈 (高斯分佈) 的精確度先驗。控制平均值可以放置的範圍。數值越大,叢集平均值會越集中在
mean_prior附近。參數值必須大於 0。如果為 None,則設定為 1。- mean_prior類陣列 (array-like),形狀 (n_features,),預設值為 None
平均值分佈 (高斯分佈) 的先驗。如果為 None,則設定為 X 的平均值。
- degrees_of_freedom_prior浮點數或 None,預設值為 None
共變異數分佈 (Wishart 分佈) 的自由度數目的先驗。如果為 None,則設定為
n_features。- covariance_prior浮點數或類陣列,預設值為 None
共變異數分佈 (Wishart 分佈) 的先驗。如果為 None,則使用 X 的共變異數初始化經驗共變異數先驗。形狀取決於
covariance_type(n_features, n_features) if 'full', (n_features, n_features) if 'tied', (n_features) if 'diag', float if 'spherical'
- random_state整數、RandomState 實例或 None,預設值為 None
控制用於初始化參數的方法的隨機種子 (請參閱
init_params)。此外,它還控制從擬合分佈生成隨機樣本 (請參閱sample方法)。傳遞一個整數,以便在多個函數呼叫中產生可重複的輸出。請參閱 詞彙表。- warm_start布林值,預設值為 False
如果 'warm_start' 為 True,則上次擬合的解將用作下次呼叫 fit() 的初始化。當對類似問題多次呼叫 fit 時,這可以加快收斂速度。請參閱 詞彙表。
- verbose整數,預設值為 0
啟用詳細輸出。如果為 1,則會列印目前的初始化和每個迭代步驟。如果大於 1,則還會列印每個步驟的對數機率和所需時間。
- verbose_interval整數,預設值為 10
下次列印前完成的迭代次數。
- 屬性:
- weights_類陣列,形狀 (n_components,)
每個混合成分的權重。
- means_類陣列,形狀 (n_components, n_features)
每個混合成分的平均值。
- covariances_類陣列
每個混合成分的共變異數。形狀取決於
covariance_type(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_類陣列
混合中每個成分的精確度矩陣。精確度矩陣是共變異數矩陣的反矩陣。共變異數矩陣是對稱正定矩陣,因此高斯混合可以等效地由精確度矩陣參數化。與共變異數矩陣相比,儲存精確度矩陣可以更有效地計算測試時新樣本的對數概似度。形狀取決於
covariance_type(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- precisions_cholesky_類陣列
每個混合成分的精確度矩陣的 Cholesky 分解。精確度矩陣是共變異數矩陣的反矩陣。共變異數矩陣是對稱正定矩陣,因此高斯混合可以等效地由精確度矩陣參數化。與共變異數矩陣相比,儲存精確度矩陣可以更有效地計算測試時新樣本的對數概似度。形狀取決於
covariance_type(n_components,) if 'spherical', (n_features, n_features) if 'tied', (n_components, n_features) if 'diag', (n_components, n_features, n_features) if 'full'
- converged_布林值
當達到最佳擬合的推論收斂時為 True,否則為 False。
- n_iter_整數
最佳擬合的推論達到收斂所使用的步驟數。
- lower_bound_浮點數
最佳擬合的推論模型證據 (訓練資料) 的下限值。
- weight_concentration_prior_元組或浮點數
權重分佈 (Dirichlet 分佈) 上每個成分的 Dirichlet 集中度。類型取決於
weight_concentration_prior_type(float, float) if 'dirichlet_process' (Beta parameters), float if 'dirichlet_distribution' (Dirichlet parameters).
較高的集中度會將更多質量放在中心,並會導致更多成分處於活動狀態,而較低的集中度參數會將更多質量放在單純形的邊緣。
- weight_concentration_類陣列,形狀 (n_components,)
權重分佈 (Dirichlet 分佈) 上每個成分的 Dirichlet 集中度。
- mean_precision_prior_浮點數
平均值分佈 (高斯分佈) 的精確度先驗。控制平均值可以放置的範圍。數值越大,叢集平均值會越集中在
mean_prior附近。如果 mean_precision_prior 設定為 None,則mean_precision_prior_設定為 1。- mean_precision_類陣列,形狀 (n_components,)
每個成分在平均值分佈 (高斯分佈) 上的精確度。
- mean_prior_類陣列,形狀 (n_features,)
平均值分佈 (高斯分佈) 的先驗。
- degrees_of_freedom_prior_浮點數
共變異數分佈 (Wishart 分佈) 的自由度數目的先驗。
- degrees_of_freedom_類陣列,形狀 (n_components,)
模型中每個成分的自由度數目。
- covariance_prior_浮點數或類陣列
共變異數分佈 (Wishart 分佈) 的先驗。形狀取決於
covariance_type(n_features, n_features) if 'full', (n_features, n_features) if 'tied', (n_features) if 'diag', float if 'spherical'
- n_features_in_整數
在 fit 期間看到的特徵數量。
在 0.24 版中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X的特徵名稱都是字串時才定義。在 1.0 版中新增。
另請參閱
GaussianMixture使用 EM 的有限高斯混合擬合。
參考文獻
範例
>>> import numpy as np >>> from sklearn.mixture import BayesianGaussianMixture >>> X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [12, 4], [10, 7]]) >>> bgm = BayesianGaussianMixture(n_components=2, random_state=42).fit(X) >>> bgm.means_ array([[2.49... , 2.29...], [8.45..., 4.52... ]]) >>> bgm.predict([[0, 0], [9, 3]]) array([0, 1])
- fit(X, y=None)[原始碼]#
使用 EM 演算法估計模型參數。
此方法會擬合模型
n_init次,並設定模型具有最大概似度或下限的參數。在每次試驗中,此方法會在 E 步驟和 M 步驟之間迭代max_iter次,直到概似度或下限的變化小於tol,否則會引發ConvergenceWarning。如果warm_start為True,則會忽略n_init,並且在第一次呼叫時會執行單一初始化。在連續呼叫時,訓練會從上次停止的地方開始。- 參數:
- X類陣列,形狀 (n_samples, n_features)
n_features 維資料點的清單。每一列對應一個資料點。
- y已忽略
未使用,依慣例為了 API 一致性而存在。
- 傳回值:
- self物件
擬合的混合。
- fit_predict(X, y=None)[原始碼]#
使用 X 估計模型參數並預測 X 的標籤。
此方法會擬合模型 n_init 次,並設定模型具有最大概似度或下限的參數。在每次試驗中,此方法會在 E 步驟和 M 步驟之間迭代
max_iter次,直到概似度或下限的變化小於tol,否則會引發ConvergenceWarning。擬合後,它會預測輸入資料點最可能的標籤。在 0.20 版中新增。
- 參數:
- X類陣列,形狀 (n_samples, n_features)
n_features 維資料點的清單。每一列對應一個資料點。
- y已忽略
未使用,依慣例為了 API 一致性而存在。
- 傳回值:
- labels陣列,形狀 (n_samples,)
成分標籤。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,了解路由機制如何運作。
- 傳回值:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值=True
若為 True,將會回傳此估算器以及所包含的、為估算器的子物件之參數。
- 傳回值:
- paramsdict
參數名稱對應到其值的字典。
- predict(X)[原始碼]#
使用訓練好的模型預測 X 中資料樣本的標籤。
- 參數:
- X類陣列,形狀 (n_samples, n_features)
n_features 維資料點的清單。每一列對應一個資料點。
- 傳回值:
- labels陣列,形狀 (n_samples,)
成分標籤。
- predict_proba(X)[原始碼]#
評估每個樣本的成分密度。
- 參數:
- X類陣列,形狀 (n_samples, n_features)
n_features 維資料點的清單。每一列對應一個資料點。
- 傳回值:
- resp陣列,形狀 (n_samples, n_components)
X 中每個樣本的每個高斯成分密度。
- sample(n_samples=1)[原始碼]#
從擬合的高斯分佈中產生隨機樣本。
- 參數:
- n_samples整數,預設值=1
要產生的樣本數。
- 傳回值:
- X陣列,形狀 (n_samples, n_features)
隨機產生的樣本。
- y陣列,形狀 (nsamples,)
成分標籤。
- score(X, y=None)[原始碼]#
計算給定資料 X 的每個樣本的平均對數似然率。
- 參數:
- X類陣列,形狀 (n_samples, n_dimensions)
n_features 維資料點的清單。每一列對應一個資料點。
- y已忽略
未使用,依慣例為了 API 一致性而存在。
- 傳回值:
- log_likelihood浮點數
X在高斯混合模型下的對數似然率。