線性判別分析#
- class sklearn.discriminant_analysis.LinearDiscriminantAnalysis(solver='svd', shrinkage=None, priors=None, n_components=None, store_covariance=False, tol=0.0001, covariance_estimator=None)[原始碼]#
線性判別分析。
一種具有線性決策邊界的分類器,通過將類別條件密度擬合到資料並使用貝氏規則產生。
該模型將高斯密度擬合到每個類別,假設所有類別共享相同的共變異數矩陣。
擬合的模型也可以用於通過將其投影到最具判別性的方向來減少輸入的維度,使用
transform方法。在版本 0.17 中新增。
有關
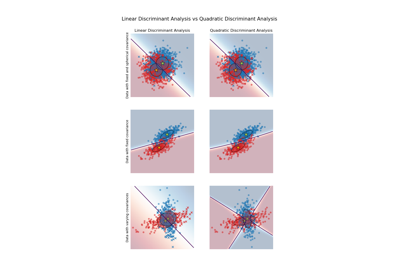
LinearDiscriminantAnalysis和QuadraticDiscriminantAnalysis之間的比較,請參閱 具有共變異數橢圓的線性判別分析和二次判別分析。請在 使用者指南 中閱讀更多資訊。
- 參數:
- solver{‘svd’, ‘lsqr’, ‘eigen’}, default=’svd’
- 要使用的求解器,可能的值
‘svd’:奇異值分解(預設)。不計算共變異數矩陣,因此建議對具有大量特徵的資料使用此求解器。
‘lsqr’:最小平方解。可以與收縮或自訂共變異數估計器組合使用。
‘eigen’:特徵值分解。可以與收縮或自訂共變異數估計器組合使用。
在版本 1.2 中變更:
solver="svd"現在具有實驗性的 Array API 支援。請參閱 Array API 使用者指南 以取得更多詳細資訊。- shrinkage‘auto’ 或 float,預設為None
- 收縮參數,可能的值
None:無收縮(預設)。
‘auto’:使用 Ledoit-Wolf 引理自動收縮。
介於 0 和 1 之間的浮點數:固定收縮參數。
如果使用
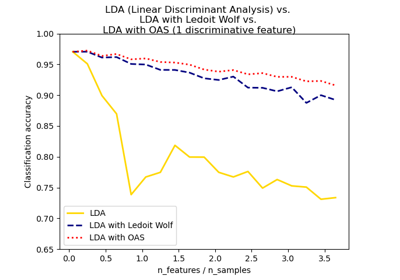
covariance_estimator,則應將其保留為 None。請注意,收縮僅適用於 ‘lsqr’ 和 ‘eigen’ 求解器。有關使用範例,請參閱 用於分類的正規、Ledoit-Wolf 和 OAS 線性判別分析。
- priors形狀為 (n_classes,) 的類似陣列,預設為 None
類別先驗機率。預設情況下,類別比例是從訓練資料中推斷出來的。
- n_componentsint,預設為 None
用於降維的元件數量 (<= min(n_classes - 1, n_features))。如果為 None,則將設定為 min(n_classes - 1, n_features)。此參數僅影響
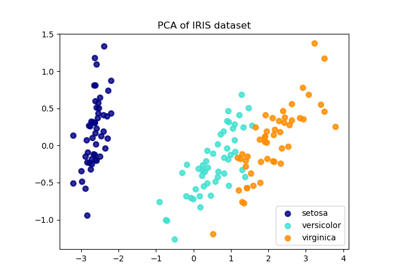
transform方法。有關使用範例,請參閱 鳶尾花資料集的 LDA 和 PCA 2D 投影比較。
- store_covariancebool,預設為 False
如果為 True,則在求解器為 ‘svd’ 時明確計算加權類內共變異數矩陣。對於其他求解器,始終會計算並儲存矩陣。
在版本 0.17 中新增。
- tolfloat,預設為 1.0e-4
X 的奇異值的絕對臨界值,被認為是顯著的,用於估計 X 的等級。丟棄奇異值不明顯的維度。僅在求解器為 ‘svd’ 時使用。
在版本 0.17 中新增。
- covariance_estimator共變異數估計器,預設為 None
如果不是 None,則使用
covariance_estimator來估計共變異數矩陣,而不是依賴經驗共變異數估計器(具有潛在的收縮)。該物件應具有一個擬合方法和一個covariance_屬性,如sklearn.covariance中的估計器。如果為 None,則收縮參數會驅動估計。如果使用
shrinkage,則應將其保留為 None。請注意,covariance_estimator僅適用於 ‘lsqr’ 和 ‘eigen’ 求解器。在版本 0.24 中新增。
- 屬性:
- coef_形狀為 (n_features,) 或 (n_classes, n_features) 的 ndarray
權重向量。
- intercept_形狀為 (n_classes,) 的 ndarray
截距項。
- covariance_形狀為 (n_features, n_features) 的類似陣列
加權類內共變異數矩陣。它對應於
sum_k prior_k * C_k,其中C_k是類別k中樣本的共變異數矩陣。C_k是使用共變異數的(可能已收縮的)偏差估計器估計的。如果求解器為 ‘svd’,則僅當store_covariance為 True 時才存在。- explained_variance_ratio_形狀為 (n_components,) 的 ndarray
每個選定元件說明的變異數百分比。如果未設定
n_components,則會儲存所有元件,且說明變異數的總和等於 1.0。僅在使用 eigen 或 svd 求解器時可用。- means_形狀為 (n_classes, n_features) 的類似陣列
按類別的均值。
- priors_形狀為 (n_classes,) 的類似陣列
類別先驗(總和為 1)。
- scalings_形狀為 (rank, n_classes - 1) 的類似陣列
類別質心所跨越空間中特徵的縮放。僅適用於 ‘svd’ 和 ‘eigen’ 求解器。
- xbar_形狀為 (n_features,) 的類似陣列
總體均值。僅當求解器為 ‘svd’ 時才存在。
- classes_形狀為 (n_classes,) 的類似陣列
唯一類別標籤。
- n_features_in_int
在 fit 期間看到的特徵數量。
在版本 0.24 中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有全部為字串的特徵名稱時才定義。在版本 1.0 中新增。
另請參閱
範例
>>> import numpy as np >>> from sklearn.discriminant_analysis import LinearDiscriminantAnalysis >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = LinearDiscriminantAnalysis() >>> clf.fit(X, y) LinearDiscriminantAnalysis() >>> print(clf.predict([[-0.8, -1]])) [1]
- decision_function(X)[原始碼]#
將決策函數應用於樣本陣列。
決策函數(在一個常數因子內)等於模型的對數後驗機率,即
log p(y = k | x)。在二元分類設定中,這對應於差值log p(y = 1 | x) - log p(y = 0 | x)。請參閱 LDA 和 QDA 分類器的數學公式。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
樣本陣列(測試向量)。
- 回傳:
- y_scores形狀為 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
每個樣本,與每個類別相關的決策函數值。在雙類別的情況下,形狀為
(n_samples,),給出正類別的對數似然比。
- fit(X, y)[原始碼]#
擬合線性判別分析模型。
在 0.19 版本中變更:
store_covariance和tol已移至主要建構函式。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
訓練資料。
- y形狀為 (n_samples,) 的類陣列
目標值。
- 回傳:
- self物件
已擬合的估算器。
- fit_transform(X, y=None, **fit_params)[原始碼]#
擬合資料,然後轉換它。
將轉換器擬合到具有可選參數
fit_params的X和y,並傳回X的轉換版本。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列,預設值為 None
目標值(無監督轉換則為 None)。
- **fit_paramsdict
其他擬合參數。
- 回傳:
- X_new形狀為 (n_samples, n_features_new) 的 ndarray 陣列
已轉換的陣列。
- get_feature_names_out(input_features=None)[原始碼]#
取得轉換的輸出特徵名稱。
輸出特徵名稱將以小寫的類別名稱為前綴。例如,如果轉換器輸出 3 個特徵,則輸出特徵名稱為:
["class_name0", "class_name1", "class_name2"]。- 參數:
- input_featuresstr 或 None 的類陣列,預設值為 None
僅用於驗證特徵名稱是否與
fit中看到的名稱一致。
- 回傳:
- feature_names_outstr 物件的 ndarray
已轉換的特徵名稱。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用手冊,了解路由機制如何運作。
- 回傳:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
如果為 True,將傳回此估算器和包含的子物件(即估算器)的參數。
- 回傳:
- paramsdict
參數名稱對應到其值的字典。
- predict(X)[原始碼]#
預測 X 中樣本的類別標籤。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列, 稀疏矩陣}
我們想要取得預測值的資料矩陣。
- 回傳:
- y_pred形狀為 (n_samples,) 的 ndarray
包含每個樣本的類別標籤的向量。
- predict_log_proba(X)[原始碼]#
估計對數機率。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入資料。
- 回傳:
- C形狀為 (n_samples, n_classes) 的 ndarray
估計的對數機率。
- predict_proba(X)[原始碼]#
估計機率。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入資料。
- 回傳:
- C形狀為 (n_samples, n_classes) 的 ndarray
估計的機率。
- score(X, y, sample_weight=None)[原始碼]#
傳回在給定的測試資料和標籤上的平均準確度。
在多標籤分類中,這是子集準確度,它是一個嚴苛的指標,因為您需要每個樣本正確預測每個標籤集。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
測試樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列
對於
X的真實標籤。- sample_weight形狀為 (n_samples,) 的類陣列,預設值為 None
樣本權重。
- 回傳:
- scorefloat
self.predict(X)相對於y的平均準確度。
- set_output(*, transform=None)[原始碼]#
設定輸出容器。
請參閱 Introducing the set_output API,以取得有關如何使用 API 的範例。
- 參數:
- transform{“default”, “pandas”, “polars”},預設值為 None
設定
transform和fit_transform的輸出。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換配置未變更
在 1.4 版本中新增:新增了
"polars"選項。
- 回傳:
- self估算器執行個體
估算器執行個體。
- set_params(**params)[原始碼]#
設定此估算器的參數。
此方法適用於簡單估算器以及巢狀物件(例如
Pipeline)。後者的參數形式為<component>__<parameter>,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估算器參數。
- 回傳:
- self估算器執行個體
估算器執行個體。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearDiscriminantAnalysis[原始碼]#
請求傳遞給
score方法的中繼資料。請注意,只有在
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱關於路由機制如何運作的 使用者指南。每個參數的選項為
True:請求中繼資料,並在提供時傳遞給score。如果未提供中繼資料,則會忽略該請求。False:不請求中繼資料,且元估計器不會將其傳遞給score。None:不請求中繼資料,如果使用者提供,元估計器將引發錯誤。str:中繼資料應以這個給定的別名而不是原始名稱傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這允許您更改某些參數的請求,而不更改其他參數的請求。於 1.3 版新增。
注意
只有當此估計器被用作元估計器的子估計器時,此方法才相關,例如,在
Pipeline內部使用。否則它沒有效果。- 參數:
- sample_weightstr、True、False 或 None,預設值 = sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight參數的中繼資料路由。
- 回傳:
- self物件
更新後的物件。