注意
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
使用 k-means 對文字文件進行分群#
這是一個範例,說明如何使用 scikit-learn API,透過詞袋方法,按主題對文件進行分群。
示範了兩種演算法,即 KMeans 及其更具可擴展性的變體 MiniBatchKMeans。此外,潛在語義分析用於降低維度並探索資料中的潛在模式。
此範例使用兩種不同的文字向量化器:TfidfVectorizer 和 HashingVectorizer。有關向量化器的詳細資訊及其處理時間的比較,請參閱範例筆記本 FeatureHasher 和 DictVectorizer 比較。
對於透過監督式學習方法進行的文件分析,請參閱範例指令碼 使用稀疏特徵對文字文件進行分類。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
載入文字資料#
我們從 20 個新聞群組文字資料集載入資料,其中包含約 18,000 篇關於 20 個主題的新聞群組文章。為了說明和降低運算成本,我們僅選擇了 4 個主題的子集,約有 3,400 個文件。請參閱範例 使用稀疏特徵對文字文件進行分類,以了解此類主題的重疊情況。
請注意,預設情況下,文字樣本包含一些訊息元資料,例如 "headers"、"footers"(簽名)和 "quotes" 到其他文章。我們使用 fetch_20newsgroups 中的 remove 參數來剝除這些特徵,並擁有更合理的群集問題。
import numpy as np
from sklearn.datasets import fetch_20newsgroups
categories = [
"alt.atheism",
"talk.religion.misc",
"comp.graphics",
"sci.space",
]
dataset = fetch_20newsgroups(
remove=("headers", "footers", "quotes"),
subset="all",
categories=categories,
shuffle=True,
random_state=42,
)
labels = dataset.target
unique_labels, category_sizes = np.unique(labels, return_counts=True)
true_k = unique_labels.shape[0]
print(f"{len(dataset.data)} documents - {true_k} categories")
3387 documents - 4 categories
量化群集結果的品質#
在本節中,我們定義了一個函數,使用多個指標對不同的群集管道進行評分。
群集演算法基本上是非監督式學習方法。但是,由於我們碰巧擁有此特定資料集的類別標籤,因此可以使用利用此「監督式」基本事實資訊的評估指標,來量化產生的群集的品質。此類指標的範例如下
同質性,量化群集中僅包含單一類別成員的程度;
完整性,量化指定類別的成員分配到相同群集的程度;
V 量測,完整性和同質性的調和平均數;
Rand 指數,衡量根據群集演算法的結果和基本事實類別指派,成對的資料點以一致方式分組的頻率;
調整後的 Rand 指數,經機會調整的 Rand 指數,以便隨機群集指派的 ARI 期望值為 0.0。
如果不知道基本事實標籤,則只能使用模型結果本身來執行評估。在這種情況下,輪廓係數會派上用場。有關如何操作的範例,請參閱 使用 KMeans 群集上的輪廓分析選擇群集數量。
如需更多參考,請參閱 群集效能評估。
from collections import defaultdict
from time import time
from sklearn import metrics
evaluations = []
evaluations_std = []
def fit_and_evaluate(km, X, name=None, n_runs=5):
name = km.__class__.__name__ if name is None else name
train_times = []
scores = defaultdict(list)
for seed in range(n_runs):
km.set_params(random_state=seed)
t0 = time()
km.fit(X)
train_times.append(time() - t0)
scores["Homogeneity"].append(metrics.homogeneity_score(labels, km.labels_))
scores["Completeness"].append(metrics.completeness_score(labels, km.labels_))
scores["V-measure"].append(metrics.v_measure_score(labels, km.labels_))
scores["Adjusted Rand-Index"].append(
metrics.adjusted_rand_score(labels, km.labels_)
)
scores["Silhouette Coefficient"].append(
metrics.silhouette_score(X, km.labels_, sample_size=2000)
)
train_times = np.asarray(train_times)
print(f"clustering done in {train_times.mean():.2f} ± {train_times.std():.2f} s ")
evaluation = {
"estimator": name,
"train_time": train_times.mean(),
}
evaluation_std = {
"estimator": name,
"train_time": train_times.std(),
}
for score_name, score_values in scores.items():
mean_score, std_score = np.mean(score_values), np.std(score_values)
print(f"{score_name}: {mean_score:.3f} ± {std_score:.3f}")
evaluation[score_name] = mean_score
evaluation_std[score_name] = std_score
evaluations.append(evaluation)
evaluations_std.append(evaluation_std)
文字特徵上的 K 平均值分群#
此範例中使用了兩種特徵提取方法
TfidfVectorizer使用記憶體中的詞彙(Python 字典)將最常用的單字映射到特徵索引,從而計算單字出現頻率(稀疏)矩陣。然後使用在語料庫中逐個特徵收集的反向文件頻率 (IDF) 向量重新加權單字頻率。HashingVectorizer將單字出現次數雜湊到固定維度空間,可能會發生衝突。然後將單字計數向量歸一化,使每個向量的 l2 範數等於 1(投影到歐幾里得單位球),這對於 k 平均值在高維空間中工作似乎很重要。
此外,可以使用降維來後處理這些提取的特徵。我們將在以下內容中探討這些選擇對群集品質的影響。
使用 TfidfVectorizer 進行特徵提取#
我們首先使用字典向量化器以及 TfidfVectorizer 提供的 IDF 正規化來基準測試估算器。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
max_df=0.5,
min_df=5,
stop_words="english",
)
t0 = time()
X_tfidf = vectorizer.fit_transform(dataset.data)
print(f"vectorization done in {time() - t0:.3f} s")
print(f"n_samples: {X_tfidf.shape[0]}, n_features: {X_tfidf.shape[1]}")
vectorization done in 0.402 s
n_samples: 3387, n_features: 7929
在忽略出現於超過 50% 文件中的詞彙(由 max_df=0.5 設定)以及未在至少 5 份文件中出現的詞彙(由 min_df=5 設定)後,產生的唯一詞彙數量 n_features 約為 8,000 個。我們還可以將 X_tfidf 矩陣的稀疏性量化為非零條目數除以總元素數的比例。
print(f"{X_tfidf.nnz / np.prod(X_tfidf.shape):.3f}")
0.007
我們發現 X_tfidf 矩陣中約有 0.7% 的條目為非零值。
使用 k-means 進行稀疏資料的叢集分析#
由於 KMeans 和 MiniBatchKMeans 都最佳化非凸的目標函數,因此無法保證其叢集分析對於給定的隨機初始化是最佳的。更甚者,對於使用詞袋方法(Bag of Words)向量化的稀疏高維資料(如文字),k-means 可能會在極度隔離的資料點上初始化質心。這些資料點可能會一直保持它們自己的質心。
以下程式碼說明了先前的現象有時會如何導致高度不平衡的叢集,這取決於隨機初始化。
from sklearn.cluster import KMeans
for seed in range(5):
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=1,
random_state=seed,
).fit(X_tfidf)
cluster_ids, cluster_sizes = np.unique(kmeans.labels_, return_counts=True)
print(f"Number of elements assigned to each cluster: {cluster_sizes}")
print()
print(
"True number of documents in each category according to the class labels: "
f"{category_sizes}"
)
Number of elements assigned to each cluster: [ 481 675 1785 446]
Number of elements assigned to each cluster: [1689 638 480 580]
Number of elements assigned to each cluster: [ 1 1 1 3384]
Number of elements assigned to each cluster: [1887 311 332 857]
Number of elements assigned to each cluster: [ 291 673 1771 652]
True number of documents in each category according to the class labels: [799 973 987 628]
為避免這個問題,一種可能的方法是增加獨立隨機初始化的執行次數 n_init。在這種情況下,將選擇慣性(k-means 的目標函數)最佳的叢集分析結果。
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=5,
)
fit_and_evaluate(kmeans, X_tfidf, name="KMeans\non tf-idf vectors")
clustering done in 0.20 ± 0.05 s
Homogeneity: 0.349 ± 0.010
Completeness: 0.398 ± 0.009
V-measure: 0.372 ± 0.009
Adjusted Rand-Index: 0.203 ± 0.017
Silhouette Coefficient: 0.007 ± 0.000
所有這些叢集評估指標的最大值都是 1.0(對於完美的叢集結果)。數值越高越好。調整蘭德指數(Adjusted Rand-Index)接近 0.0 的值對應於隨機標籤。請注意,從上面的分數可以看出,叢集分配確實遠高於隨機水平,但整體品質肯定可以改進。
請記住,類別標籤可能無法準確反映文件主題,因此使用標籤的指標不一定是評估叢集分析管道品質的最佳方法。
使用 LSA 執行降維#
只要先降低向量化空間的維度以使 k-means 更穩定,仍然可以使用 n_init=1。為此,我們使用 TruncatedSVD,它適用於詞彙計數/tf-idf 矩陣。由於 SVD 結果未標準化,我們重新進行標準化以改善 KMeans 的結果。在資訊檢索和文字探勘文獻中,使用 SVD 來降低 TF-IDF 文件向量的維度通常稱為潛在語義分析 (LSA)。
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import Normalizer
lsa = make_pipeline(TruncatedSVD(n_components=100), Normalizer(copy=False))
t0 = time()
X_lsa = lsa.fit_transform(X_tfidf)
explained_variance = lsa[0].explained_variance_ratio_.sum()
print(f"LSA done in {time() - t0:.3f} s")
print(f"Explained variance of the SVD step: {explained_variance * 100:.1f}%")
LSA done in 0.382 s
Explained variance of the SVD step: 18.4%
使用單一初始化表示 KMeans 和 MiniBatchKMeans 的處理時間都將減少。
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=1,
)
fit_and_evaluate(kmeans, X_lsa, name="KMeans\nwith LSA on tf-idf vectors")
clustering done in 0.02 ± 0.00 s
Homogeneity: 0.393 ± 0.014
Completeness: 0.428 ± 0.014
V-measure: 0.410 ± 0.013
Adjusted Rand-Index: 0.312 ± 0.025
Silhouette Coefficient: 0.030 ± 0.001
我們可以觀察到,在文件的 LSA 表示上進行叢集分析速度明顯更快(因為 n_init=1 且 LSA 特徵空間的維度小得多)。此外,所有叢集評估指標都有所改善。我們使用 MiniBatchKMeans 重複實驗。
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(
n_clusters=true_k,
n_init=1,
init_size=1000,
batch_size=1000,
)
fit_and_evaluate(
minibatch_kmeans,
X_lsa,
name="MiniBatchKMeans\nwith LSA on tf-idf vectors",
)
clustering done in 0.02 ± 0.00 s
Homogeneity: 0.339 ± 0.098
Completeness: 0.384 ± 0.080
V-measure: 0.357 ± 0.089
Adjusted Rand-Index: 0.299 ± 0.131
Silhouette Coefficient: 0.026 ± 0.005
每個叢集的前幾個詞彙#
由於 TfidfVectorizer 可以反轉,因此我們可以識別叢集中心,這提供了每個叢集中最具影響力的詞彙的直觀概念。有關每個目標類別中最具預測性的詞彙的比較,請參閱範例腳本 使用稀疏特徵進行文字文件分類。
original_space_centroids = lsa[0].inverse_transform(kmeans.cluster_centers_)
order_centroids = original_space_centroids.argsort()[:, ::-1]
terms = vectorizer.get_feature_names_out()
for i in range(true_k):
print(f"Cluster {i}: ", end="")
for ind in order_centroids[i, :10]:
print(f"{terms[ind]} ", end="")
print()
Cluster 0: space nasa shuttle launch station program think sci like just
Cluster 1: just like time think don know ve does new good
Cluster 2: god people don think jesus bible say believe religion christian
Cluster 3: thanks graphics image file program files know help looking format
HashingVectorizer#
可以使用 HashingVectorizer 實例完成替代的向量化,由於這是一個無狀態模型(fit 方法不做任何事情),因此它不提供 IDF 加權。當需要 IDF 加權時,可以透過將 HashingVectorizer 的輸出管線化至 TfidfTransformer 實例來加入。在這種情況下,我們還將 LSA 加入到管線中,以減少雜湊向量空間的維度和稀疏性。
from sklearn.feature_extraction.text import HashingVectorizer, TfidfTransformer
lsa_vectorizer = make_pipeline(
HashingVectorizer(stop_words="english", n_features=50_000),
TfidfTransformer(),
TruncatedSVD(n_components=100, random_state=0),
Normalizer(copy=False),
)
t0 = time()
X_hashed_lsa = lsa_vectorizer.fit_transform(dataset.data)
print(f"vectorization done in {time() - t0:.3f} s")
vectorization done in 1.871 s
可以觀察到,LSA 步驟需要相對較長的時間才能擬合,特別是使用雜湊向量時。原因是雜湊空間通常很大(在本範例中設定為 n_features=50_000)。可以嘗試降低特徵數量,但會以較大比例的特徵具有雜湊衝突為代價,如範例筆記本 FeatureHasher 和 DictVectorizer 比較 中所示。
我們現在在這個雜湊-lsa-降維資料上擬合和評估 kmeans 和 minibatch_kmeans 實例。
fit_and_evaluate(kmeans, X_hashed_lsa, name="KMeans\nwith LSA on hashed vectors")
clustering done in 0.02 ± 0.00 s
Homogeneity: 0.387 ± 0.011
Completeness: 0.429 ± 0.017
V-measure: 0.407 ± 0.013
Adjusted Rand-Index: 0.328 ± 0.023
Silhouette Coefficient: 0.029 ± 0.001
fit_and_evaluate(
minibatch_kmeans,
X_hashed_lsa,
name="MiniBatchKMeans\nwith LSA on hashed vectors",
)
clustering done in 0.02 ± 0.00 s
Homogeneity: 0.357 ± 0.043
Completeness: 0.378 ± 0.046
V-measure: 0.367 ± 0.043
Adjusted Rand-Index: 0.322 ± 0.030
Silhouette Coefficient: 0.028 ± 0.004
兩種方法都產生良好的結果,與在傳統 LSA 向量(不含雜湊)上執行相同模型時的結果相似。
叢集評估摘要#
import matplotlib.pyplot as plt
import pandas as pd
fig, (ax0, ax1) = plt.subplots(ncols=2, figsize=(16, 6), sharey=True)
df = pd.DataFrame(evaluations[::-1]).set_index("estimator")
df_std = pd.DataFrame(evaluations_std[::-1]).set_index("estimator")
df.drop(
["train_time"],
axis="columns",
).plot.barh(ax=ax0, xerr=df_std)
ax0.set_xlabel("Clustering scores")
ax0.set_ylabel("")
df["train_time"].plot.barh(ax=ax1, xerr=df_std["train_time"])
ax1.set_xlabel("Clustering time (s)")
plt.tight_layout()
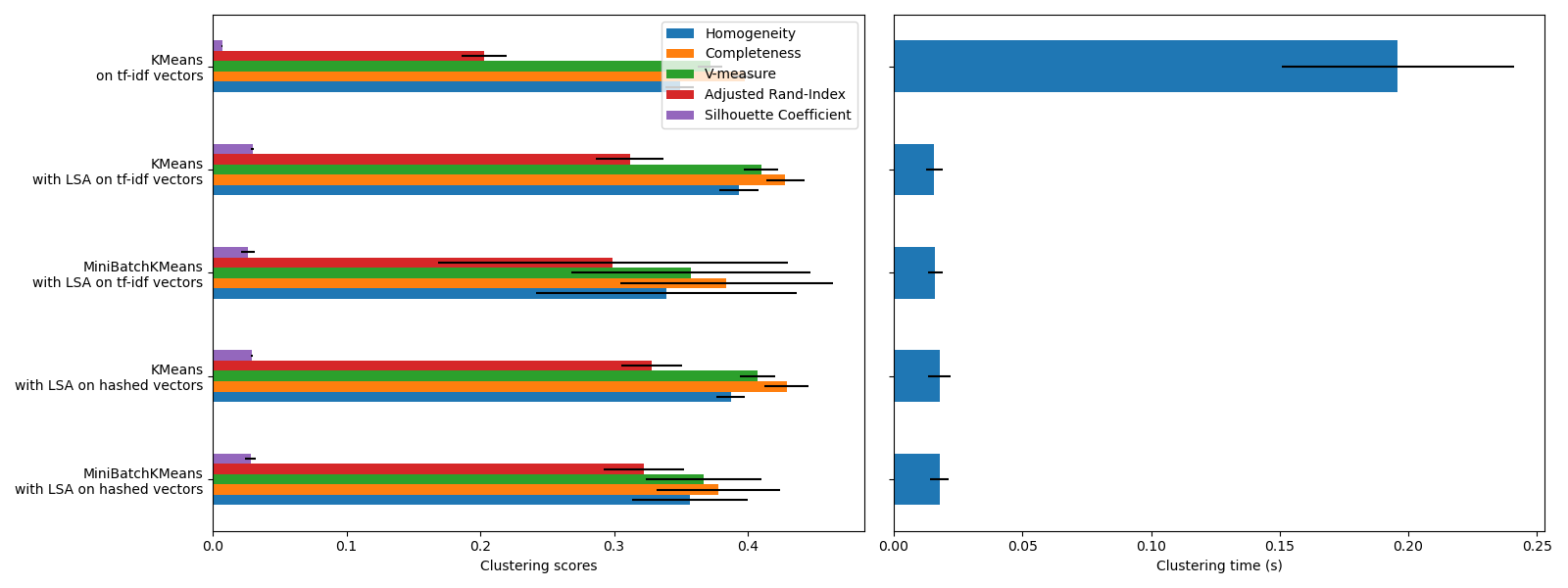
KMeans 和 MiniBatchKMeans 都會受到稱為維度詛咒的現象的影響,對於高維度資料集(如文字資料)而言。這就是為什麼使用 LSA 時整體分數會提高的原因。使用 LSA 降維資料還可以提高穩定性並減少叢集時間,但請記住,LSA 步驟本身需要很長時間,特別是使用雜湊向量時。
輪廓係數定義在 0 和 1 之間。在所有情況下,我們都會獲得接近 0 的值(即使在使用 LSA 後有所改善),因為其定義需要測量距離,這與其他僅基於叢集分配而非距離的評估指標(如 V 測度和調整蘭德指數)形成對比。請注意,嚴格來說,由於它們所隱含的距離概念不同,因此不應比較不同維度空間之間的輪廓係數。
同質性、完整性以及由此產生的 V 測度指標不會產生關於隨機標籤的基準:這表示根據樣本數、叢集數和真實類別數的不同,完全隨機的標籤不一定會產生相同的值。特別是,隨機標籤不會產生零分,尤其是在叢集數量很大時。當樣本數超過一千且叢集數小於 10 時(目前範例的情況就是如此),可以安全地忽略此問題。對於較小的樣本大小或較大的叢集數,使用調整後的索引(如調整蘭德指數(ARI))會更安全。有關隨機標籤影響的示範,請參閱範例 叢集效能評估中的機會調整。
誤差線的大小顯示,對於這個相對較小資料集而言,MiniBatchKMeans 的穩定性低於 KMeans。當樣本數量大得多時,使用它會更有趣,但與傳統的 k-means 演算法相比,它可能會以犧牲叢集品質為代價。
腳本總執行時間:(0 分鐘 7.560 秒)
相關範例