注意
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
高斯過程迴歸 (GPR) 估計資料雜訊層級的能力#
此範例顯示 WhiteKernel 估計資料中雜訊層級的能力。此外,我們展示了核心超參數初始化的重要性。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
資料產生#
我們將在 X 包含單個特徵的環境中工作。我們建立一個將產生要預測的目標的函式。我們將增加一個選項,以便將一些雜訊加入產生的目標。
import numpy as np
def target_generator(X, add_noise=False):
target = 0.5 + np.sin(3 * X)
if add_noise:
rng = np.random.RandomState(1)
target += rng.normal(0, 0.3, size=target.shape)
return target.squeeze()
讓我們來看看目標產生器,我們不會加入任何雜訊,以觀察我們想要預測的訊號。
X = np.linspace(0, 5, num=80).reshape(-1, 1)
y = target_generator(X, add_noise=False)
import matplotlib.pyplot as plt
plt.plot(X, y, label="Expected signal")
plt.legend()
plt.xlabel("X")
_ = plt.ylabel("y")
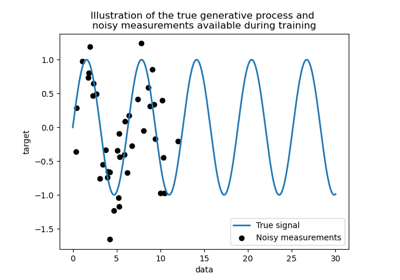
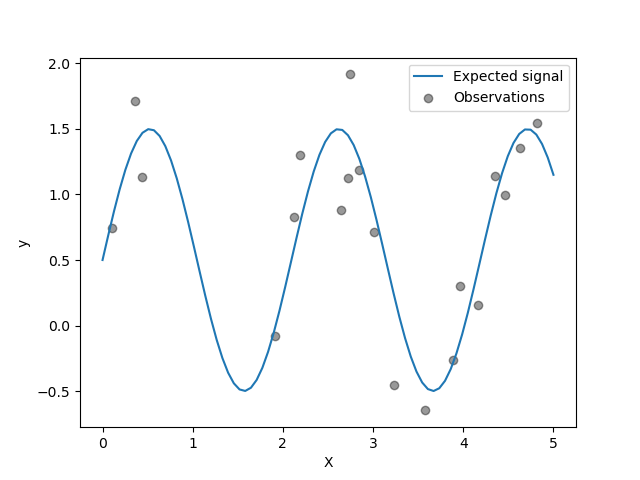
目標是使用正弦函式轉換輸入 X。現在,我們將產生一些帶雜訊的訓練樣本。為了說明雜訊層級,我們將繪製真實訊號以及帶雜訊的訓練樣本。
rng = np.random.RandomState(0)
X_train = rng.uniform(0, 5, size=20).reshape(-1, 1)
y_train = target_generator(X_train, add_noise=True)
plt.plot(X, y, label="Expected signal")
plt.scatter(
x=X_train[:, 0],
y=y_train,
color="black",
alpha=0.4,
label="Observations",
)
plt.legend()
plt.xlabel("X")
_ = plt.ylabel("y")
GPR 中核心超參數的最佳化#
現在,我們將建立一個 GaussianProcessRegressor,它使用一個附加核心,加入 RBF 和 WhiteKernel 核心。WhiteKernel 是一個可以估計資料中存在的雜訊量的核心,而 RBF 將用於擬合資料和目標之間的非線性關係。
然而,我們將顯示超參數空間包含幾個局部最小值。它將強調初始超參數值的重要性。
我們將使用具有高雜訊層級和大長度尺度的核心建立模型,這將透過雜訊解釋資料中的所有變化。
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, WhiteKernel
kernel = 1.0 * RBF(length_scale=1e1, length_scale_bounds=(1e-2, 1e3)) + WhiteKernel(
noise_level=1, noise_level_bounds=(1e-10, 1e1)
)
gpr = GaussianProcessRegressor(kernel=kernel, alpha=0.0)
gpr.fit(X_train, y_train)
y_mean, y_std = gpr.predict(X, return_std=True)
/home/circleci/project/sklearn/gaussian_process/kernels.py:452: ConvergenceWarning:
The optimal value found for dimension 0 of parameter k1__k2__length_scale is close to the specified upper bound 1000.0. Increasing the bound and calling fit again may find a better value.
plt.plot(X, y, label="Expected signal")
plt.scatter(x=X_train[:, 0], y=y_train, color="black", alpha=0.4, label="Observations")
plt.errorbar(X, y_mean, y_std, label="Posterior mean ± std")
plt.legend()
plt.xlabel("X")
plt.ylabel("y")
_ = plt.title(
(
f"Initial: {kernel}\nOptimum: {gpr.kernel_}\nLog-Marginal-Likelihood: "
f"{gpr.log_marginal_likelihood(gpr.kernel_.theta)}"
),
fontsize=8,
)
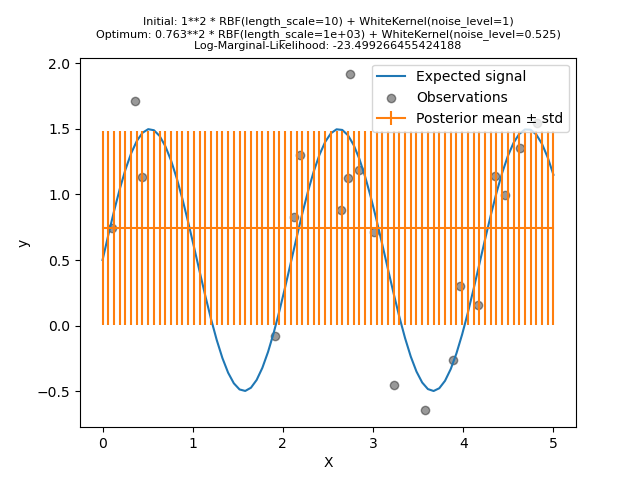
我們看到找到的最佳核心仍然具有高雜訊層級,以及更大的長度尺度。長度尺度達到我們允許此參數的最大界限,因此我們收到一個警告。
更重要的是,我們觀察到模型沒有提供有用的預測:平均預測似乎是恆定的:它沒有遵循預期的無雜訊訊號。
現在,我們將使用更大的 length_scale 初始值初始化 RBF,並使用較小的初始雜訊層級初始化 WhiteKernel,同時保持參數界限不變。
kernel = 1.0 * RBF(length_scale=1e-1, length_scale_bounds=(1e-2, 1e3)) + WhiteKernel(
noise_level=1e-2, noise_level_bounds=(1e-10, 1e1)
)
gpr = GaussianProcessRegressor(kernel=kernel, alpha=0.0)
gpr.fit(X_train, y_train)
y_mean, y_std = gpr.predict(X, return_std=True)
plt.plot(X, y, label="Expected signal")
plt.scatter(x=X_train[:, 0], y=y_train, color="black", alpha=0.4, label="Observations")
plt.errorbar(X, y_mean, y_std, label="Posterior mean ± std")
plt.legend()
plt.xlabel("X")
plt.ylabel("y")
_ = plt.title(
(
f"Initial: {kernel}\nOptimum: {gpr.kernel_}\nLog-Marginal-Likelihood: "
f"{gpr.log_marginal_likelihood(gpr.kernel_.theta)}"
),
fontsize=8,
)
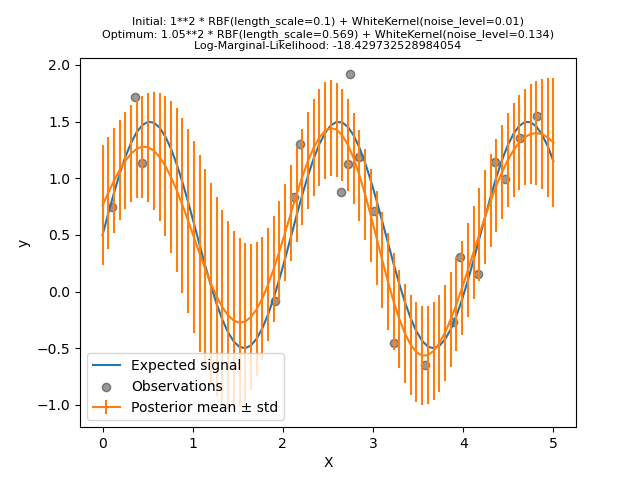
首先,我們看到模型的預測比先前的模型更精確:這個新模型能夠估計無雜訊的函數關係。
檢視核心超參數,我們看到找到的最佳組合具有比第一個模型更小的雜訊層級和更短的長度尺度。
我們可以檢查 GaussianProcessRegressor 對於不同超參數的負對數邊際似然 (LML),以了解局部最小值。
from matplotlib.colors import LogNorm
length_scale = np.logspace(-2, 4, num=80)
noise_level = np.logspace(-2, 1, num=80)
length_scale_grid, noise_level_grid = np.meshgrid(length_scale, noise_level)
log_marginal_likelihood = [
gpr.log_marginal_likelihood(theta=np.log([0.36, scale, noise]))
for scale, noise in zip(length_scale_grid.ravel(), noise_level_grid.ravel())
]
log_marginal_likelihood = np.reshape(log_marginal_likelihood, noise_level_grid.shape)
vmin, vmax = (-log_marginal_likelihood).min(), 50
level = np.around(np.logspace(np.log10(vmin), np.log10(vmax), num=20), decimals=1)
plt.contour(
length_scale_grid,
noise_level_grid,
-log_marginal_likelihood,
levels=level,
norm=LogNorm(vmin=vmin, vmax=vmax),
)
plt.colorbar()
plt.xscale("log")
plt.yscale("log")
plt.xlabel("Length-scale")
plt.ylabel("Noise-level")
plt.title("Negative log-marginal-likelihood")
plt.show()
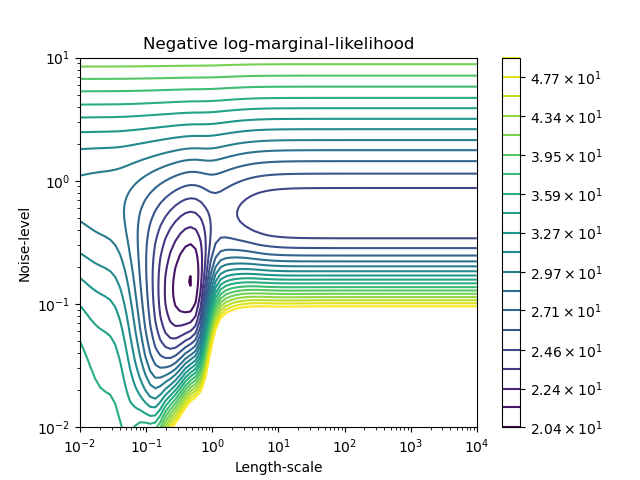
我們看到有兩個局部最小值對應於先前找到的超參數組合。根據超參數的初始值,基於梯度的最佳化可能會或可能不會收斂到最佳模型。因此,針對不同的初始化重複最佳化數次非常重要。這可以透過設定 GaussianProcessRegressor 類別的 n_restarts_optimizer 參數來完成。
讓我們再次嘗試使用不良初始值擬合我們的模型,但這次使用 10 次隨機重新啟動。
kernel = 1.0 * RBF(length_scale=1e1, length_scale_bounds=(1e-2, 1e3)) + WhiteKernel(
noise_level=1, noise_level_bounds=(1e-10, 1e1)
)
gpr = GaussianProcessRegressor(
kernel=kernel, alpha=0.0, n_restarts_optimizer=10, random_state=0
)
gpr.fit(X_train, y_train)
y_mean, y_std = gpr.predict(X, return_std=True)
plt.plot(X, y, label="Expected signal")
plt.scatter(x=X_train[:, 0], y=y_train, color="black", alpha=0.4, label="Observations")
plt.errorbar(X, y_mean, y_std, label="Posterior mean ± std")
plt.legend()
plt.xlabel("X")
plt.ylabel("y")
_ = plt.title(
(
f"Initial: {kernel}\nOptimum: {gpr.kernel_}\nLog-Marginal-Likelihood: "
f"{gpr.log_marginal_likelihood(gpr.kernel_.theta)}"
),
fontsize=8,
)
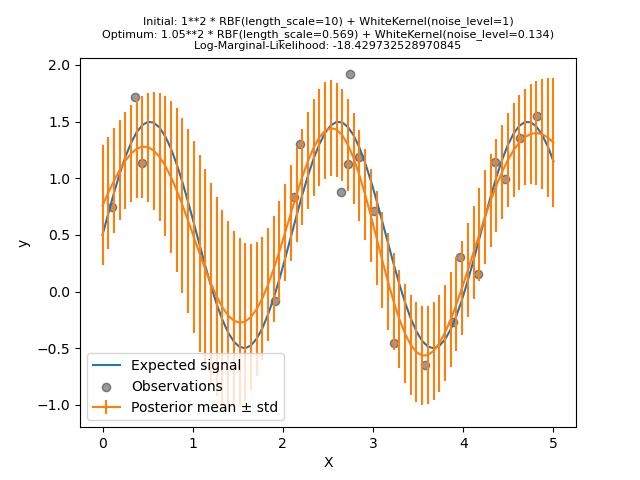
正如我們所希望的那樣,隨機重新啟動允許最佳化找到最佳的超參數集合,儘管初始值不良。
腳本的總執行時間:(0 分鐘 6.192 秒)
相關範例