注意
跳至結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
使用高斯過程迴歸 (GPR) 預測蒙納羅亞資料集上的 CO2 濃度#
此範例基於「機器學習的高斯過程」的第 5.4.3 節[1]。它說明了一個複雜核工程和使用對數邊際似然的梯度上升進行超參數最佳化的範例。資料包含 1958 年至 2001 年間在夏威夷蒙納羅亞天文台收集的每月平均大氣二氧化碳濃度(以百萬分之一體積 (ppm) 為單位)。目標是將二氧化碳濃度建模為時間 \(t\) 的函數,並推斷 2001 年之後的年份。
參考文獻
print(__doc__)
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
建立資料集#
我們將從蒙納羅亞天文台取得資料集,該天文台收集了空氣樣本。我們感興趣的是估計 CO2 的濃度並將其推斷到未來年份。首先,我們將 OpenML 中可用的原始資料集載入為 pandas 資料框架。一旦 fetch_openml 加入對它的原生支援,這將被 Polars 取代。
from sklearn.datasets import fetch_openml
co2 = fetch_openml(data_id=41187, as_frame=True)
co2.frame.head()
首先,我們處理原始資料框架以建立日期欄位,並選取它與 CO2 欄位。
import polars as pl
co2_data = pl.DataFrame(co2.frame[["year", "month", "day", "co2"]]).select(
pl.date("year", "month", "day"), "co2"
)
co2_data.head()
co2_data["date"].min(), co2_data["date"].max()
(datetime.date(1958, 3, 29), datetime.date(2001, 12, 29))
我們看到從 1958 年 3 月到 2001 年 12 月的某些日期,我們得到了 CO2 濃度。我們可以繪製這些原始資訊以更好地理解。
import matplotlib.pyplot as plt
plt.plot(co2_data["date"], co2_data["co2"])
plt.xlabel("date")
plt.ylabel("CO$_2$ concentration (ppm)")
_ = plt.title("Raw air samples measurements from the Mauna Loa Observatory")
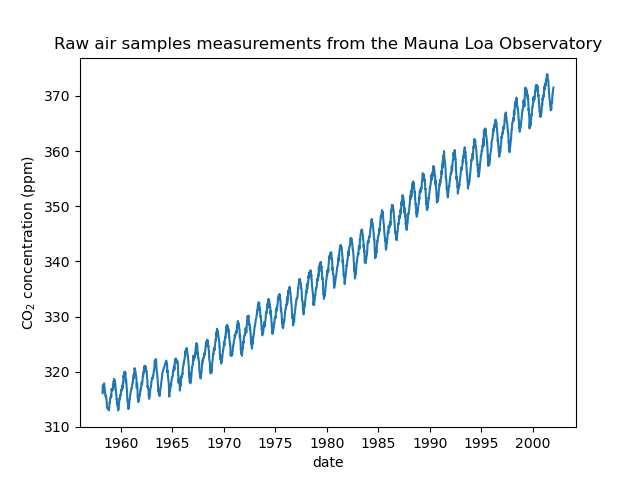
我們將透過取每月平均值並刪除未收集測量的月份來預處理資料集。這種處理將對資料產生平滑效果。
co2_data = (
co2_data.sort(by="date")
.group_by_dynamic("date", every="1mo")
.agg(pl.col("co2").mean())
.drop_nulls()
)
plt.plot(co2_data["date"], co2_data["co2"])
plt.xlabel("date")
plt.ylabel("Monthly average of CO$_2$ concentration (ppm)")
_ = plt.title(
"Monthly average of air samples measurements\nfrom the Mauna Loa Observatory"
)
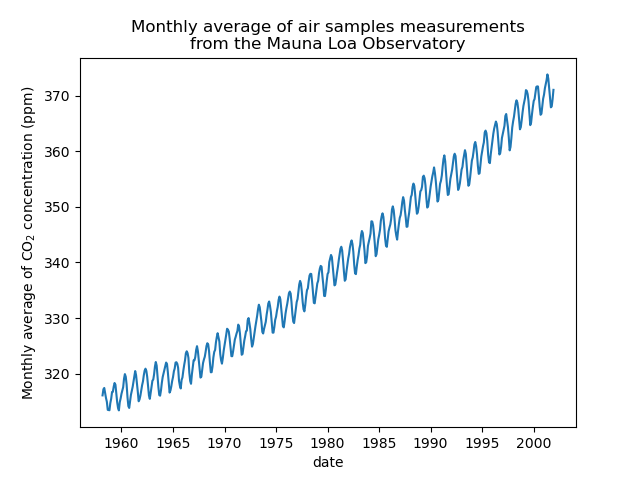
此範例中的想法是預測日期函數中的 CO2 濃度。我們也對推斷 2001 年之後的未來年份感興趣。
第一步,我們將資料和目標分開進行估計。由於資料是日期,我們將其轉換為數值。
X = co2_data.select(
pl.col("date").dt.year() + pl.col("date").dt.month() / 12
).to_numpy()
y = co2_data["co2"].to_numpy()
設計適當的核#
為了設計與我們的高斯過程一起使用的核,我們可以對手頭的資料做出一些假設。我們觀察到它們有幾個特徵:我們看到長期上升趨勢、明顯的季節性變化和一些較小的異常。我們可以使用不同的適當核來捕捉這些特徵。
首先,可以使用具有較大長度尺度參數的徑向基函數 (RBF) 核來擬合長期上升趨勢。具有較大長度尺度的 RBF 核強制此元件平滑。不會強制趨勢增加,以便為我們的模型提供自由度。特定的長度尺度和振幅是自由超參數。
季節性變化由週期為 1 年的週期性指數正弦平方核解釋。此週期性元件的長度尺度(控制其平滑度)是一個自由參數。為了允許從精確週期性衰減,將與 RBF 核的乘積進行。此 RBF 元件的長度尺度控制衰減時間,是另一個自由參數。這種類型的核也稱為局部週期性核。
from sklearn.gaussian_process.kernels import ExpSineSquared
seasonal_kernel = (
2.0**2
* RBF(length_scale=100.0)
* ExpSineSquared(length_scale=1.0, periodicity=1.0, periodicity_bounds="fixed")
)
小的不規則性要由有理二次核元件解釋,該元件的長度尺度和 alpha 參數(量化長度尺度的擴散性)將被確定。有理二次核等效於具有多個長度尺度的 RBF 核,並且可以更好地適應不同的不規則性。
from sklearn.gaussian_process.kernels import RationalQuadratic
irregularities_kernel = 0.5**2 * RationalQuadratic(length_scale=1.0, alpha=1.0)
最後,資料集中的雜訊可以使用由 RBF 核貢獻組成的核來解釋,該核應解釋相關的雜訊元件(例如局部天氣現象),以及白雜訊的白核貢獻。相對振幅和 RBF 的長度尺度是其他的自由參數。
from sklearn.gaussian_process.kernels import WhiteKernel
noise_kernel = 0.1**2 * RBF(length_scale=0.1) + WhiteKernel(
noise_level=0.1**2, noise_level_bounds=(1e-5, 1e5)
)
因此,我們的最終核是所有先前核的總和。
co2_kernel = (
long_term_trend_kernel + seasonal_kernel + irregularities_kernel + noise_kernel
)
co2_kernel
50**2 * RBF(length_scale=50) + 2**2 * RBF(length_scale=100) * ExpSineSquared(length_scale=1, periodicity=1) + 0.5**2 * RationalQuadratic(alpha=1, length_scale=1) + 0.1**2 * RBF(length_scale=0.1) + WhiteKernel(noise_level=0.01)
模型擬合和推斷#
現在,我們準備好使用高斯過程迴歸器並擬合可用資料。為了遵循文獻中的範例,我們將從目標中減去平均值。我們可以使用 normalize_y=True。但是,這樣做也會縮放目標(將 y 除以其標準差)。因此,不同核的超參數將具有不同的意義,因為它們不會以 ppm 表示。
from sklearn.gaussian_process import GaussianProcessRegressor
y_mean = y.mean()
gaussian_process = GaussianProcessRegressor(kernel=co2_kernel, normalize_y=False)
gaussian_process.fit(X, y - y_mean)
現在,我們將使用高斯過程來預測
訓練資料以檢查擬合的優度;
未來資料,以查看模型進行的推斷。
因此,我們建立從 1958 年到當前月份的合成資料。此外,我們需要加上訓練期間計算的減去平均值。
import datetime
import numpy as np
today = datetime.datetime.now()
current_month = today.year + today.month / 12
X_test = np.linspace(start=1958, stop=current_month, num=1_000).reshape(-1, 1)
mean_y_pred, std_y_pred = gaussian_process.predict(X_test, return_std=True)
mean_y_pred += y_mean
plt.plot(X, y, color="black", linestyle="dashed", label="Measurements")
plt.plot(X_test, mean_y_pred, color="tab:blue", alpha=0.4, label="Gaussian process")
plt.fill_between(
X_test.ravel(),
mean_y_pred - std_y_pred,
mean_y_pred + std_y_pred,
color="tab:blue",
alpha=0.2,
)
plt.legend()
plt.xlabel("Year")
plt.ylabel("Monthly average of CO$_2$ concentration (ppm)")
_ = plt.title(
"Monthly average of air samples measurements\nfrom the Mauna Loa Observatory"
)
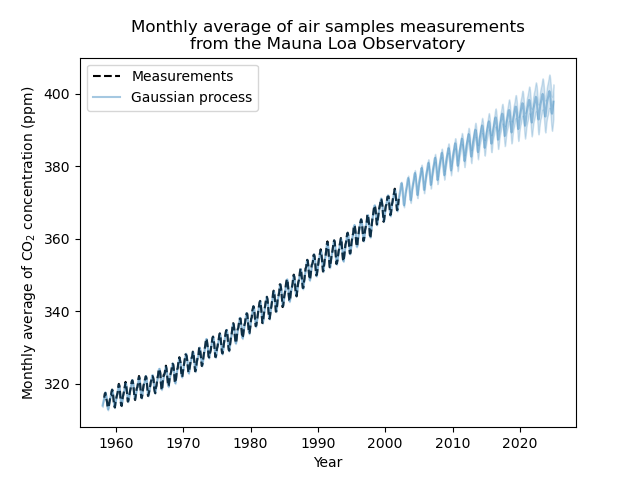
我們擬合的模型能夠正確擬合先前的資料並有信心地推斷到未來年份。
核超參數的解釋#
現在,我們可以看看核的超參數。
gaussian_process.kernel_
44.8**2 * RBF(length_scale=51.6) + 2.64**2 * RBF(length_scale=91.5) * ExpSineSquared(length_scale=1.48, periodicity=1) + 0.536**2 * RationalQuadratic(alpha=2.89, length_scale=0.968) + 0.188**2 * RBF(length_scale=0.122) + WhiteKernel(noise_level=0.0367)
因此,大部分的目標訊號(減去平均值)可以解釋為 ~45 ppm 的長期上升趨勢和 ~52 年的長度尺度。週期性元件的振幅約為 ~2.6ppm,衰減時間約為 ~90 年,長度尺度約為 ~1.5。長衰減時間表示我們有一個非常接近季節性週期性的元件。相關雜訊的振幅約為 ~0.2 ppm,長度尺度約為 ~0.12 年,而白雜訊的貢獻約為 ~0.04 ppm。因此,整體雜訊水平非常小,表示該模型可以很好地解釋資料。
腳本總執行時間: (0 分鐘 4.251 秒)
相關範例