注意
前往結尾 以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
使用高斯過程分類 (GPC) 的機率預測#
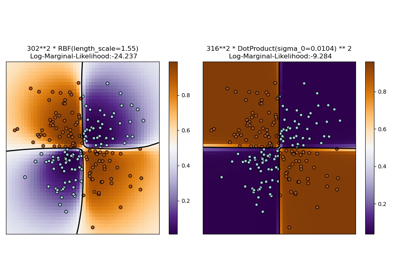
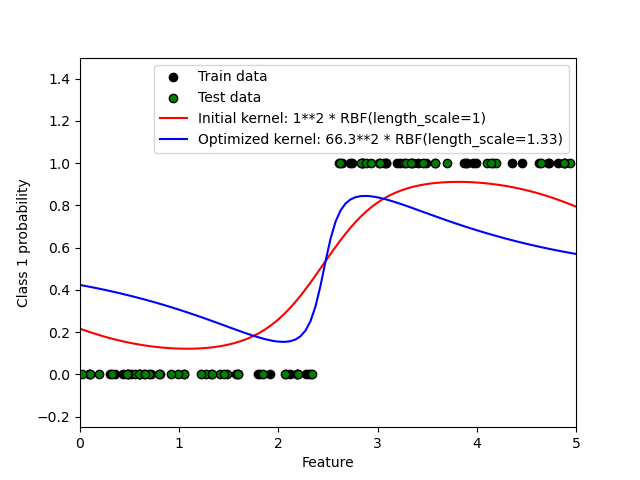
此範例說明具有不同超參數選擇的 RBF 核心的 GPC 預測機率。第一張圖顯示任意選擇超參數和對應於最大對數邊際似然 (LML) 的超參數的 GPC 預測機率。
雖然透過最佳化 LML 選擇的超參數具有顯著較大的 LML,但根據測試資料上的對數損失,它們的表現略差。該圖顯示這是因為它們在類別邊界處呈現類別機率的急劇變化(這是好的),但在遠離類別邊界的地方預測的機率接近 0.5(這是壞的)。這種不良影響是由 GPC 內部使用的拉普拉斯近似引起的。
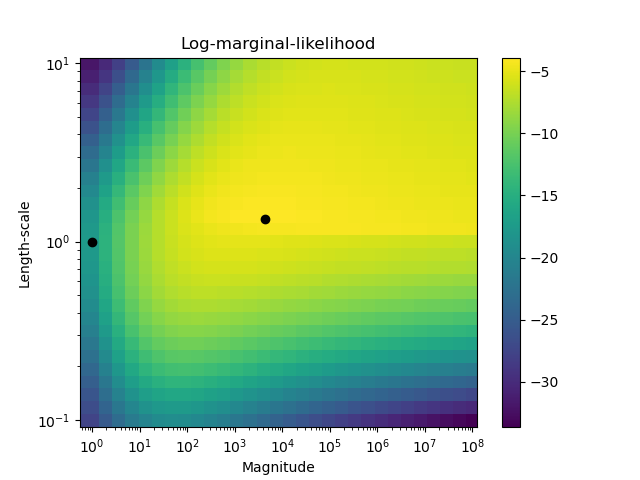
第二張圖顯示了核心的不同超參數選擇的對數邊際似然,用黑點標出了第一張圖中使用的兩個超參數選擇。
Log Marginal Likelihood (initial): -17.598
Log Marginal Likelihood (optimized): -3.875
Accuracy: 1.000 (initial) 1.000 (optimized)
Log-loss: 0.214 (initial) 0.319 (optimized)
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.metrics import accuracy_score, log_loss
# Generate data
train_size = 50
rng = np.random.RandomState(0)
X = rng.uniform(0, 5, 100)[:, np.newaxis]
y = np.array(X[:, 0] > 2.5, dtype=int)
# Specify Gaussian Processes with fixed and optimized hyperparameters
gp_fix = GaussianProcessClassifier(kernel=1.0 * RBF(length_scale=1.0), optimizer=None)
gp_fix.fit(X[:train_size], y[:train_size])
gp_opt = GaussianProcessClassifier(kernel=1.0 * RBF(length_scale=1.0))
gp_opt.fit(X[:train_size], y[:train_size])
print(
"Log Marginal Likelihood (initial): %.3f"
% gp_fix.log_marginal_likelihood(gp_fix.kernel_.theta)
)
print(
"Log Marginal Likelihood (optimized): %.3f"
% gp_opt.log_marginal_likelihood(gp_opt.kernel_.theta)
)
print(
"Accuracy: %.3f (initial) %.3f (optimized)"
% (
accuracy_score(y[:train_size], gp_fix.predict(X[:train_size])),
accuracy_score(y[:train_size], gp_opt.predict(X[:train_size])),
)
)
print(
"Log-loss: %.3f (initial) %.3f (optimized)"
% (
log_loss(y[:train_size], gp_fix.predict_proba(X[:train_size])[:, 1]),
log_loss(y[:train_size], gp_opt.predict_proba(X[:train_size])[:, 1]),
)
)
# Plot posteriors
plt.figure()
plt.scatter(
X[:train_size, 0], y[:train_size], c="k", label="Train data", edgecolors=(0, 0, 0)
)
plt.scatter(
X[train_size:, 0], y[train_size:], c="g", label="Test data", edgecolors=(0, 0, 0)
)
X_ = np.linspace(0, 5, 100)
plt.plot(
X_,
gp_fix.predict_proba(X_[:, np.newaxis])[:, 1],
"r",
label="Initial kernel: %s" % gp_fix.kernel_,
)
plt.plot(
X_,
gp_opt.predict_proba(X_[:, np.newaxis])[:, 1],
"b",
label="Optimized kernel: %s" % gp_opt.kernel_,
)
plt.xlabel("Feature")
plt.ylabel("Class 1 probability")
plt.xlim(0, 5)
plt.ylim(-0.25, 1.5)
plt.legend(loc="best")
# Plot LML landscape
plt.figure()
theta0 = np.logspace(0, 8, 30)
theta1 = np.logspace(-1, 1, 29)
Theta0, Theta1 = np.meshgrid(theta0, theta1)
LML = [
[
gp_opt.log_marginal_likelihood(np.log([Theta0[i, j], Theta1[i, j]]))
for i in range(Theta0.shape[0])
]
for j in range(Theta0.shape[1])
]
LML = np.array(LML).T
plt.plot(
np.exp(gp_fix.kernel_.theta)[0], np.exp(gp_fix.kernel_.theta)[1], "ko", zorder=10
)
plt.plot(
np.exp(gp_opt.kernel_.theta)[0], np.exp(gp_opt.kernel_.theta)[1], "ko", zorder=10
)
plt.pcolor(Theta0, Theta1, LML)
plt.xscale("log")
plt.yscale("log")
plt.colorbar()
plt.xlabel("Magnitude")
plt.ylabel("Length-scale")
plt.title("Log-marginal-likelihood")
plt.show()
腳本的總執行時間: (0 分鐘 2.492 秒)
相關範例