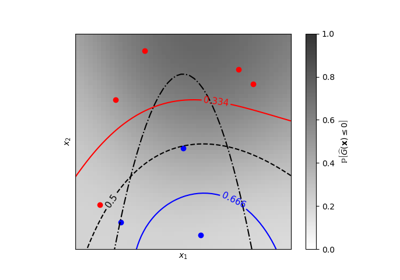
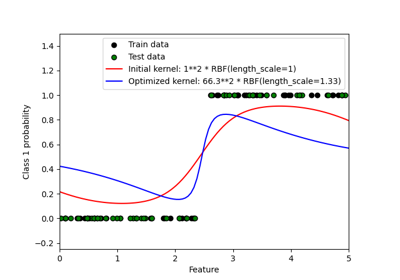
GaussianProcessClassifier#
- class sklearn.gaussian_process.GaussianProcessClassifier(kernel=None, *, optimizer='fmin_l_bfgs_b', n_restarts_optimizer=0, max_iter_predict=100, warm_start=False, copy_X_train=True, random_state=None, multi_class='one_vs_rest', n_jobs=None)[原始碼]#
基於拉普拉斯近似的高斯過程分類 (GPC)。
此實作基於 [RW2006] 的演算法 3.1、3.2 和 5.1。
在內部,拉普拉斯近似用於將非高斯後驗近似為高斯分佈。
目前,此實作僅限於使用邏輯連結函數。對於多類別分類,將擬合多個二元一對多分類器。請注意,此類別因此並未實作真正的多類別拉普拉斯近似。
請在使用者指南中閱讀更多內容。
在 0.18 版本中新增。
- 參數:
- kernel核心實例,預設值=None
指定 GP 共變異數函數的核心。如果傳入 None,則預設使用核心「1.0 * RBF(1.0)」。請注意,核心的超參數會在擬合期間最佳化。核心也不能是
CompoundKernel。- optimizer‘fmin_l_bfgs_b’、可呼叫物件或 None,預設值為 ‘fmin_l_bfgs_b’
可以是內部支援的最佳化器之一,用於最佳化核心的參數(以字串指定),也可以是作為可呼叫物件傳入的外部定義最佳化器。如果傳入可呼叫物件,則它必須具有下列簽名
def optimizer(obj_func, initial_theta, bounds): # * 'obj_func' is the objective function to be maximized, which # takes the hyperparameters theta as parameter and an # optional flag eval_gradient, which determines if the # gradient is returned additionally to the function value # * 'initial_theta': the initial value for theta, which can be # used by local optimizers # * 'bounds': the bounds on the values of theta .... # Returned are the best found hyperparameters theta and # the corresponding value of the target function. return theta_opt, func_min
依預設,會使用 scipy.optimize.minimize 中的 ‘L-BFGS-B’ 演算法。如果傳入 None,則會保持核心的參數固定。可用的內部最佳化器為
'fmin_l_bfgs_b'- n_restarts_optimizerint,預設值=0
最佳化器用於尋找最大化對數邊際概似的核心參數的重新啟動次數。最佳化器的第一次執行是從核心的初始參數執行,其餘執行(如果有的話)是從 theta 值所允許的空間中以對數均勻隨機方式取樣的 theta 值執行。如果大於 0,則所有界限都必須是有限的。請注意,n_restarts_optimizer=0 表示執行一次。
- max_iter_predictint,預設值=100
牛頓法中用於近似預測期間的後驗的最大迭代次數。較小的值會減少計算時間,但會以較差的結果為代價。
- warm_startbool,預設值=False
如果啟用熱啟動,則後驗模式拉普拉斯近似的最後一次牛頓迭代的解會作為下一次呼叫 _posterior_mode() 的初始化。當在類似的問題上多次呼叫 _posterior_mode(例如在超參數最佳化中)時,這可以加快收斂速度。請參閱詞彙表。
- copy_X_trainbool,預設值=True
如果為 True,則訓練資料的永久複本會儲存在物件中。否則,只會儲存訓練資料的參考,如果外部修改資料,可能會導致預測變更。
- random_stateint、RandomState 實例或 None,預設值=None
決定用於初始化中心點的隨機數字產生。傳入 int 以跨多個函式呼叫獲得可重複的結果。請參閱詞彙表。
- multi_class{‘one_vs_rest’, ‘one_vs_one’},預設值為 ‘one_vs_rest’
指定如何處理多類別分類問題。支援 ‘one_vs_rest’ 和 ‘one_vs_one’。在 ‘one_vs_rest’ 中,會為每個類別擬合一個二元高斯過程分類器,並訓練該分類器以將此類別與其餘類別分開。在 ‘one_vs_one’ 中,會為每對類別擬合一個二元高斯過程分類器,並訓練該分類器以將這兩個類別分開。這些二元預測器的預測會合併為多類別預測。請注意,‘one_vs_one’ 不支援預測機率估計值。
- n_jobsint,預設值=None
用於計算的作業數:指定的多類別問題會平行計算。
None表示 1,除非在joblib.parallel_backend環境中。-1表示使用所有處理器。如需更多詳細資料,請參閱詞彙表。
- 屬性:
- base_estimator_
Estimator實例 定義使用觀察資料的概似函數的估算器實例。
kernel_核心實例傳回基本估算器的核心。
- log_marginal_likelihood_value_float
self.kernel_.theta的對數邊際概似- classes_形狀為 (n_classes,) 的類陣列
唯一的類別標籤。
- n_classes_int
訓練資料中的類別數量
- n_features_in_int
在 fit 期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有都是字串的特徵名稱時才定義。在 1.0 版本中新增。
- base_estimator_
另請參閱
GaussianProcessRegressor高斯過程迴歸 (GPR)。
參考文獻
範例
>>> from sklearn.datasets import load_iris >>> from sklearn.gaussian_process import GaussianProcessClassifier >>> from sklearn.gaussian_process.kernels import RBF >>> X, y = load_iris(return_X_y=True) >>> kernel = 1.0 * RBF(1.0) >>> gpc = GaussianProcessClassifier(kernel=kernel, ... random_state=0).fit(X, y) >>> gpc.score(X, y) 0.9866... >>> gpc.predict_proba(X[:2,:]) array([[0.83548752, 0.03228706, 0.13222543], [0.79064206, 0.06525643, 0.14410151]])
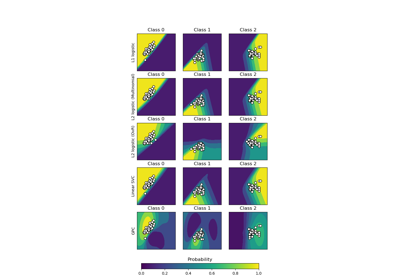
如需將 GaussianProcessClassifier 與其他分類器比較的資訊,請參閱: 繪製分類機率。
- fit(X, y)[原始碼]#
擬合高斯過程分類模型。
- 參數:
- X類陣列 (array-like),形狀為 (n_samples, n_features) 或物件列表
訓練資料的特徵向量或其他表示法。
- y類陣列 (array-like),形狀為 (n_samples,)
目標值,必須為二元值。
- 回傳:
- self物件
回傳自身的實例。
- get_metadata_routing()[原始碼]#
取得此物件的元資料路由。
請查看使用手冊,了解路由機制如何運作。
- 回傳:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deep布林值 (bool), 預設值=True
若為 True,則會回傳此估計器及其所包含的子物件 (也是估計器) 的參數。
- 回傳:
- params字典 (dict)
參數名稱對應到其值的字典。
- property kernel_#
傳回基本估算器的核心。
- log_marginal_likelihood(theta=None, eval_gradient=False, clone_kernel=True)[原始碼]#
回傳訓練資料的 theta 對數邊際似然率。
在多類別分類的情況下,會回傳一對多分類器的平均對數邊際似然率。
- 參數:
- theta類陣列 (array-like),形狀為 (n_kernel_params,),預設值=None
評估對數邊際似然率的核函數超參數。在多類別分類的情況下,theta 可以是複合核函數或個別核函數的超參數。在後一種情況下,所有個別核函數都會被賦予相同的 theta 值。若為 None,則會回傳
self.kernel_.theta的預先計算的 log_marginal_likelihood。- eval_gradient布林值 (bool), 預設值=False
若為 True,則額外回傳在 theta 位置上,對核函數超參數的對數邊際似然率梯度。請注意,不支援非二元分類的梯度計算。若為 True,則 theta 不可為 None。
- clone_kernel布林值 (bool), 預設值=True
若為 True,則會複製核函數屬性。若為 False,則會修改核函數屬性,但可能導致效能提升。
- 回傳:
- log_likelihood浮點數 (float)
訓練資料的 theta 對數邊際似然率。
- log_likelihood_gradientndarray,形狀為 (n_kernel_params,),選填
在 theta 位置上,對核函數超參數的對數邊際似然率梯度。僅當
eval_gradient為 True 時才會回傳。
- predict(X)[原始碼]#
對測試向量 X 陣列執行分類。
- 參數:
- X類陣列 (array-like),形狀為 (n_samples, n_features) 或物件列表
查詢用於分類的 GP 評估點。
- 回傳:
- Cndarray,形狀為 (n_samples,)
X 的預測目標值,值來自
classes_。
- predict_proba(X)[原始碼]#
回傳測試向量 X 的機率估計。
- 參數:
- X類陣列 (array-like),形狀為 (n_samples, n_features) 或物件列表
查詢用於分類的 GP 評估點。
- 回傳:
- C類陣列 (array-like),形狀為 (n_samples, n_classes)
回傳模型中每個類別的樣本機率。各欄對應到類別的排序順序,如同屬性 classes_ 中所顯示。
- score(X, y, sample_weight=None)[原始碼]#
回傳給定測試資料和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴格的指標,因為它要求每個樣本的每個標籤集都被正確預測。
- 參數:
- X類陣列 (array-like),形狀為 (n_samples, n_features)
測試樣本。
- y類陣列 (array-like),形狀為 (n_samples,) 或 (n_samples, n_outputs)
X的真實標籤。- sample_weight類陣列 (array-like),形狀為 (n_samples,),預設值=None
樣本權重。
- 回傳:
- score浮點數 (float)
關於
y的self.predict(X)平均準確度。
- set_params(**params)[原始碼]#
設定此估計器的參數。
此方法適用於簡單估計器以及巢狀物件 (例如
Pipeline)。後者具有<component>__<parameter>形式的參數,因此可以更新巢狀物件的每個元件。- 參數:
- **params字典 (dict)
估計器參數。
- 回傳:
- self估計器實例
估計器實例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GaussianProcessClassifier[原始碼]#
要求傳遞給
score方法的元資料。請注意,此方法僅在
enable_metadata_routing=True時才相關 (請參閱sklearn.set_config)。請參閱使用手冊,了解路由機制如何運作。每個參數的選項為
True:要求元資料,並在提供時傳遞給score。如果未提供元資料,則會忽略請求。False:不要求元資料,而且元估計器不會將其傳遞給score。None:不要求元資料,如果使用者提供元資料,元估計器會引發錯誤。str:元資料應使用給定的別名而非原始名稱傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這允許您變更某些參數的請求,而保留其他參數的請求不變。在 1.3 版本中新增。
注意
此方法僅在此估計器作為元估計器的子估計器使用時才相關,例如在
Pipeline內部使用。否則沒有任何效果。- 參數:
- sample_weight字串 (str)、True、False 或 None,預設值=sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight參數的元資料路由。
- 回傳:
- self物件
更新後的物件。