注意
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
多類別接收者操作特徵 (ROC)#
本範例描述如何使用接收者操作特徵 (ROC) 指標來評估多類別分類器的品質。
ROC 曲線通常在 Y 軸上顯示真陽性率 (TPR),在 X 軸上顯示假陽性率 (FPR)。這表示圖表的左上角是「理想」點 - FPR 為零,TPR 為一。這不是很實際,但這確實表示曲線下方面積 (AUC) 越大通常越好。ROC 曲線的「陡峭度」也很重要,因為在最小化 FPR 的同時最大化 TPR 是理想的。
ROC 曲線通常用於二元分類,其中可以明確定義 TPR 和 FPR。在多類別分類的情況下,只有在二元化輸出後才能獲得 TPR 或 FPR 的概念。這可以透過 2 種不同的方式完成
一對剩餘 (One-vs-Rest) 方案將每個類別與所有其他類別(假設為一)進行比較;
一對一 (One-vs-One) 方案比較每種唯一的類別成對組合。
在本範例中,我們探討這兩種方案,並示範微平均和巨平均的概念,作為總結多類別 ROC 曲線資訊的不同方式。
注意
請參閱 接收者操作特徵 (ROC) 與交叉驗證 以了解目前範例的延伸,估計 ROC 曲線及其各自 AUC 的變異數。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
載入和準備資料#
我們匯入 Iris 植物資料集,其中包含 3 個類別,每個類別對應一種虹膜植物。一個類別與其他 2 個類別線性可分;後者彼此之間不是線性可分的。
在此,我們將輸出二元化並新增雜訊特徵,使問題更困難。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
target_names = iris.target_names
X, y = iris.data, iris.target
y = iris.target_names[y]
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
n_classes = len(np.unique(y))
X = np.concatenate([X, random_state.randn(n_samples, 200 * n_features)], axis=1)
(
X_train,
X_test,
y_train,
y_test,
) = train_test_split(X, y, test_size=0.5, stratify=y, random_state=0)
我們訓練一個 LogisticRegression 模型,由於使用了多項式公式,它可以自然地處理多類別問題。
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
y_score = classifier.fit(X_train, y_train).predict_proba(X_test)
一對剩餘多類別 ROC#
一對剩餘 (OvR) 多類別策略,也稱為一對全部,包含計算每個 n_classes 的 ROC 曲線。在每個步驟中,給定類別被視為正類別,其餘類別被視為一個整體,作為負類別。
注意
不應將用於評估多類別分類器的 OvR 策略與用於透過擬合一組二元分類器來訓練多類別分類器的 OvR 策略混淆(例如,透過 OneVsRestClassifier 元估算器)。OvR ROC 評估可用於審查任何種類的分類模型,無論它們是如何訓練的(請參閱 多類別和多輸出演算法)。
在本節中,我們使用 LabelBinarizer 以 OvR 方式透過一鍵編碼來二元化目標。這表示形狀為 (n_samples,) 的目標會對應到形狀為 (n_samples, n_classes) 的目標。
from sklearn.preprocessing import LabelBinarizer
label_binarizer = LabelBinarizer().fit(y_train)
y_onehot_test = label_binarizer.transform(y_test)
y_onehot_test.shape # (n_samples, n_classes)
(75, 3)
我們也可以輕鬆檢查特定類別的編碼
label_binarizer.transform(["virginica"])
array([[0, 0, 1]])
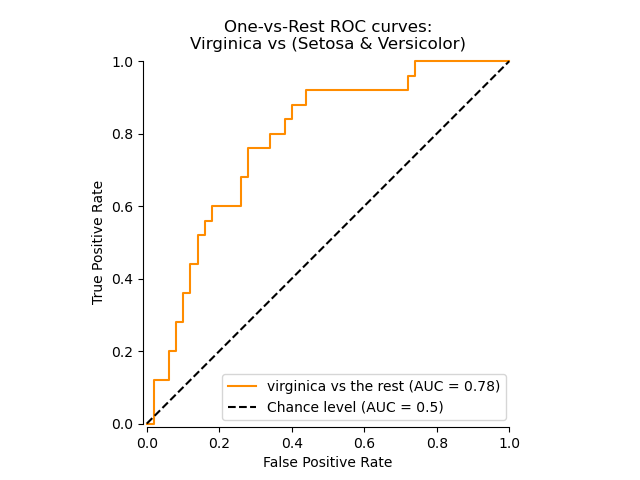
顯示特定類別的 ROC 曲線#
在下圖中,我們顯示將虹膜花視為「virginica」(class_id=2)或「非 virginica」(其餘)時所產生的 ROC 曲線。
class_of_interest = "virginica"
class_id = np.flatnonzero(label_binarizer.classes_ == class_of_interest)[0]
class_id
np.int64(2)
import matplotlib.pyplot as plt
from sklearn.metrics import RocCurveDisplay
display = RocCurveDisplay.from_predictions(
y_onehot_test[:, class_id],
y_score[:, class_id],
name=f"{class_of_interest} vs the rest",
color="darkorange",
plot_chance_level=True,
despine=True,
)
_ = display.ax_.set(
xlabel="False Positive Rate",
ylabel="True Positive Rate",
title="One-vs-Rest ROC curves:\nVirginica vs (Setosa & Versicolor)",
)
使用微平均 OvR 的 ROC 曲線#
微平均匯總所有類別的貢獻(使用 numpy.ravel),以如下方式計算平均指標
\(TPR=\frac{\sum_{c}TP_c}{\sum_{c}(TP_c + FN_c)}\) ;
\(FPR=\frac{\sum_{c}FP_c}{\sum_{c}(FP_c + TN_c)}\) .
我們可以簡要示範 numpy.ravel 的效果
print(f"y_score:\n{y_score[0:2,:]}")
print()
print(f"y_score.ravel():\n{y_score[0:2,:].ravel()}")
y_score:
[[0.38 0.05 0.57]
[0.07 0.28 0.65]]
y_score.ravel():
[0.38 0.05 0.57 0.07 0.28 0.65]
在具有高度不平衡類別的多類別分類設置中,微平均優於巨平均。在這種情況下,可以選擇使用加權巨平均,此處未示範。
display = RocCurveDisplay.from_predictions(
y_onehot_test.ravel(),
y_score.ravel(),
name="micro-average OvR",
color="darkorange",
plot_chance_level=True,
despine=True,
)
_ = display.ax_.set(
xlabel="False Positive Rate",
ylabel="True Positive Rate",
title="Micro-averaged One-vs-Rest\nReceiver Operating Characteristic",
)
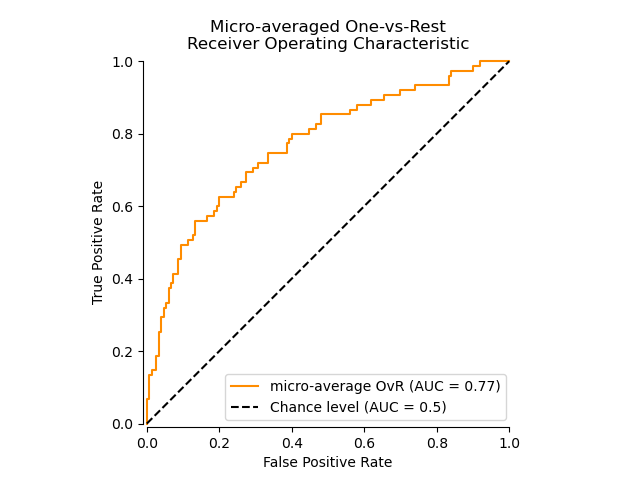
在主要興趣不是圖表而是 ROC-AUC 分數本身的情況下,我們可以使用 roc_auc_score 重複圖表中顯示的值。
from sklearn.metrics import roc_auc_score
micro_roc_auc_ovr = roc_auc_score(
y_test,
y_score,
multi_class="ovr",
average="micro",
)
print(f"Micro-averaged One-vs-Rest ROC AUC score:\n{micro_roc_auc_ovr:.2f}")
Micro-averaged One-vs-Rest ROC AUC score:
0.77
這相當於使用 roc_curve 計算 ROC 曲線,然後使用 auc 計算展開的真類別和預測類別的曲線下面積。
from sklearn.metrics import auc, roc_curve
# store the fpr, tpr, and roc_auc for all averaging strategies
fpr, tpr, roc_auc = dict(), dict(), dict()
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_onehot_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
print(f"Micro-averaged One-vs-Rest ROC AUC score:\n{roc_auc['micro']:.2f}")
Micro-averaged One-vs-Rest ROC AUC score:
0.77
注意
依預設,ROC 曲線的計算會透過使用線性內插法和 McClish 校正,在最大假陽性率新增一個點 [分析 ROC 曲線 Med Decis Making 的一部分。1989 年 7 月至 9 月; 9(3):190-5。]。
使用 OvR 巨平均的 ROC 曲線#
取得巨平均需要獨立計算每個類別的指標,然後計算它們的平均值,因此先驗地同等對待所有類別。我們首先匯總每個類別的真/假陽性率
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_onehot_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
fpr_grid = np.linspace(0.0, 1.0, 1000)
# Interpolate all ROC curves at these points
mean_tpr = np.zeros_like(fpr_grid)
for i in range(n_classes):
mean_tpr += np.interp(fpr_grid, fpr[i], tpr[i]) # linear interpolation
# Average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = fpr_grid
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
print(f"Macro-averaged One-vs-Rest ROC AUC score:\n{roc_auc['macro']:.2f}")
Macro-averaged One-vs-Rest ROC AUC score:
0.78
此計算相當於簡單地呼叫
macro_roc_auc_ovr = roc_auc_score(
y_test,
y_score,
multi_class="ovr",
average="macro",
)
print(f"Macro-averaged One-vs-Rest ROC AUC score:\n{macro_roc_auc_ovr:.2f}")
Macro-averaged One-vs-Rest ROC AUC score:
0.78
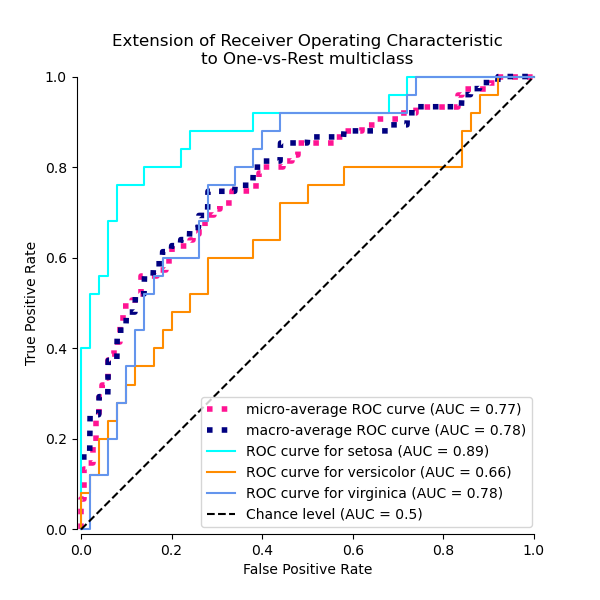
一起繪製所有 OvR ROC 曲線#
from itertools import cycle
fig, ax = plt.subplots(figsize=(6, 6))
plt.plot(
fpr["micro"],
tpr["micro"],
label=f"micro-average ROC curve (AUC = {roc_auc['micro']:.2f})",
color="deeppink",
linestyle=":",
linewidth=4,
)
plt.plot(
fpr["macro"],
tpr["macro"],
label=f"macro-average ROC curve (AUC = {roc_auc['macro']:.2f})",
color="navy",
linestyle=":",
linewidth=4,
)
colors = cycle(["aqua", "darkorange", "cornflowerblue"])
for class_id, color in zip(range(n_classes), colors):
RocCurveDisplay.from_predictions(
y_onehot_test[:, class_id],
y_score[:, class_id],
name=f"ROC curve for {target_names[class_id]}",
color=color,
ax=ax,
plot_chance_level=(class_id == 2),
despine=True,
)
_ = ax.set(
xlabel="False Positive Rate",
ylabel="True Positive Rate",
title="Extension of Receiver Operating Characteristic\nto One-vs-Rest multiclass",
)
一對一多類別 ROC#
一對一 (OvO) 多類別策略包含針對每個類別對擬合一個分類器。由於它需要訓練 n_classes * (n_classes - 1) / 2 個分類器,因此由於其 O(n_classes ^2) 複雜度,此方法通常比一對剩餘慢。
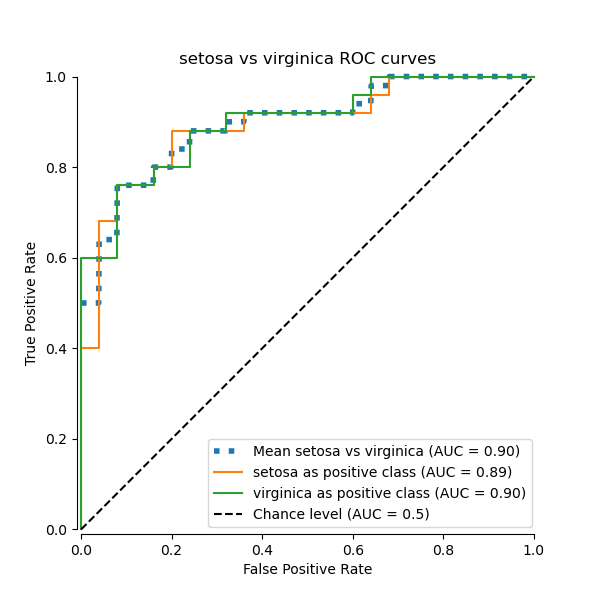
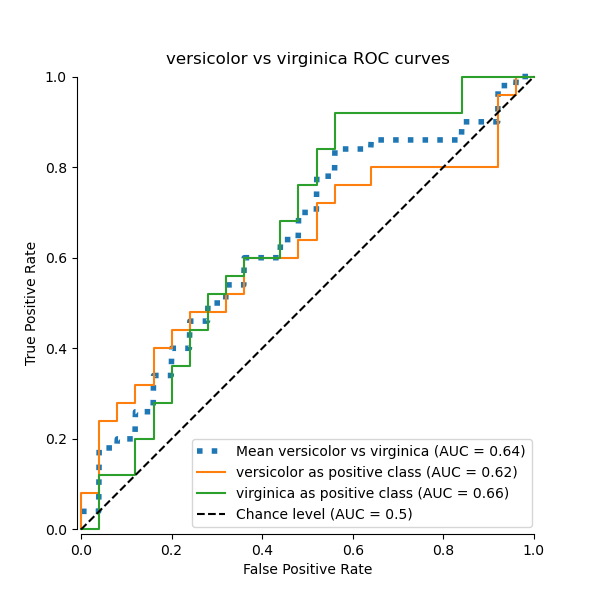
在本節中,我們將展示在鳶尾花資料集中使用 OvO (One-vs-One) 策略,針對 3 種可能的組合計算的巨觀平均 AUC: “setosa” vs “versicolor”,“versicolor” vs “virginica”,以及 “virginica” vs “setosa”。請注意,微觀平均不適用於 OvO 策略。
使用 OvO 巨觀平均的 ROC 曲線#
在 OvO 策略中,第一步是找出所有可能的唯一配對組合。分數的計算方式是將給定配對中的一個元素視為正類別,另一個元素視為負類別,然後反轉角色重新計算分數,並取兩者的平均值。
from itertools import combinations
pair_list = list(combinations(np.unique(y), 2))
print(pair_list)
[(np.str_('setosa'), np.str_('versicolor')), (np.str_('setosa'), np.str_('virginica')), (np.str_('versicolor'), np.str_('virginica'))]
pair_scores = []
mean_tpr = dict()
for ix, (label_a, label_b) in enumerate(pair_list):
a_mask = y_test == label_a
b_mask = y_test == label_b
ab_mask = np.logical_or(a_mask, b_mask)
a_true = a_mask[ab_mask]
b_true = b_mask[ab_mask]
idx_a = np.flatnonzero(label_binarizer.classes_ == label_a)[0]
idx_b = np.flatnonzero(label_binarizer.classes_ == label_b)[0]
fpr_a, tpr_a, _ = roc_curve(a_true, y_score[ab_mask, idx_a])
fpr_b, tpr_b, _ = roc_curve(b_true, y_score[ab_mask, idx_b])
mean_tpr[ix] = np.zeros_like(fpr_grid)
mean_tpr[ix] += np.interp(fpr_grid, fpr_a, tpr_a)
mean_tpr[ix] += np.interp(fpr_grid, fpr_b, tpr_b)
mean_tpr[ix] /= 2
mean_score = auc(fpr_grid, mean_tpr[ix])
pair_scores.append(mean_score)
fig, ax = plt.subplots(figsize=(6, 6))
plt.plot(
fpr_grid,
mean_tpr[ix],
label=f"Mean {label_a} vs {label_b} (AUC = {mean_score :.2f})",
linestyle=":",
linewidth=4,
)
RocCurveDisplay.from_predictions(
a_true,
y_score[ab_mask, idx_a],
ax=ax,
name=f"{label_a} as positive class",
)
RocCurveDisplay.from_predictions(
b_true,
y_score[ab_mask, idx_b],
ax=ax,
name=f"{label_b} as positive class",
plot_chance_level=True,
despine=True,
)
ax.set(
xlabel="False Positive Rate",
ylabel="True Positive Rate",
title=f"{target_names[idx_a]} vs {label_b} ROC curves",
)
print(f"Macro-averaged One-vs-One ROC AUC score:\n{np.average(pair_scores):.2f}")
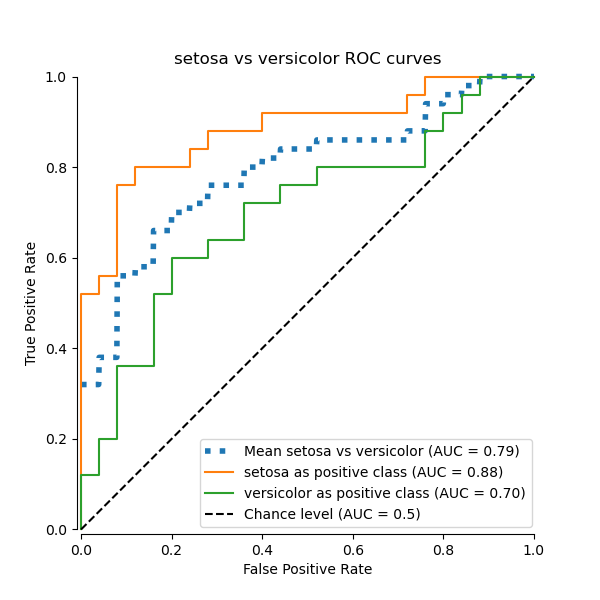
Macro-averaged One-vs-One ROC AUC score:
0.78
還可以斷言,我們「手動」計算的巨觀平均值,等同於 roc_auc_score 函數中實作的 average="macro" 選項。
macro_roc_auc_ovo = roc_auc_score(
y_test,
y_score,
multi_class="ovo",
average="macro",
)
print(f"Macro-averaged One-vs-One ROC AUC score:\n{macro_roc_auc_ovo:.2f}")
Macro-averaged One-vs-One ROC AUC score:
0.78
一起繪製所有 OvO ROC 曲線#
ovo_tpr = np.zeros_like(fpr_grid)
fig, ax = plt.subplots(figsize=(6, 6))
for ix, (label_a, label_b) in enumerate(pair_list):
ovo_tpr += mean_tpr[ix]
ax.plot(
fpr_grid,
mean_tpr[ix],
label=f"Mean {label_a} vs {label_b} (AUC = {pair_scores[ix]:.2f})",
)
ovo_tpr /= sum(1 for pair in enumerate(pair_list))
ax.plot(
fpr_grid,
ovo_tpr,
label=f"One-vs-One macro-average (AUC = {macro_roc_auc_ovo:.2f})",
linestyle=":",
linewidth=4,
)
ax.plot([0, 1], [0, 1], "k--", label="Chance level (AUC = 0.5)")
_ = ax.set(
xlabel="False Positive Rate",
ylabel="True Positive Rate",
title="Extension of Receiver Operating Characteristic\nto One-vs-One multiclass",
aspect="equal",
xlim=(-0.01, 1.01),
ylim=(-0.01, 1.01),
)
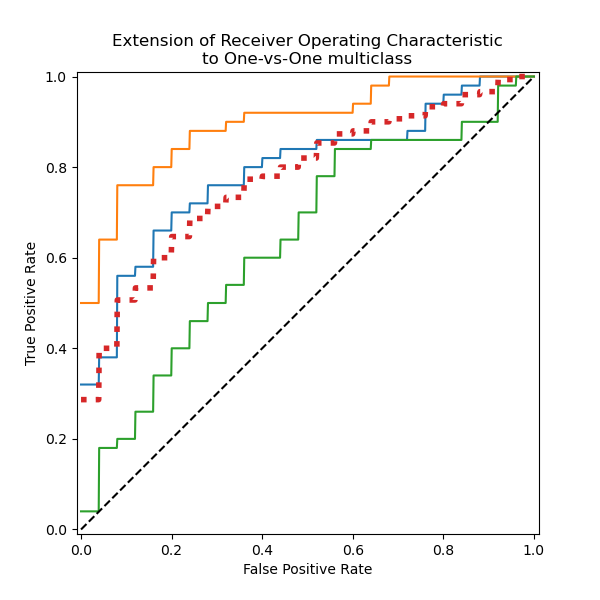
我們確認類別 “versicolor” 和 “virginica” 無法被線性分類器很好地識別。請注意,“virginica” 相對於其他類別的 ROC-AUC 分數 (0.77) 介於 “versicolor” vs “virginica” (0.64) 和 “setosa” vs “virginica” (0.90) 的 OvO ROC-AUC 分數之間。事實上,OvO 策略提供了關於一對類別之間混淆的額外資訊,但當類別數量很大時,會增加計算成本。
如果使用者主要關心正確識別特定類別或類別子集,建議使用 OvO 策略,而分類器的整體效能仍然可以透過給定的平均策略來總結。
微觀平均 OvR ROC 受較頻繁的類別主導,因為計數是被合併的。巨觀平均的替代方案能更好地反映較不頻繁類別的統計數據,因此當所有類別的效能都被認為同樣重要時,它更為合適。
腳本總執行時間:(0 分鐘 0.681 秒)
相關範例