注意
前往結尾下載完整範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
多類別 AdaBoosted 決策樹#
此範例示範了提升如何改善多標籤分類問題的預測準確性。它重現了 Zhu 等人 [1] 中圖 1 所描繪的類似實驗。
AdaBoost(自適應提升)的核心原則是在資料的重複重新採樣版本上擬合一系列弱學習器(例如決策樹)。每個樣本都帶有一個權重,該權重在每次訓練步驟後進行調整,以便將較高的權重分配給分類錯誤的樣本。帶置換的重新採樣過程會考慮分配給每個樣本的權重。權重較高的樣本在新資料集中有較大的機會被多次選取,而權重較低的樣本則不太可能被選取。這確保演算法的後續迭代專注於難以分類的樣本。
參考文獻
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
建立資料集#
分類資料集是透過取一個十維標準常態分佈(\(x\) 在 \(R^{10}\) 中)並定義三個類別來建構的,這三個類別由巢狀同心十維球體分隔,以便每個類別中具有大致相等數量的樣本(\(\chi^2\) 分佈的分位數)。
from sklearn.datasets import make_gaussian_quantiles
X, y = make_gaussian_quantiles(
n_samples=2_000, n_features=10, n_classes=3, random_state=1
)
我們將資料集分成 2 組:70% 的樣本用於訓練,其餘 30% 用於測試。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.7, random_state=42
)
訓練 AdaBoostClassifier#
我們訓練 AdaBoostClassifier。估算器利用提升來改善分類準確性。提升是一種旨在訓練弱學習器(即 estimator)的方法,這些弱學習器會從其前身犯的錯誤中學習。
在此,我們將弱學習器定義為 DecisionTreeClassifier,並將最大葉節點數設為 8。在真實環境中,應調整此參數。我們將其設定為較低的值,以限制範例的執行時間。
然後,建構到 AdaBoostClassifier 中的 SAMME 演算法會使用目前弱學習器所做的正確或不正確預測,來更新用於訓練連續弱學習器的樣本權重。此外,弱學習器本身的權重是根據其在分類訓練範例中的準確性來計算的。弱學習器的權重決定其對最終集成預測的影響。
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
weak_learner = DecisionTreeClassifier(max_leaf_nodes=8)
n_estimators = 300
adaboost_clf = AdaBoostClassifier(
estimator=weak_learner,
n_estimators=n_estimators,
random_state=42,
).fit(X_train, y_train)
分析#
AdaBoostClassifier 的收斂性#
為了示範提升在改善準確性方面的有效性,我們評估了提升樹的錯誤分類錯誤,並與兩個基準分數進行比較。第一個基準分數是從單個弱學習器(即 DecisionTreeClassifier)獲得的 misclassification_error,它用作參考點。第二個基準分數是從 DummyClassifier 獲得的,它會預測資料集中最普遍的類別。
from sklearn.dummy import DummyClassifier
from sklearn.metrics import accuracy_score
dummy_clf = DummyClassifier()
def misclassification_error(y_true, y_pred):
return 1 - accuracy_score(y_true, y_pred)
weak_learners_misclassification_error = misclassification_error(
y_test, weak_learner.fit(X_train, y_train).predict(X_test)
)
dummy_classifiers_misclassification_error = misclassification_error(
y_test, dummy_clf.fit(X_train, y_train).predict(X_test)
)
print(
"DecisionTreeClassifier's misclassification_error: "
f"{weak_learners_misclassification_error:.3f}"
)
print(
"DummyClassifier's misclassification_error: "
f"{dummy_classifiers_misclassification_error:.3f}"
)
DecisionTreeClassifier's misclassification_error: 0.475
DummyClassifier's misclassification_error: 0.692
在訓練 DecisionTreeClassifier 模型之後,由於 DummyClassifier 會猜測最常見的類別標籤,因此所達成的錯誤會超過預期的值。
現在,我們計算 misclassification_error,即 1 - accuracy,測試集上每個提升迭代的累加模型(DecisionTreeClassifier)的錯誤,以評估其效能。
我們使用 staged_predict,它會進行與擬合估計器數量相同的迭代次數(即對應於 n_estimators)。在迭代 n 時,AdaBoost 的預測僅使用前 n 個弱學習器。我們將這些預測與真實預測 y_test 進行比較,因此得出結論,判斷在鏈中加入新的弱學習器是否有益處。
我們繪製不同階段的誤分類錯誤。
import matplotlib.pyplot as plt
import pandas as pd
boosting_errors = pd.DataFrame(
{
"Number of trees": range(1, n_estimators + 1),
"AdaBoost": [
misclassification_error(y_test, y_pred)
for y_pred in adaboost_clf.staged_predict(X_test)
],
}
).set_index("Number of trees")
ax = boosting_errors.plot()
ax.set_ylabel("Misclassification error on test set")
ax.set_title("Convergence of AdaBoost algorithm")
plt.plot(
[boosting_errors.index.min(), boosting_errors.index.max()],
[weak_learners_misclassification_error, weak_learners_misclassification_error],
color="tab:orange",
linestyle="dashed",
)
plt.plot(
[boosting_errors.index.min(), boosting_errors.index.max()],
[
dummy_classifiers_misclassification_error,
dummy_classifiers_misclassification_error,
],
color="c",
linestyle="dotted",
)
plt.legend(["AdaBoost", "DecisionTreeClassifier", "DummyClassifier"], loc=1)
plt.show()
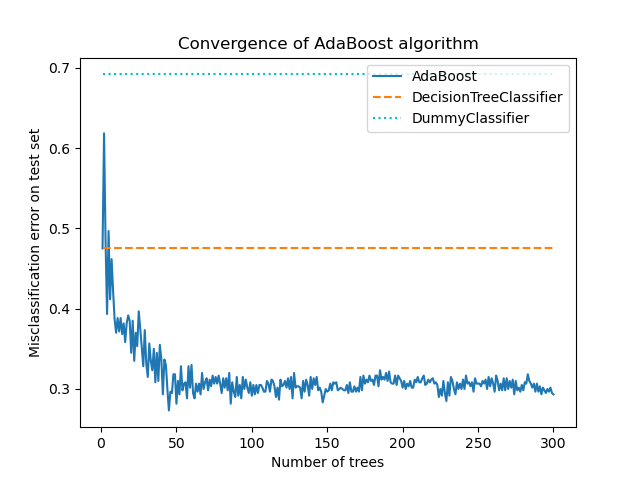
該圖顯示了每次 boosting 迭代後測試集上的誤分類錯誤。我們看到,經過 50 次迭代後,boosted 樹的錯誤收斂到約 0.3 左右,這表明與單個樹相比,準確性顯著提高,如圖中的虛線所示。
誤分類錯誤會抖動,因為 SAMME 演算法使用弱學習器的離散輸出訓練 boosted 模型。
AdaBoostClassifier 的收斂主要受學習率(即 learning_rate)、使用的弱學習器數量 (n_estimators) 以及弱學習器的表達能力 (例如 max_leaf_nodes) 的影響。
弱學習器的錯誤和權重#
如前所述,AdaBoost 是一個前向逐步加性模型。我們現在將重點放在理解弱學習器的權重與其統計表現之間的關係。
我們使用已擬合的 AdaBoostClassifier 的屬性 estimator_errors_ 和 estimator_weights_ 來研究這種聯繫。
weak_learners_info = pd.DataFrame(
{
"Number of trees": range(1, n_estimators + 1),
"Errors": adaboost_clf.estimator_errors_,
"Weights": adaboost_clf.estimator_weights_,
}
).set_index("Number of trees")
axs = weak_learners_info.plot(
subplots=True, layout=(1, 2), figsize=(10, 4), legend=False, color="tab:blue"
)
axs[0, 0].set_ylabel("Train error")
axs[0, 0].set_title("Weak learner's training error")
axs[0, 1].set_ylabel("Weight")
axs[0, 1].set_title("Weak learner's weight")
fig = axs[0, 0].get_figure()
fig.suptitle("Weak learner's errors and weights for the AdaBoostClassifier")
fig.tight_layout()
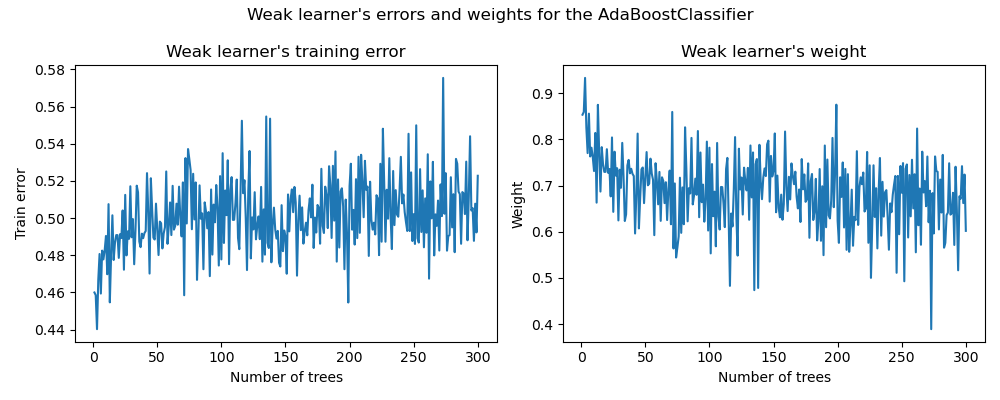
在左圖中,我們顯示了每個弱學習器在每次 boosting 迭代時,在重新加權訓練集上的加權錯誤。在右圖中,我們顯示了與每個弱學習器相關聯的權重,這些權重稍後將用於對最終加性模型進行預測。
我們看到,弱學習器的錯誤與權重成反比。這意味著我們的加性模型將更信任那些在(訓練集上)產生較小錯誤的弱學習器,方法是增加其對最終決策的影響。事實上,這正是 AdaBoost 中每次迭代後更新基本估計器權重的公式。
數學細節#
在階段 \(m\) 訓練的弱學習器相關聯的權重與其誤分類錯誤成反比,使得
其中 \(\alpha^{(m)}\) 和 \(err^{(m)}\) 分別是第 \(m\) 個弱學習器的權重和錯誤,而 \(K\) 是我們的分類問題中的類別數量。
另一個有趣的觀察結果可以歸結為以下事實:模型的第一批弱學習器比 boosting 鏈中後來的弱學習器犯的錯誤更少。
這種觀察背後的直覺如下:由於樣本重新加權,後來的分類器被迫嘗試對更困難或有雜訊的樣本進行分類,並忽略已經分類良好的樣本。因此,訓練集上的總體錯誤會增加。這就是為什麼要構建弱學習器的權重來平衡性能較差的弱學習器。
腳本的總執行時間: (0 分鐘 5.002 秒)
相關範例