注意
前往結尾以下載完整的範例程式碼。或者透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
scikit-learn 0.23 的發布重點#
我們很高興宣佈發佈 scikit-learn 0.23!添加了許多錯誤修復和改進,以及一些新的關鍵功能。我們在下面詳細介紹了此版本的幾個主要功能。如需所有變更的詳盡列表,請參閱發佈說明。
要安裝最新版本(使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
廣義線性模型和用於梯度提升的泊松損失#
期待已久的具有非正態損失函數的廣義線性模型現已推出。特別是,實施了三個新的迴歸器:PoissonRegressor、GammaRegressor 和 TweedieRegressor。泊松迴歸器可用於對正整數計數或相對頻率進行建模。請在使用者指南中閱讀更多資訊。此外,HistGradientBoostingRegressor 也支援新的 ‘poisson’ 損失。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import PoissonRegressor
from sklearn.ensemble import HistGradientBoostingRegressor
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X = rng.randn(n_samples, n_features)
# positive integer target correlated with X[:, 5] with many zeros:
y = rng.poisson(lam=np.exp(X[:, 5]) / 2)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=rng)
glm = PoissonRegressor()
gbdt = HistGradientBoostingRegressor(loss="poisson", learning_rate=0.01)
glm.fit(X_train, y_train)
gbdt.fit(X_train, y_train)
print(glm.score(X_test, y_test))
print(gbdt.score(X_test, y_test))
0.35776189065725783
0.42425183539869415
估計器的豐富視覺表示#
現在可以透過啟用 display='diagram' 選項在筆記本中視覺化估計器。這對於總結管道和其他複合估計器的結構特別有用,並具有互動性以提供詳細資訊。按一下下面的範例圖像以展開管道元素。請參閱視覺化複合估計器以了解如何使用此功能。
from sklearn import set_config
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import make_column_transformer
from sklearn.linear_model import LogisticRegression
set_config(display="diagram")
num_proc = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
cat_proc = make_pipeline(
SimpleImputer(strategy="constant", fill_value="missing"),
OneHotEncoder(handle_unknown="ignore"),
)
preprocessor = make_column_transformer(
(num_proc, ("feat1", "feat3")), (cat_proc, ("feat0", "feat2"))
)
clf = make_pipeline(preprocessor, LogisticRegression())
clf
KMeans 的可擴展性和穩定性改進#
KMeans 估計器已完全重新設計,現在速度明顯更快且更穩定。此外,Elkan 演算法現在與稀疏矩陣相容。估計器使用基於 OpenMP 的平行處理,而不是依賴 joblib,因此 n_jobs 參數不再起作用。如需有關如何控制執行緒數量的詳細資訊,請參閱我們的平行處理註釋。
import scipy
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import completeness_score
rng = np.random.RandomState(0)
X, y = make_blobs(random_state=rng)
X = scipy.sparse.csr_matrix(X)
X_train, X_test, _, y_test = train_test_split(X, y, random_state=rng)
kmeans = KMeans(n_init="auto").fit(X_train)
print(completeness_score(kmeans.predict(X_test), y_test))
0.6684259852425617
基於直方圖的梯度提升估計器的改進#
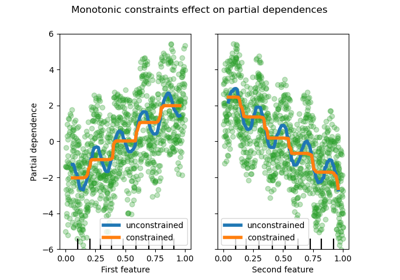
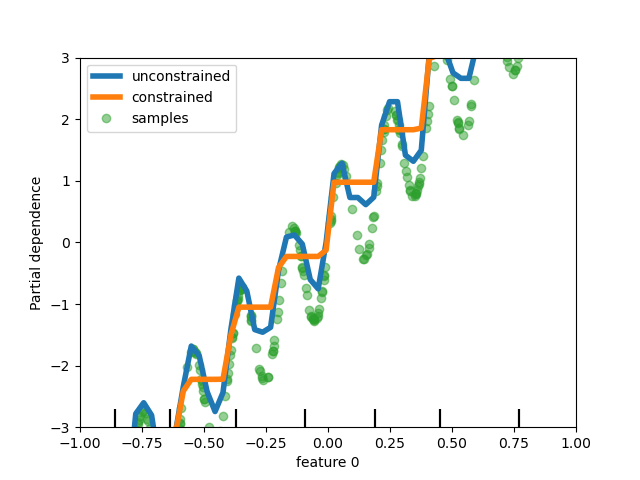
對 HistGradientBoostingClassifier 和 HistGradientBoostingRegressor 進行了各種改進。除了上述的泊松損失外,這些估計器現在還支援樣本權重。此外,還增加了自動提前停止標準:當樣本數量超過 1 萬時,預設會啟用提前停止。最後,使用者現在可以定義單調約束,以根據特定特徵的變化限制預測。在以下範例中,我們建構了一個目標,該目標通常與第一個特徵正相關,並帶有一些雜訊。應用單調約束允許預測捕獲第一個特徵的整體影響,而不是擬合雜訊。如需使用案例範例,請參閱直方圖梯度提升樹中的特徵。
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
# from sklearn.inspection import plot_partial_dependence
from sklearn.inspection import PartialDependenceDisplay
from sklearn.ensemble import HistGradientBoostingRegressor
n_samples = 500
rng = np.random.RandomState(0)
X = rng.randn(n_samples, 2)
noise = rng.normal(loc=0.0, scale=0.01, size=n_samples)
y = 5 * X[:, 0] + np.sin(10 * np.pi * X[:, 0]) - noise
gbdt_no_cst = HistGradientBoostingRegressor().fit(X, y)
gbdt_cst = HistGradientBoostingRegressor(monotonic_cst=[1, 0]).fit(X, y)
# plot_partial_dependence has been removed in version 1.2. From 1.2, use
# PartialDependenceDisplay instead.
# disp = plot_partial_dependence(
disp = PartialDependenceDisplay.from_estimator(
gbdt_no_cst,
X,
features=[0],
feature_names=["feature 0"],
line_kw={"linewidth": 4, "label": "unconstrained", "color": "tab:blue"},
)
# plot_partial_dependence(
PartialDependenceDisplay.from_estimator(
gbdt_cst,
X,
features=[0],
line_kw={"linewidth": 4, "label": "constrained", "color": "tab:orange"},
ax=disp.axes_,
)
disp.axes_[0, 0].plot(
X[:, 0], y, "o", alpha=0.5, zorder=-1, label="samples", color="tab:green"
)
disp.axes_[0, 0].set_ylim(-3, 3)
disp.axes_[0, 0].set_xlim(-1, 1)
plt.legend()
plt.show()
Lasso 和 ElasticNet 的樣本權重支援#
兩個線性迴歸器 Lasso 和 ElasticNet 現在支援樣本權重。
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression
from sklearn.linear_model import Lasso
import numpy as np
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X, y = make_regression(n_samples, n_features, random_state=rng)
sample_weight = rng.rand(n_samples)
X_train, X_test, y_train, y_test, sw_train, sw_test = train_test_split(
X, y, sample_weight, random_state=rng
)
reg = Lasso()
reg.fit(X_train, y_train, sample_weight=sw_train)
print(reg.score(X_test, y_test, sw_test))
0.999791942438998
腳本的總執行時間:(0 分鐘 0.621 秒)
相關範例