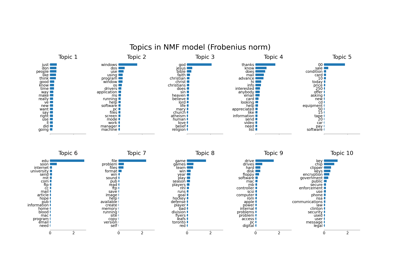
計數向量器# (CountVectorizer)
- class sklearn.feature_extraction.text.CountVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class 'numpy.int64'>)[原始碼]#
將文字文件集合轉換為詞語計數的矩陣。
此實作使用 scipy.sparse.csr_matrix 產生計數的稀疏表示法。
如果您沒有提供先驗字典,且未使用會進行某種特徵選擇的分析器,則特徵數量將等於分析資料所找到的詞彙大小。
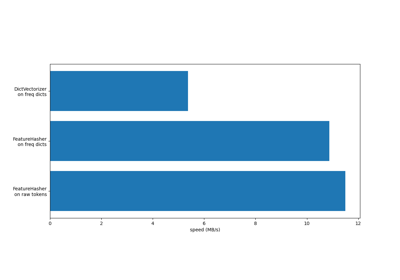
有關不同特徵提取器的效率比較,請參閱FeatureHasher 與 DictVectorizer 的比較。
如需更多資訊,請參閱使用者指南。
- 參數:
- input{‘filename’, ‘file’, ‘content’}, default=’content’
如果為
'filename',則傳遞給 fit 的引數序列預期會是需要讀取以擷取原始內容進行分析的檔案名稱清單。如果為
'file',則序列項目必須具有 'read' 方法(類檔案物件),該方法會被呼叫以擷取記憶體中的位元組。如果為
'content',則輸入預期會是可以為字串或位元組型別的項目序列。
- encodingstr, default='utf-8'
如果提供位元組或檔案進行分析,則會使用此編碼進行解碼。
- decode_error{‘strict’, ‘ignore’, ‘replace’}, default=’strict’
關於如果提供要分析的位元組序列包含給定
encoding中不包含的字元時該怎麼做的指示。預設情況下,它是 ‘strict’,表示會引發 UnicodeDecodeError。其他值為 ‘ignore’ 和 ‘replace’。- strip_accents{‘ascii’, ‘unicode’} or callable, default=None
在預處理步驟中移除重音並執行其他字元正規化。 ‘ascii’ 是一種快速方法,僅適用於具有直接 ASCII 對應的字元。 ‘unicode’ 是一種稍微慢一點的方法,適用於任何字元。 None(預設)表示不執行字元正規化。
‘ascii’ 和 ‘unicode’ 都使用來自
unicodedata.normalize的 NFKD 正規化。- lowercasebool, default=True
在進行符號化之前,將所有字元轉換為小寫。
- preprocessorcallable, default=None
覆寫預處理(strip_accents 和 lowercase)階段,同時保留符號化和 n 元語法產生步驟。僅在
analyzer不是可呼叫物件時適用。- tokenizercallable, default=None
覆寫字串符號化步驟,同時保留預處理和 n 元語法產生步驟。僅在
analyzer == 'word'時適用。- stop_words{‘english’}, list, default=None
如果為 ‘english’,則會使用內建的英文停用字清單。 ‘english’ 有幾個已知的問題,您應該考慮替代方案(請參閱使用停用字)。
如果為清單,則假設該清單包含停用字,所有這些停用字都會從產生的符號中移除。僅在
analyzer == 'word'時適用。如果為 None,則不會使用停用字。在這種情況下,將
max_df設定為更高的值,例如在 (0.7, 1.0) 的範圍內,可以根據詞彙的內部語料庫文件頻率自動偵測和篩選停用字。- token_patternstr or None, default=r”(?u)\b\w\w+\b”
表示構成「符號」的正規表示式,僅在
analyzer == 'word'時使用。預設的正規表示式會選擇 2 個或更多字母數字字元的符號(標點符號完全忽略,且始終被視為符號分隔符號)。如果 token_pattern 中有捕獲群組,則捕獲的群組內容(而不是整個匹配)會成為符號。最多允許一個捕獲群組。
- ngram_rangetuple (min_n, max_n), default=(1, 1)
要提取的不同詞語 n 元語法或字元 n 元語法的 n 值範圍的下限和上限。會使用所有 min_n <= n <= max_n 的 n 值。例如,
ngram_range為(1, 1)表示僅單字,(1, 2)表示單字和雙字,而(2, 2)表示僅雙字。僅在analyzer不是可呼叫物件時適用。- analyzer{‘word’, ‘char’, ‘char_wb’} or callable, default=’word’
特徵應該由詞語 n 元語法還是字元 n 元語法組成。選項 ‘char_wb’ 僅從單字邊界內的文字建立字元 n 元語法;單字邊緣的 n 元語法會使用空格填補。
如果傳遞可呼叫物件,則會使用該物件從原始、未處理的輸入中提取特徵序列。
在 0.21 版本中變更。
自 v0.21 版本起,如果
input為filename或file,資料會先從檔案讀取,然後傳遞至指定的分析器 (callable analyzer)。- max_dffloat 型態,範圍 [0.0, 1.0] 或 int 型態,預設值為 1.0
在建立詞彙表時,忽略文檔頻率嚴格高於給定閾值的詞彙(特定於語料庫的停用詞)。如果為 float 型態,則參數表示文檔的比例;如果為整數,則表示絕對計數。如果 vocabulary 不為 None,則會忽略此參數。
- min_dffloat 型態,範圍 [0.0, 1.0] 或 int 型態,預設值為 1
在建立詞彙表時,忽略文檔頻率嚴格低於給定閾值的詞彙。此值在文獻中也稱為截斷值 (cut-off)。如果為 float 型態,則參數表示文檔的比例;如果為整數,則表示絕對計數。如果 vocabulary 不為 None,則會忽略此參數。
- max_featuresint 型態,預設值為 None
如果不是 None,則建立詞彙表時,只考慮語料庫中詞頻最高的
max_features個詞彙。否則,將使用所有特徵。如果 vocabulary 不為 None,則會忽略此參數。
- vocabularyMapping 或可迭代物件,預設值為 None
可以是 Mapping (例如,dict),其中鍵是詞彙,值是特徵矩陣中的索引;也可以是詞彙的可迭代物件。如果未給定,則會從輸入的文檔中確定詞彙表。Mapping 中的索引不應重複,且在 0 和最大索引之間不應有任何間隙。
- binarybool 型態,預設值為 False
如果為 True,則所有非零計數都設定為 1。這對於模擬二元事件而非整數計數的離散機率模型非常有用。
- dtypedtype 型態,預設值為 np.int64
由 fit_transform() 或 transform() 傳回的矩陣類型。
- 屬性:
- vocabulary_dict 型態
詞彙到特徵索引的映射。
- fixed_vocabulary_bool 型態
如果使用者提供了固定的詞彙到索引的映射,則為 True。
另請參閱
HashingVectorizer將文字文件集合轉換為詞語計數的矩陣。
TfidfVectorizer將原始文檔集合轉換為 TF-IDF 特徵矩陣。
範例
>>> from sklearn.feature_extraction.text import CountVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = CountVectorizer() >>> X = vectorizer.fit_transform(corpus) >>> vectorizer.get_feature_names_out() array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'], ...) >>> print(X.toarray()) [[0 1 1 1 0 0 1 0 1] [0 2 0 1 0 1 1 0 1] [1 0 0 1 1 0 1 1 1] [0 1 1 1 0 0 1 0 1]] >>> vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2)) >>> X2 = vectorizer2.fit_transform(corpus) >>> vectorizer2.get_feature_names_out() array(['and this', 'document is', 'first document', 'is the', 'is this', 'second document', 'the first', 'the second', 'the third', 'third one', 'this document', 'this is', 'this the'], ...) >>> print(X2.toarray()) [[0 0 1 1 0 0 1 0 0 0 0 1 0] [0 1 0 1 0 1 0 1 0 0 1 0 0] [1 0 0 1 0 0 0 0 1 1 0 1 0] [0 0 1 0 1 0 1 0 0 0 0 0 1]]
- build_analyzer()[原始碼]#
傳回可處理輸入資料的 callable 物件。
該 callable 物件處理預處理、詞彙化 (tokenization) 和 n-gram 生成。
- 傳回值:
- analyzer: callable 型態
用於處理預處理、詞彙化和 n-gram 生成的函式。
- decode(doc)[原始碼]#
將輸入解碼為 unicode 符號的字串。
解碼策略取決於向量化器的參數。
- 參數:
- docbytes 或 str 型態
要解碼的字串。
- 傳回值:
- doc: str 型態
unicode 符號的字串。
- fit(raw_documents, y=None)[原始碼]#
學習原始文檔中所有詞彙的詞彙字典。
- 參數:
- raw_documents可迭代物件
產生 str、unicode 或檔案物件的可迭代物件。
- yNone 型態
此參數將被忽略。
- 傳回值:
- selfobject 型態
已擬合的向量化器。
- fit_transform(raw_documents, y=None)[原始碼]#
學習詞彙字典並傳回文檔詞彙矩陣。
這等同於先執行 fit 再執行 transform,但效率更高。
- 參數:
- raw_documents可迭代物件
產生 str、unicode 或檔案物件的可迭代物件。
- yNone 型態
此參數將被忽略。
- 傳回值:
- X形狀為 (n_samples, n_features) 的陣列
文檔詞彙矩陣。
- get_feature_names_out(input_features=None)[原始碼]#
取得轉換後的輸出特徵名稱。
- 參數:
- input_featuresarray-like of str 或 None 型態,預設值為 None
未使用,此處為符合 API 慣例而存在。
- 傳回值:
- feature_names_outstr 物件的 ndarray
轉換後的特徵名稱。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,以了解路由機制的運作方式。
- 傳回值:
- routingMetadataRequest
一個
MetadataRequest,封裝路由資訊。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值=True
如果為 True,將返回此估算器和包含的子物件(也是估算器)的參數。
- 傳回值:
- paramsdict
參數名稱對應到它們的值。
- inverse_transform(X)[原始碼]#
返回 X 中非零項的每個文件的詞彙。
- 參數:
- X形狀為 (n_samples, n_features) 的 {array-like, sparse matrix}
文檔詞彙矩陣。
- 傳回值:
- X_inv形狀為 (n_samples,) 的陣列列表
詞彙的陣列列表。