注意
前往結尾以下載完整的範例程式碼。或通過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
Iris 資料集 LDA 與 PCA 2D 投影比較#
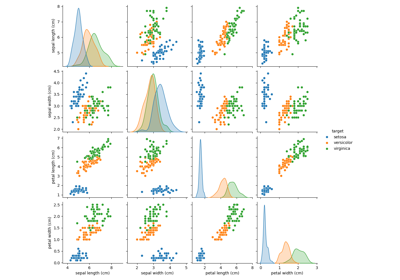
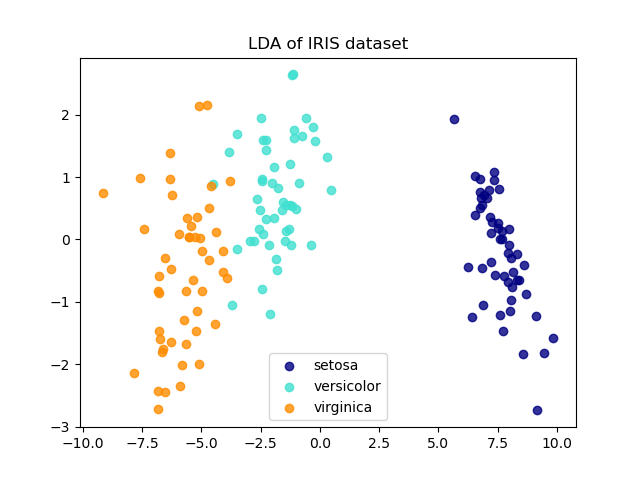
Iris 資料集代表 3 種 Iris 花卉(Setosa、Versicolour 和 Virginica),具有 4 個屬性:萼片長度、萼片寬度、花瓣長度和花瓣寬度。
套用至此資料的主成分分析 (PCA) 可識別屬性的組合(主成分,或特徵空間中的方向),這些屬性可解釋資料中的大部分變異。這裡我們在兩個第一個主成分上繪製不同的樣本。
線性判別分析 (LDA) 嘗試識別可解釋類別之間大部分變異的屬性。特別是,與 PCA 相反,LDA 是一種監督方法,使用已知的類別標籤。
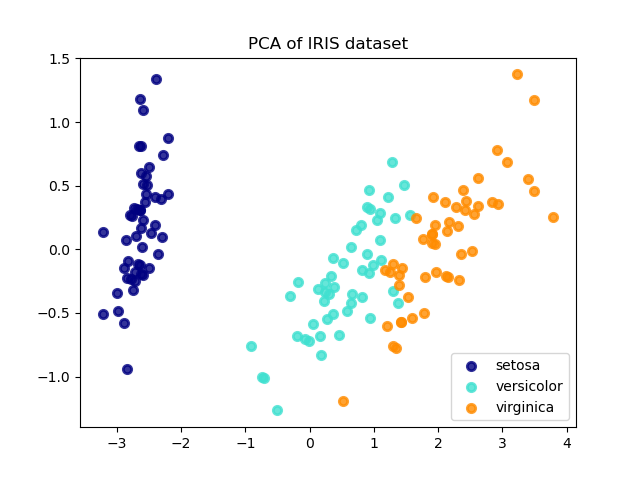
explained variance ratio (first two components): [0.92461872 0.05306648]
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
iris = datasets.load_iris()
X = iris.data
y = iris.target
target_names = iris.target_names
pca = PCA(n_components=2)
X_r = pca.fit(X).transform(X)
lda = LinearDiscriminantAnalysis(n_components=2)
X_r2 = lda.fit(X, y).transform(X)
# Percentage of variance explained for each components
print(
"explained variance ratio (first two components): %s"
% str(pca.explained_variance_ratio_)
)
plt.figure()
colors = ["navy", "turquoise", "darkorange"]
lw = 2
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(
X_r[y == i, 0], X_r[y == i, 1], color=color, alpha=0.8, lw=lw, label=target_name
)
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.title("PCA of IRIS dataset")
plt.figure()
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(
X_r2[y == i, 0], X_r2[y == i, 1], alpha=0.8, color=color, label=target_name
)
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.title("LDA of IRIS dataset")
plt.show()
腳本的總執行時間: (0 分鐘 0.194 秒)
相關範例