注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
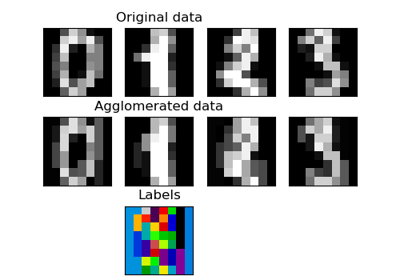
使用核主成分分析進行影像去噪#
此範例展示如何使用 KernelPCA 進行影像去噪。簡而言之,我們利用在 fit 期間學習到的近似函數來重建原始影像。
我們將使用 PCA 將結果與精確重建進行比較。
我們將使用 USPS 數字資料集來重現 [1] 第 4 節中呈現的內容。
參考文獻
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
透過 OpenML 載入資料集#
USPS 數字資料集可在 OpenML 中取得。我們使用 fetch_openml 來取得此資料集。此外,我們對資料集進行正規化,使所有像素值都在 (0, 1) 範圍內。
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
X, y = fetch_openml(data_id=41082, as_frame=False, return_X_y=True)
X = MinMaxScaler().fit_transform(X)
概念是學習有雜訊影像上的 PCA 基底(無論有無核函數),然後使用這些模型來重建和去噪這些影像。
因此,我們將資料集分割為訓練集和測試集,其中訓練集由 1,000 個樣本組成,測試集由 100 個樣本組成。這些影像沒有雜訊,我們將使用它們來評估去噪方法的效率。此外,我們會建立原始資料集的副本並加入高斯雜訊。
此應用程式的概念是展示我們可以透過學習一些未損毀影像上的 PCA 基底來去噪損毀的影像。我們將使用 PCA 和基於核函數的 PCA 來解決此問題。
X_train, X_test, y_train, y_test = train_test_split(
X, y, stratify=y, random_state=0, train_size=1_000, test_size=100
)
rng = np.random.RandomState(0)
noise = rng.normal(scale=0.25, size=X_test.shape)
X_test_noisy = X_test + noise
noise = rng.normal(scale=0.25, size=X_train.shape)
X_train_noisy = X_train + noise
此外,我們將建立一個輔助函數,透過繪製測試影像來定性評估影像重建。
import matplotlib.pyplot as plt
def plot_digits(X, title):
"""Small helper function to plot 100 digits."""
fig, axs = plt.subplots(nrows=10, ncols=10, figsize=(8, 8))
for img, ax in zip(X, axs.ravel()):
ax.imshow(img.reshape((16, 16)), cmap="Greys")
ax.axis("off")
fig.suptitle(title, fontsize=24)
此外,我們將使用均方誤差 (MSE) 來定量評估影像重建。
讓我們先來看看無雜訊影像和有雜訊影像之間的差異。我們將在這方面檢查測試集。
plot_digits(X_test, "Uncorrupted test images")
plot_digits(
X_test_noisy, f"Noisy test images\nMSE: {np.mean((X_test - X_test_noisy) ** 2):.2f}"
)


學習 PCA 基底#
現在,我們可以使用線性 PCA 和使用徑向基底函數 (RBF) 核函數的核 PCA 來學習 PCA 基底。
重建和去噪測試影像#
現在,我們可以轉換和重建有雜訊的測試集。由於我們使用的元件比原始特徵的數量少,因此我們將獲得原始集的近似值。實際上,透過丟棄在 PCA 中解釋變異數最少的元件,我們希望去除雜訊。核 PCA 中也會發生類似的思考;但是,我們預期更好的重建,因為我們使用非線性核函數來學習 PCA 基底和核嶺來學習映射函數。
X_reconstructed_kernel_pca = kernel_pca.inverse_transform(
kernel_pca.transform(X_test_noisy)
)
X_reconstructed_pca = pca.inverse_transform(pca.transform(X_test_noisy))
plot_digits(X_test, "Uncorrupted test images")
plot_digits(
X_reconstructed_pca,
f"PCA reconstruction\nMSE: {np.mean((X_test - X_reconstructed_pca) ** 2):.2f}",
)
plot_digits(
X_reconstructed_kernel_pca,
(
"Kernel PCA reconstruction\n"
f"MSE: {np.mean((X_test - X_reconstructed_kernel_pca) ** 2):.2f}"
),
)



PCA 的 MSE 比核 PCA 低。但是,定性分析可能不偏愛 PCA 而不是核 PCA。我們觀察到核 PCA 能夠去除背景雜訊並提供更平滑的影像。
但是,應該注意的是,使用核 PCA 進行去噪的結果將取決於參數 n_components、gamma 和 alpha。
腳本的總執行時間:(0 分鐘 8.871 秒)
相關範例