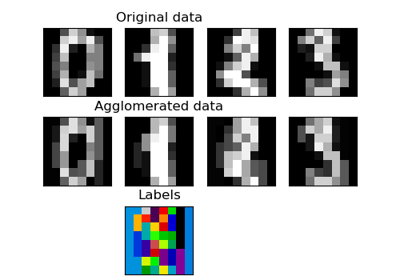
注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
線上學習人臉部位字典#
此範例使用大型人臉資料集來學習構成人臉的一組 20 x 20 影像區塊。
從程式設計的角度來看,它很有趣,因為它展示了如何使用 scikit-learn 的線上 API 來按區塊處理非常大的資料集。我們的方法是一次載入一個影像,並從該影像中隨機提取 50 個區塊。當我們累積了 500 個這些區塊 (使用 10 個影像) 後,我們執行線上 KMeans 物件 MiniBatchKMeans 的 partial_fit 方法。
MiniBatchKMeans 上的詳細設定使我們能夠看到在連續呼叫 partial-fit 期間會重新指派某些叢集。這是因為它們代表的區塊數量變得太少,最好選擇一個隨機的新叢集。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
載入資料#
from sklearn import datasets
faces = datasets.fetch_olivetti_faces()
學習影像字典#
import time
import numpy as np
from sklearn.cluster import MiniBatchKMeans
from sklearn.feature_extraction.image import extract_patches_2d
print("Learning the dictionary... ")
rng = np.random.RandomState(0)
kmeans = MiniBatchKMeans(n_clusters=81, random_state=rng, verbose=True, n_init=3)
patch_size = (20, 20)
buffer = []
t0 = time.time()
# The online learning part: cycle over the whole dataset 6 times
index = 0
for _ in range(6):
for img in faces.images:
data = extract_patches_2d(img, patch_size, max_patches=50, random_state=rng)
data = np.reshape(data, (len(data), -1))
buffer.append(data)
index += 1
if index % 10 == 0:
data = np.concatenate(buffer, axis=0)
data -= np.mean(data, axis=0)
data /= np.std(data, axis=0)
kmeans.partial_fit(data)
buffer = []
if index % 100 == 0:
print("Partial fit of %4i out of %i" % (index, 6 * len(faces.images)))
dt = time.time() - t0
print("done in %.2fs." % dt)
Learning the dictionary...
[MiniBatchKMeans] Reassigning 8 cluster centers.
[MiniBatchKMeans] Reassigning 5 cluster centers.
Partial fit of 100 out of 2400
[MiniBatchKMeans] Reassigning 3 cluster centers.
Partial fit of 200 out of 2400
[MiniBatchKMeans] Reassigning 1 cluster centers.
Partial fit of 300 out of 2400
[MiniBatchKMeans] Reassigning 3 cluster centers.
Partial fit of 400 out of 2400
Partial fit of 500 out of 2400
Partial fit of 600 out of 2400
Partial fit of 700 out of 2400
Partial fit of 800 out of 2400
Partial fit of 900 out of 2400
Partial fit of 1000 out of 2400
Partial fit of 1100 out of 2400
Partial fit of 1200 out of 2400
Partial fit of 1300 out of 2400
Partial fit of 1400 out of 2400
Partial fit of 1500 out of 2400
Partial fit of 1600 out of 2400
Partial fit of 1700 out of 2400
Partial fit of 1800 out of 2400
Partial fit of 1900 out of 2400
Partial fit of 2000 out of 2400
Partial fit of 2100 out of 2400
Partial fit of 2200 out of 2400
Partial fit of 2300 out of 2400
Partial fit of 2400 out of 2400
done in 1.38s.
繪製結果#
import matplotlib.pyplot as plt
plt.figure(figsize=(4.2, 4))
for i, patch in enumerate(kmeans.cluster_centers_):
plt.subplot(9, 9, i + 1)
plt.imshow(patch.reshape(patch_size), cmap=plt.cm.gray, interpolation="nearest")
plt.xticks(())
plt.yticks(())
plt.suptitle(
"Patches of faces\nTrain time %.1fs on %d patches" % (dt, 8 * len(faces.images)),
fontsize=16,
)
plt.subplots_adjust(0.08, 0.02, 0.92, 0.85, 0.08, 0.23)
plt.show()

腳本的總執行時間: (0 分鐘 2.729 秒)
相關範例