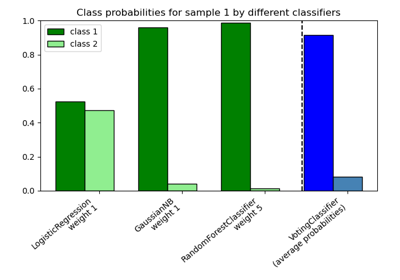
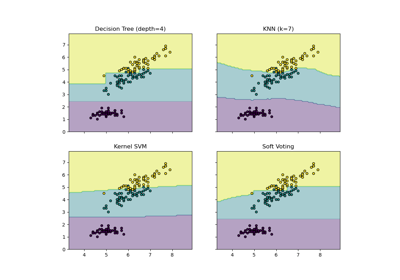
投票分類器#
- class sklearn.ensemble.VotingClassifier(estimators, *, voting='hard', weights=None, n_jobs=None, flatten_transform=True, verbose=False)[原始碼]#
用於未擬合估計器的軟投票/多數決分類器。
請參閱使用者指南以了解更多資訊。
於 0.17 版本加入。
- 參數:
- estimatorslist of (str, estimator) tuples
在
VotingClassifier上調用fit方法將會擬合這些原始估計器的複製品,這些複製品將會儲存在類別屬性self.estimators_中。可以使用set_params將估計器設定為'drop'。於 0.21 版本變更: 接受
'drop'。在 0.22 版本中已棄用使用 None,並在 0.24 版本中移除支援。- voting{‘hard’, ‘soft’}, default=’hard’
如果為 ‘hard’,則使用預測的類別標籤進行多數決投票。如果為 ‘soft’,則根據預測機率總和的最大值來預測類別標籤,建議將其用於良好校正分類器的集成。
- weightsarray-like of shape (n_classifiers,), default=None
權重序列(
float或int)用於權衡預測類別標籤的出現次數(hard投票)或平均之前的類別機率(soft投票)。如果為None,則使用均勻權重。- n_jobsint, default=None
用於
fit的平行執行作業數量。None表示 1,除非在joblib.parallel_backend內容中。-1表示使用所有處理器。請參閱詞彙表以了解更多詳情。於 0.18 版本加入。
- flatten_transformbool, default=True
僅當 voting=’soft’ 時影響 transform 輸出的形狀。如果 voting=’soft’ 且 flatten_transform=True,則 transform 方法返回形狀為 (n_samples, n_classifiers * n_classes) 的矩陣。如果 flatten_transform=False,則返回 (n_classifiers, n_samples, n_classes)。
- verbosebool, default=False
如果為 True,則在擬合完成時會印出所經過的時間。
於 0.23 版本加入。
- 屬性:
- estimators_list of classifiers
在
estimators中定義的擬合子估計器集合,且這些子估計器不是 ‘drop’。- named_estimators_
Bunch 透過名稱存取任何擬合子估計器的屬性。
於 0.20 版本加入。
- le_
LabelEncoder 用於在擬合期間編碼標籤並在預測期間解碼標籤的轉換器。
- classes_ndarray of shape (n_classes,)
類別標籤。
n_features_in_int在 fit 期間看到的特徵數量。
- feature_names_in_ndarray of shape (
n_features_in_,) 在 fit 期間看到的特徵名稱。僅在基礎估計器在擬合時公開此類屬性時定義。
於 1.0 版本加入。
另請參閱
VotingRegressor預測投票迴歸器。
範例
>>> import numpy as np >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.ensemble import RandomForestClassifier, VotingClassifier >>> clf1 = LogisticRegression(random_state=1) >>> clf2 = RandomForestClassifier(n_estimators=50, random_state=1) >>> clf3 = GaussianNB() >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> eclf1 = VotingClassifier(estimators=[ ... ('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='hard') >>> eclf1 = eclf1.fit(X, y) >>> print(eclf1.predict(X)) [1 1 1 2 2 2] >>> np.array_equal(eclf1.named_estimators_.lr.predict(X), ... eclf1.named_estimators_['lr'].predict(X)) True >>> eclf2 = VotingClassifier(estimators=[ ... ('lr', clf1), ('rf', clf2), ('gnb', clf3)], ... voting='soft') >>> eclf2 = eclf2.fit(X, y) >>> print(eclf2.predict(X)) [1 1 1 2 2 2]
若要刪除估計器,可以使用
set_params來移除它。在這裡,我們刪除了一個估計器,導致 2 個擬合的估計器>>> eclf2 = eclf2.set_params(lr='drop') >>> eclf2 = eclf2.fit(X, y) >>> len(eclf2.estimators_) 2
使用
voting='soft'設定flatten_transform=True會使transform的輸出形狀扁平化>>> eclf3 = VotingClassifier(estimators=[ ... ('lr', clf1), ('rf', clf2), ('gnb', clf3)], ... voting='soft', weights=[2,1,1], ... flatten_transform=True) >>> eclf3 = eclf3.fit(X, y) >>> print(eclf3.predict(X)) [1 1 1 2 2 2] >>> print(eclf3.transform(X).shape) (6, 6)
- fit(X, y, *, sample_weight=None, **fit_params)[原始碼]#
擬合估計器。
- 參數:
- X{類陣列, 稀疏矩陣},形狀為 (n_samples, n_features)
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。- y類陣列,形狀為 (n_samples,)
目標值。
- sample_weight類陣列,形狀為 (n_samples,),預設值為 None
樣本權重。如果為 None,則樣本的權重相等。請注意,只有在所有底層估計器都支援樣本權重時,才支援此功能。
於 0.18 版本加入。
- **fit_params字典
要傳遞給底層估計器的參數。
1.5 版本新增:僅在
enable_metadata_routing=True時可用,可透過使用sklearn.set_config(enable_metadata_routing=True)設定。請參閱 Metadata Routing 使用者指南 以取得更多詳細資訊。
- 回傳值:
- self物件
回傳實例本身。
- fit_transform(X, y=None, **fit_params)[原始碼]#
為每個估計器回傳類別標籤或機率。
為每個估計器回傳 X 的預測值。
- 參數:
- X{類陣列, 稀疏矩陣, 資料框},形狀為 (n_samples, n_features)
輸入樣本。
- yndarray,形狀為 (n_samples,),預設值為 None
目標值(對於非監督轉換為 None)。
- **fit_params字典
其他擬合參數。
- 回傳值:
- X_newndarray 陣列,形狀為 (n_samples, n_features_new)
轉換後的陣列。
- get_feature_names_out(input_features=None)[原始碼]#
取得轉換的輸出特徵名稱。
- 參數:
- input_features字串或 None 的類陣列,預設值為 None
不使用,此處僅為 API 一致性而存在。
- 回傳值:
- feature_names_out字串物件的 ndarray
轉換後的特徵名稱。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請檢查 使用者指南,瞭解路由機制如何運作。
1.5 版本新增。
- 回傳值:
- routingMetadataRouter
一個
MetadataRouter,封裝路由資訊。
- get_params(deep=True)[原始碼]#
從集成中取得估計器的參數。
回傳在建構函式中給定的參數,以及包含在
estimators參數中的估計器。- 參數:
- deep布林值,預設值為 True
將其設定為 True 會取得各種估計器以及估計器的參數。
- 回傳值:
- params字典
參數和估計器名稱對應到它們的值,或參數名稱對應到它們的值。
- predict(X)[原始碼]#
為 X 預測類別標籤。
- 參數:
- X{類陣列, 稀疏矩陣},形狀為 (n_samples, n_features)
輸入樣本。
- 回傳值:
- maj類陣列,形狀為 (n_samples,)
預測的類別標籤。
- predict_proba(X)[原始碼]#
計算 X 中樣本的可能結果的機率。
- 參數:
- X{類陣列, 稀疏矩陣},形狀為 (n_samples, n_features)
輸入樣本。
- 回傳值:
- avg類陣列,形狀為 (n_samples, n_classes)
每個樣本每個類別的加權平均機率。
- score(X, y, sample_weight=None)[原始碼]#
回傳在給定測試資料和標籤上的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為你需要每個樣本正確預測每個標籤集。
- 參數:
- X類陣列,形狀為 (n_samples, n_features)
測試樣本。
- y類陣列,形狀為 (n_samples,) 或 (n_samples, n_outputs)
X的真實標籤。- sample_weight類陣列,形狀為 (n_samples,),預設值為 None
樣本權重。
- 回傳值:
- score浮點數
self.predict(X)相對於y的平均準確度。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') VotingClassifier[原始碼]#
請求傳遞至
fit方法的中繼資料。請注意,只有在
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱關於路由機制如何運作的 使用者指南。每個參數的選項如下:
True:請求中繼資料,並在提供時傳遞至fit。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,並且元估計器不會將其傳遞至fit。None:不請求中繼資料,如果使用者提供,元估計器將會引發錯誤。str:中繼資料應使用此給定的別名傳遞至元估計器,而不是原始名稱。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這可讓您變更某些參數的請求,而不是其他參數。在 1.3 版本中新增。
注意
只有在此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline中使用。否則,它沒有任何作用。- 參數:
- sample_weightstr、True、False 或 None,預設值=sklearn.utils.metadata_routing.UNCHANGED
用於
fit中sample_weight參數的中繼資料路由。
- 回傳值:
- self物件
更新後的物件。
- set_output(*, transform=None)[原始碼]#
設定輸出容器。
請參閱 介紹 set_output API 以了解如何使用 API 的範例。
- 參數:
- transform{“default”, “pandas”, “polars”},預設值=None
設定
transform和fit_transform的輸出。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換設定保持不變
在 1.4 版本中新增:已新增
"polars"選項。
- 回傳值:
- self估計器實例
估計器實例。
- set_params(**params)[原始碼]#
設定集成中估計器的參數。
可以使用
get_params()列出有效的參數鍵。請注意,您可以直接設定estimators中包含的估計器的參數。- 參數:
- **params關鍵字引數
使用例如
set_params(parameter_name=new_value)的特定參數。此外,除了設定估計器的參數外,還可以設定或移除 estimators 的個別估計器,方法是將它們設定為 ‘drop’。
- 回傳值:
- self物件
估計器實例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') VotingClassifier[原始碼]#
請求傳遞至
score方法的中繼資料。請注意,只有在
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱關於路由機制如何運作的 使用者指南。每個參數的選項如下:
True:請求中繼資料,並在提供時傳遞至score。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,並且元估計器不會將其傳遞至score。None:不請求中繼資料,如果使用者提供,元估計器將會引發錯誤。str:中繼資料應使用此給定的別名傳遞至元估計器,而不是原始名稱。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這可讓您變更某些參數的請求,而不是其他參數。在 1.3 版本中新增。
注意
只有在此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline中使用。否則,它沒有任何作用。- 參數:
- sample_weightstr、True、False 或 None,預設值=sklearn.utils.metadata_routing.UNCHANGED
用於
score中sample_weight參數的中繼資料路由。
- 回傳值:
- self物件
更新後的物件。
- transform(X)[原始碼]#
為每個估計器返回 X 的類別標籤或機率。
- 參數:
- X{類陣列, 稀疏矩陣},形狀為 (n_samples, n_features)
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。
- 回傳值:
- probabilities_or_labels (機率或標籤)
- 如果
voting='soft'且flatten_transform=True 返回形狀為 (n_samples, n_classifiers * n_classes) 的 ndarray,其中包含每個分類器計算的類別機率。
- 如果
voting='soft' 且 `flatten_transform=False 形狀為 (n_classifiers, n_samples, n_classes) 的 ndarray
- 如果
voting='hard' 返回形狀為 (n_samples, n_classifiers) 的 ndarray,其中包含每個分類器預測的類別標籤。
- 如果