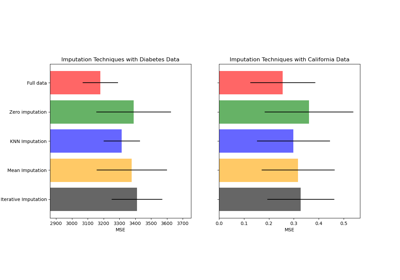
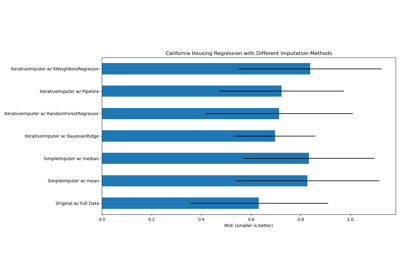
IterativeImputer#
- class sklearn.impute.IterativeImputer(estimator=None, *, missing_values=nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy='mean', fill_value=None, imputation_order='ascending', skip_complete=False, min_value=-inf, max_value=inf, verbose=0, random_state=None, add_indicator=False, keep_empty_features=False)[原始碼]#
多元插補器,會從所有其他特徵估計每個特徵。
一種通過以循環方式將每個具有缺失值的特徵建模為其他特徵的函數來插補缺失值的策略。
請在使用者指南中閱讀更多內容。
在 0.21 版本中新增。
注意
此估計器目前仍為實驗性:預測和 API 可能會在沒有任何棄用週期的情況下變更。若要使用它,您需要明確匯入
enable_iterative_imputer>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_iterative_imputer # noqa >>> # now you can import normally from sklearn.impute >>> from sklearn.impute import IterativeImputer
- 參數:
- estimator估計器物件,預設值=BayesianRidge()
在循環插補的每個步驟中使用的估計器。如果
sample_posterior=True,則估計器必須在其predict方法中支援return_std。- missing_valuesint 或 np.nan,預設值=np.nan
缺失值的預留位置。所有出現的
missing_values都將被插補。對於具有可為 Null 的整數 dtype 且具有缺失值的 pandas 資料框架,應將missing_values設定為np.nan,因為pd.NA將會轉換為np.nan。- sample_posteriorbool,預設值=False
是否從每個插補的已擬合估計器的(高斯)預測後驗分佈中取樣。如果設定為
True,則估計器必須在其predict方法中支援return_std。如果使用IterativeImputer進行多重插補,則設定為True。- max_iterint,預設值=10
在傳回最終回合中計算的插補之前,要執行的最大插補回合數。一回合是對每個具有缺失值的特徵進行單次插補。一旦滿足
max(abs(X_t - X_{t-1}))/max(abs(X[known_vals])) < tol停止條件,其中X_t是迭代t時的X。請注意,只有在sample_posterior=False時,才會應用提前停止。- tolfloat,預設值=1e-3
停止條件的容差。
- n_nearest_featuresint,預設值=None
用於估計每個特徵欄位缺失值的其他特徵數。特徵之間的接近程度是使用每個特徵對之間的絕對相關係數(在初始插補之後)來測量的。為了確保在整個插補過程中涵蓋特徵,鄰近特徵不一定是最近的,而是以與每個插補目標特徵的相關性成正比的機率抽取。當特徵數量龐大時,可以顯著加快速度。如果為
None,則將使用所有特徵。- initial_strategy{‘mean’、‘median’、‘most_frequent’、‘constant’},預設值=‘mean’
用於初始化缺失值的策略。與
SimpleImputer中的strategy參數相同。- fill_valuestr 或數值,預設值=None
當
strategy="constant"時,fill_value用於取代所有出現的 missing_values。對於字串或物件資料類型,fill_value必須是字串。如果為None,則在插補數值資料時,fill_value將為 0,而對於字串或物件資料類型,則為「missing_value」。在 1.3 版本中新增。
- imputation_order{‘ascending’、‘descending’、‘roman’、‘arabic’、‘random’},預設值=‘ascending’
將插補特徵的順序。可能的值
'ascending':從具有最少缺失值的特徵到最多缺失值的特徵。'descending':從具有最多缺失值的特徵到最少缺失值的特徵。'roman':從左到右。'arabic':從右到左。'random':每個回合的隨機順序。
- skip_completebool,預設值=False
如果為
True,則在transform期間具有缺失值,但在fit期間沒有任何缺失值的特徵,將僅使用初始插補方法進行插補。如果在fit和transform時有許多沒有缺失值的特徵,則設定為True以節省計算量。- min_valuefloat 或 array-like,形狀為 (n_features,),預設值為 -np.inf
最小可能的填補值。若為純量,則廣播為形狀
(n_features,)。若為 array-like,則期望形狀為(n_features,),每個特徵都有一個最小值。預設值為-np.inf。在 0.23 版本中變更:新增對 array-like 的支援。
- max_valuefloat 或 array-like,形狀為 (n_features,),預設值為 np.inf
最大可能的填補值。若為純量,則廣播為形狀
(n_features,)。若為 array-like,則期望形狀為(n_features,),每個特徵都有一個最大值。預設值為np.inf。在 0.23 版本中變更:新增對 array-like 的支援。
- verboseint,預設值為 0
詳細程度旗標,控制在評估函式時發出的除錯訊息。數值越高,訊息越詳細。可為 0、1 或 2。
- random_stateint、RandomState 實例或 None,預設值為 None
要使用的虛擬亂數產生器的種子。若
n_nearest_features不是None,則隨機化估算器特徵的選擇;若random,則隨機化imputation_order;若sample_posterior=True,則隨機化從後驗的取樣。使用整數以確保決定性。請參閱詞彙表。- add_indicatorbool,預設值為 False
若為
True,則MissingIndicator轉換將堆疊到填補器的轉換輸出。這允許預測估算器在填補後仍能考慮缺失值。若特徵在擬合/訓練時沒有缺失值,則即使在轉換/測試時有缺失值,該特徵也不會出現在缺失指標上。- keep_empty_featuresbool,預設值為 False
若為 True,則當呼叫
fit時,完全由缺失值組成的特徵會在呼叫transform時返回結果。填補值始終為0,除非當initial_strategy="constant"時,在這種情況下將改用fill_value。在 1.2 版本中新增。
- 屬性:
- initial_imputer_類型為
SimpleImputer的物件 用於初始化缺失值的填補器。
- imputation_sequence_元組列表
每個元組具有
(feat_idx, neighbor_feat_idx, estimator),其中feat_idx是當前要填補的特徵,neighbor_feat_idx是用於填補當前特徵的其他特徵的陣列,而estimator是用於填補的已訓練估算器。長度為self.n_features_with_missing_ * self.n_iter_。- n_iter_int
發生的迭代輪數。若達到提前停止條件,將小於
self.max_iter。- n_features_in_int
在 fit 期間看到的特徵數。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有都是字串的特徵名稱時才定義。在 1.0 版本中新增。
- n_features_with_missing_int
具有缺失值的特徵數。
- indicator_
MissingIndicator 用於為缺失值新增二元指標的指標。若
add_indicator=False,則為None。- random_state_RandomState 實例
從種子、亂數產生器或由
np.random產生的 RandomState 實例。
- initial_imputer_類型為
另請參閱
SimpleImputer使用簡單策略完成缺失值的單變量填補器。
KNNImputer使用最近樣本估計缺失特徵的多變量填補器。
注意事項
為了支援歸納模式中的填補,我們在
fit階段儲存每個特徵的估算器,並在transform階段按順序預測而不重新擬合。在
fit時包含所有缺失值的特徵會在transform時捨棄。使用預設值時,填補器會以 \(\mathcal{O}(knp^3\min(n,p))\) 的規模運作,其中 \(k\) =
max_iter,\(n\) 為樣本數,而 \(p\) 為特徵數。因此,當特徵數量增加時,其成本會變得非常高昂。設定n_nearest_features << n_features、skip_complete=True或增加tol可以協助降低其計算成本。根據缺失值的性質,在預測情況下,簡單的填補器可能更佳。
參考文獻
範例
>>> import numpy as np >>> from sklearn.experimental import enable_iterative_imputer >>> from sklearn.impute import IterativeImputer >>> imp_mean = IterativeImputer(random_state=0) >>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) IterativeImputer(random_state=0) >>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] >>> imp_mean.transform(X) array([[ 6.9584..., 2. , 3. ], [ 4. , 2.6000..., 6. ], [10. , 4.9999..., 9. ]])
如需更詳細的範例,請參閱 在建構估算器之前填補缺失值 或 使用 IterativeImputer 變體填補缺失值。
- fit(X, y=None, **fit_params)[原始碼]#
在
X上擬合填補器並返回 self。- 參數:
- Xarray-like,形狀為 (n_samples, n_features)
輸入資料,其中
n_samples是樣本數,而n_features是特徵數。- y忽略
未使用,依慣例為了 API 的一致性而存在。
- **fit_paramsdict
透過中繼資料路由 API 路由至子估算器的
fit方法的參數。在 1.5 版本中新增:僅當設定
sklearn.set_config(enable_metadata_routing=True)時才可用。如需更多詳細資訊,請參閱中繼資料路由使用者指南。
- 返回:
- self物件
已擬合的估算器。
- fit_transform(X, y=None, **params)[原始碼]#
在
X上擬合填補器並返回轉換後的X。- 參數:
- Xarray-like,形狀為 (n_samples, n_features)
輸入資料,其中
n_samples是樣本數,而n_features是特徵數。- y忽略
未使用,依慣例為了 API 的一致性而存在。
- **paramsdict
透過中繼資料路由 API 路由至子估算器的
fit方法的參數。在 1.5 版本中新增:僅當設定
sklearn.set_config(enable_metadata_routing=True)時才可用。如需更多詳細資訊,請參閱中繼資料路由使用者指南。
- 返回:
- Xtarray-like,形狀為 (n_samples, n_features)
已填補的輸入資料。
- get_feature_names_out(input_features=None)[原始碼]#
取得轉換的輸出特徵名稱。
- 參數:
- input_features字串或 None 的 array-like,預設值為 None
輸入特徵。
如果
input_features為None,則會使用feature_names_in_作為輸入特徵名稱。如果未定義feature_names_in_,則會產生以下輸入特徵名稱:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features為類陣列 (array-like),則如果已定義feature_names_in_,input_features必須與feature_names_in_相符。
- 返回:
- feature_names_outstr 物件的 ndarray
轉換後的特徵名稱。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查閱 使用者指南 以了解路由機制如何運作。
於 1.5 版新增。
- 返回:
- routingMetadataRouter
一個封裝路由資訊的
MetadataRouter。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
如果為 True,將傳回此估算器以及所包含的子物件(為估算器)的參數。
- 返回:
- paramsdict
參數名稱對應到其值。
- set_output(*, transform=None)[原始碼]#
設定輸出容器。
請參閱 介紹 set_output API 以了解如何使用 API 的範例。
- 參數:
- transform{“default”, “pandas”, “polars”},預設值為 None
設定
transform和fit_transform的輸出。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換設定保持不變
於 1.4 版新增:新增了
"polars"選項。
- 返回:
- self估算器實例
估算器實例。