classification_report#
- sklearn.metrics.classification_report(y_true, y_pred, *, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False, zero_division='warn')[來源]#
建立一個文字報告,顯示主要的分類指標。
請參閱使用者指南以瞭解更多資訊。
- 參數:
- y_true一維類陣列,或標籤指示器陣列/稀疏矩陣
真實(正確)的目標值。
- y_pred一維類陣列,或標籤指示器陣列/稀疏矩陣
分類器返回的預估目標。
- labels類陣列,形狀為 (n_labels,),預設為 None
可選的標籤索引列表,將包含在報告中。
- target_names類陣列,形狀為 (n_labels,),預設為 None
與標籤匹配的可選顯示名稱(順序相同)。
- sample_weight類陣列,形狀為 (n_samples,),預設為 None
樣本權重。
- digitsint,預設為 2
格式化輸出浮點數值的小數位數。當
output_dict為True時,此參數將被忽略,且返回的值不會被捨入。- output_dictbool,預設為 False
如果為 True,則以字典形式返回輸出。
在版本 0.20 中新增。
- zero_division{“warn”, 0.0, 1.0, np.nan},預設為 “warn”
設定當出現零除法時返回的值。如果設定為 “warn”,則行為如同 0,但也會引發警告。
在 1.3 版本中新增: 增加了
np.nan選項。
- 返回:
- reportstr 或 dict
每個類別的精確度、召回率、F1 分數的文字摘要。如果 output_dict 為 True,則返回字典。字典的結構如下
{'label 1': {'precision':0.5, 'recall':1.0, 'f1-score':0.67, 'support':1}, 'label 2': { ... }, ... }
報告的平均值包括巨平均 (macro average)(計算每個標籤的未加權平均值)、加權平均 (weighted average)(計算每個標籤的支援加權平均值)和樣本平均 (sample average)(僅適用於多標籤分類)。微平均 (micro average)(計算所有真正例、偽陰性和偽陽性的總和的平均值)僅針對具有子類別的多標籤或多類別顯示,因為否則它對應於準確度,且對於所有指標都相同。另請參閱
precision_recall_fscore_support以瞭解有關平均值的更多詳細資訊。請注意,在二元分類中,正類的召回率也稱為「靈敏度」;負類的召回率為「特異性」。
另請參閱
precision_recall_fscore_support計算每個類別的精確度、召回率、F 量測和支援度。
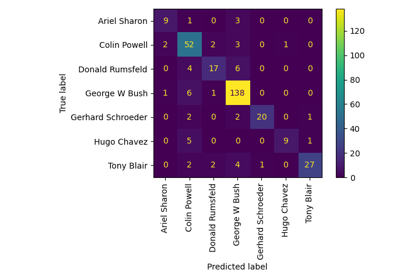
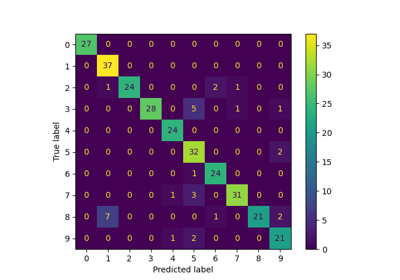
confusion_matrix計算混淆矩陣以評估分類的準確性。
multilabel_confusion_matrix計算每個類別或樣本的混淆矩陣。
範例
>>> from sklearn.metrics import classification_report >>> y_true = [0, 1, 2, 2, 2] >>> y_pred = [0, 0, 2, 2, 1] >>> target_names = ['class 0', 'class 1', 'class 2'] >>> print(classification_report(y_true, y_pred, target_names=target_names)) precision recall f1-score support class 0 0.50 1.00 0.67 1 class 1 0.00 0.00 0.00 1 class 2 1.00 0.67 0.80 3 accuracy 0.60 5 macro avg 0.50 0.56 0.49 5 weighted avg 0.70 0.60 0.61 5 >>> y_pred = [1, 1, 0] >>> y_true = [1, 1, 1] >>> print(classification_report(y_true, y_pred, labels=[1, 2, 3])) precision recall f1-score support 1 1.00 0.67 0.80 3 2 0.00 0.00 0.00 0 3 0.00 0.00 0.00 0 micro avg 1.00 0.67 0.80 3 macro avg 0.33 0.22 0.27 3 weighted avg 1.00 0.67 0.80 3