目標編碼器#
- class sklearn.preprocessing.TargetEncoder(categories='auto', target_type='auto', smooth='auto', cv=5, shuffle=True, random_state=None)[原始碼]#
用於迴歸和分類目標的目標編碼器。
每個類別的編碼都是基於屬於該類別的觀察值的平均目標值的縮減估計。編碼方案將全域目標均值與以類別值為條件的目標均值混合 (請參閱[MIC])。
當目標類型為「多類別」(multiclass) 時,編碼會基於每個類別的條件機率估計值。目標會先透過
LabelBinarizer使用「一對多」(one-vs-all) 方案進行二元化處理,然後使用每個類別和每個類別的平均目標值進行編碼,產生n_features*n_classes個編碼後的輸出特徵。TargetEncoder會將遺失值(例如np.nan或None)視為另一個類別,並像其他類別一樣進行編碼。在fit過程中未見過的類別會以目標平均值(即target_mean_)進行編碼。如需了解
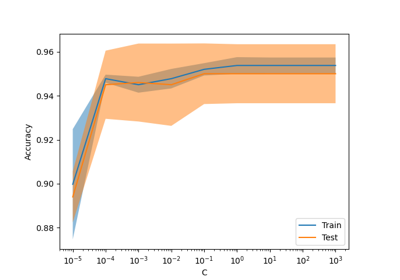
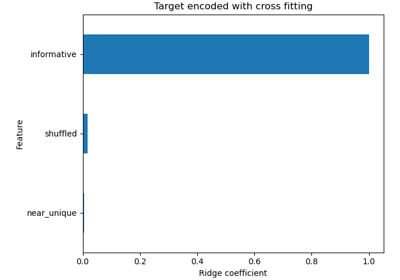
TargetEncoder內部交叉驗證重要性的示範,請參閱 目標編碼器的內部交叉驗證。如需比較不同編碼器,請參閱 比較目標編碼器與其他編碼器。請參閱使用者指南以了解更多資訊。1.3 版本新增。
- 參數:
- categories“auto” 或形狀為 (n_features,) 的類陣列列表,預設值為 “auto”
每個特徵的類別(唯一值)
"auto": 從訓練資料自動確定類別。list :
categories[i]保存第 i 個欄位中預期的類別。傳遞的類別不應在單一特徵內混合字串和數值,且在數值的情況下應排序。
使用的類別會儲存在已擬合的
categories_屬性中。- target_type{“auto”, “continuous”, “binary”, “multiclass”}, 預設值為 “auto”
目標類型。
"auto": 目標類型會使用type_of_target推斷。"continuous": 連續目標"binary": 二元目標"multiclass": 多類別目標
注意
使用
"auto"推斷的目標類型可能不是用於建模的所需目標類型。例如,如果目標包含介於 0 和 100 之間的整數,則type_of_target會將目標推斷為"multiclass"。在這種情況下,設定target_type="continuous"會指定目標為迴歸問題。target_type_屬性提供編碼器使用的目標類型。在 1.4 版本中變更:新增了 'multiclass' 選項。
- smooth“auto” 或浮點數,預設值為 “auto”
目標平均值在類別的值條件下與全域目標平均值混合的程度。較大的
smooth值會將更多權重放在全域目標平均值上。如果為"auto",則smooth會設定為經驗貝氏估計值。- cv整數,預設值為 5
決定 交叉驗證策略中,用於
fit_transform的折數。對於分類目標,會使用StratifiedKFold;對於連續目標,會使用KFold。- shuffle布林值,預設值為 True
是否在
fit_transform中將資料洗牌,然後再拆分為折。請注意,每個分割中的樣本不會洗牌。- random_state整數、RandomState 實例或 None,預設值為 None
當
shuffle為 True 時,random_state會影響索引的排序,進而控制每個折的隨機性。否則,此參數無效。傳遞一個整數可在多個函數呼叫中產生可重複的輸出。請參閱詞彙表。
- 屬性:
- encodings_形狀為 (n_features,) 或 (n_features * n_classes) 的 ndarray 列表
在所有的
X上學習到的編碼。對於特徵i,encodings_[i]是與categories_[i]中列出的類別相匹配的編碼。當target_type_為 “multiclass” 時,特徵i和類別j的編碼儲存在encodings_[j + (i * len(classes_))]中。例如,對於 2 個特徵 (f) 和 3 個類別 (c),編碼順序為:f0_c0, f0_c1, f0_c2, f1_c0, f1_c1, f1_c2,- categories_形狀為 (n_features,) 的 ndarray 列表
每個輸入特徵在擬合期間確定或在
categories中指定的類別(依照X中的特徵順序,並與transform的輸出相對應)。- target_type_str
目標類型。
- target_mean_float
目標變數的總體平均值。此值僅在
transform中用於編碼類別。- n_features_in_int
在 fit 期間看到的特徵數量。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。只有當
X具有全部為字串的特徵名稱時才定義。- classes_ndarray 或 None
如果
target_type_為 'binary' 或 'multiclass',則持有每個類別的標籤,否則為None。
另請參閱
對類別特徵執行獨熱編碼。這種非監督式編碼更適合低基數的類別變數,因為它會為每個獨特的類別生成一個新的特徵。範例
[MIC]
>>> import numpy as np >>> from sklearn.preprocessing import TargetEncoder >>> X = np.array([["dog"] * 20 + ["cat"] * 30 + ["snake"] * 38], dtype=object).T >>> y = [90.3] * 5 + [80.1] * 15 + [20.4] * 5 + [20.1] * 25 + [21.2] * 8 + [49] * 30 >>> enc_auto = TargetEncoder(smooth="auto") >>> X_trans = enc_auto.fit_transform(X, y)
>>> # A high `smooth` parameter puts more weight on global mean on the categorical >>> # encodings: >>> enc_high_smooth = TargetEncoder(smooth=5000.0).fit(X, y) >>> enc_high_smooth.target_mean_ np.float64(44...) >>> enc_high_smooth.encodings_ [array([44..., 44..., 44...])]
>>> # On the other hand, a low `smooth` parameter puts more weight on target >>> # conditioned on the value of the categorical: >>> enc_low_smooth = TargetEncoder(smooth=1.0).fit(X, y) >>> enc_low_smooth.encodings_ [array([20..., 80..., 43...])]
- Micci-Barreca, Daniele. “A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems” SIGKDD Explor. Newsl. 3, 1 (July 2001), 27–32.
當
smooth="auto"時,平滑參數會設定為經驗貝氏估計值- 參數:
- fit(X, y)[原始碼]#
將
TargetEncoder擬合到 X 和 y。- X形狀為 (n_samples, n_features) 的類陣列
用於確定每個特徵類別的數據。
- y形狀為 (n_samples,) 的類陣列
- 用於編碼類別的目標數據。
回傳:
- self物件
已擬合的編碼器。
- 參數:
- fit(X, y)[原始碼]#
將
TargetEncoder擬合到 X 和 y。- X形狀為 (n_samples, n_features) 的類陣列
用於確定每個特徵類別的數據。
- y形狀為 (n_samples,) 的類陣列
- 擬合
TargetEncoder並使用目標編碼轉換 X。 fit(X, y).transform(X)不等於fit_transform(X, y),因為fit_transform中使用了交叉擬合方案進行編碼。有關詳細資訊,請參閱 使用者指南。
- 擬合
- X_trans形狀為 (n_samples, n_features) 或 (n_samples, (n_features * n_classes)) 的 ndarray
轉換後的輸入。
- feature_names_outstr 物件的 ndarray
轉換後的特徵名稱。除非未定義,否則會使用
feature_names_in_,否則會產生以下輸入特徵名稱:["x0", "x1", ..., "x(n_features_in_ - 1)"]。當type_of_target_為 “multiclass” 時,名稱格式為 ‘<feature_name>_<class_name>’。- y形狀為 (n_samples,) 的類陣列
- 取得此物件的中繼資料路由。
請查看使用者指南,了解路由機制如何運作。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
若為 True,將回傳此估算器及其所包含之子物件(亦為估算器)的參數。
- y形狀為 (n_samples,) 的類陣列
- paramsdict
參數名稱對應到其值的字典。
- 屬性 infrequent_categories_#
每個特徵的稀有類別。
- set_output(*, transform=None)[原始碼]#
設定輸出容器。
請參考介紹 set_output API以了解如何使用此 API。
- 參數:
- transform{“default”, “pandas”, “polars”}, 預設值為 None
設定
transform和fit_transform的輸出格式。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換配置保持不變
在 1.4 版本中新增: 加入了
"polars"選項。
- y形狀為 (n_samples,) 的類陣列
- self估算器實例
估算器實例。
- set_params(**params)[原始碼]#
設定此估算器的參數。
此方法適用於簡單的估算器以及巢狀物件(例如
Pipeline)。後者具有<component>__<parameter>形式的參數,因此可以更新巢狀物件的每個組件。- 參數:
- **paramsdict
估算器參數。
- y形狀為 (n_samples,) 的類陣列
- self估算器實例
估算器實例。
- transform(X)[原始碼]#
使用目標編碼轉換 X。
- 參數:
- fit(X, y)[原始碼]#
將
TargetEncoder擬合到 X 和 y。
- y形狀為 (n_samples,) 的類陣列
- 擬合
TargetEncoder並使用目標編碼轉換 X。 fit(X, y).transform(X)不等於fit_transform(X, y),因為fit_transform中使用了交叉擬合方案進行編碼。有關詳細資訊,請參閱 使用者指南。
- 擬合