混淆矩陣#
- sklearn.metrics.confusion_matrix(y_true, y_pred, *, labels=None, sample_weight=None, normalize=None)[原始碼]#
計算混淆矩陣以評估分類的準確性。
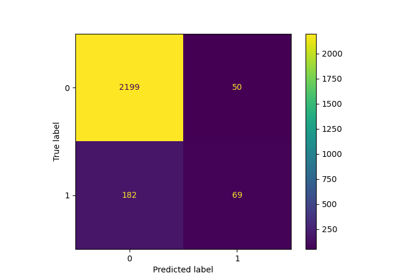
根據定義,混淆矩陣 \(C\) 使得 \(C_{i, j}\) 等於已知在組別 \(i\) 且預測為組別 \(j\) 的觀察數。
因此,在二元分類中,真陰性的計數是 \(C_{0,0}\),假陰性是 \(C_{1,0}\),真陽性是 \(C_{1,1}\),而假陽性是 \(C_{0,1}\)。
在使用者指南中閱讀更多資訊。
- 參數:
- y_true形狀為 (n_samples,) 的類陣列
真實(正確)目標值。
- y_pred形狀為 (n_samples,) 的類陣列
分類器返回的估計目標。
- labels形狀為 (n_classes) 的類陣列,預設值=None
用於索引矩陣的標籤列表。這可用於重新排序或選擇標籤的子集。如果給定
None,則將使用在y_true或y_pred中至少出現一次的標籤,並依排序順序排列。- sample_weight形狀為 (n_samples,) 的類陣列,預設值=None
樣本權重。
在 0.18 版本中新增。
- normalize{‘true’, ‘pred’, ‘all’},預設值=None
對真實(行)、預測(列)條件或所有母體的混淆矩陣進行正規化。如果為 None,則不會對混淆矩陣進行正規化。
- 返回:
- C形狀為 (n_classes, n_classes) 的 ndarray
混淆矩陣,其第 i 行和第 j 列的項目表示真實標籤為第 i 個類別且預測標籤為第 j 個類別的樣本數。
另請參閱
ConfusionMatrixDisplay.from_estimator繪製給定估算器、資料和標籤的混淆矩陣。
ConfusionMatrixDisplay.from_predictions繪製給定真實和預測標籤的混淆矩陣。
ConfusionMatrixDisplay混淆矩陣視覺化。
參考文獻
[1]混淆矩陣的維基百科條目(維基百科和其他參考資料可能會使用不同的軸慣例)。
範例
>>> from sklearn.metrics import confusion_matrix >>> y_true = [2, 0, 2, 2, 0, 1] >>> y_pred = [0, 0, 2, 2, 0, 2] >>> confusion_matrix(y_true, y_pred) array([[2, 0, 0], [0, 0, 1], [1, 0, 2]])
>>> y_true = ["cat", "ant", "cat", "cat", "ant", "bird"] >>> y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"] >>> confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"]) array([[2, 0, 0], [0, 0, 1], [1, 0, 2]])
在二元情況下,我們可以提取真陽性等,如下所示
>>> tn, fp, fn, tp = confusion_matrix([0, 1, 0, 1], [1, 1, 1, 0]).ravel() >>> (tn, fp, fn, tp) (np.int64(0), np.int64(2), np.int64(1), np.int64(1))