樣條轉換器#
- class sklearn.preprocessing.SplineTransformer(n_knots=5, degree=3, *, knots='uniform', extrapolation='constant', include_bias=True, order='C', sparse_output=False)[原始碼]#
為特徵產生單變量 B 樣條基底。
產生一個新的特徵矩陣,包含每個特徵的多項式階數為 `degree` 的 `n_splines=n_knots + degree - 1` (當 `extrapolation="periodic"` 時為 `n_knots - 1`) 樣條基底函數(B 樣條)。
如要了解更多關於 SplineTransformer 類別的資訊,請前往:時間相關特徵工程
請參閱使用者指南以了解更多。
1.0 版本新增。
- 參數:
- n_knotsint,預設值=5
如果 `knots` 等於 {'uniform', 'quantile'} 其中之一,則為樣條的結點數量。必須大於或等於 2。如果 `knots` 是類陣列,則忽略此參數。
- degreeint,預設值=3
樣條基底的多項式階數。必須是非負整數。
- knots{'uniform', 'quantile'} 或形狀為 (n_knots, n_features) 的類陣列,預設值='uniform'
設定結點位置,使得第一個結點 <= 特徵 <= 最後一個結點。
如果為 'uniform',則將 `n_knots` 個結點從特徵的最小值到最大值均勻分佈。
如果為 'quantile',則它們沿著特徵的分位數均勻分佈。
如果給定類陣列,則它直接指定排序後的結點位置,包括邊界結點。請注意,在內部,在第一個結點之前會加入 `degree` 個結點,在最後一個結點之後會加入相同的結點數。
- extrapolation{'error', 'constant', 'linear', 'continue', 'periodic'},預設值='constant'
如果為 'error',則超出訓練特徵最小值和最大值的值將引發 `ValueError`。如果為 'constant',則使用特徵最小值和最大值處的樣條值作為常數外插。如果為 'linear',則使用線性外插。如果為 'continue',則樣條會按原樣外插,即在
scipy.interpolate.BSpline中使用 `extrapolate=True` 選項。如果為 'periodic',則使用週期性樣條,其週期等於第一個結點和最後一個結點之間的距離。週期性樣條在第一個和最後一個結點處強制執行相等的函數值和導數。例如,這使得有可能避免在從自然週期性的「一年中的某一天」輸入特徵派生的樣條特徵中,在 12 月 31 日和 1 月 1 日之間引入任意跳躍。在這種情況下,建議手動設定結點值以控制週期。- include_biasbool,預設值=True
如果為 False,則會捨棄特徵資料範圍內最後一個樣條元素。由於 B 樣條在每個資料點的樣條基底函數上總和為 1,因此它們隱含地包含偏差項,即一個由 1 組成的列。它在線性模型中充當截距項。
- order{'C', 'F'},預設值='C'
在密集情況下,輸出陣列的順序。`'F'` 順序計算速度更快,但可能會減慢後續估算器的速度。
- sparse_outputbool,預設值=False
如果設定為 True,將返回稀疏 CSR 矩陣,否則將返回陣列。此選項僅適用於 `scipy>=1.8`。
1.2 版本新增。
- 屬性:
- bsplines_形狀為 (n_features,) 的列表
BSplines 物件的列表,每個特徵一個。
- n_features_in_int
輸入特徵的總數。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 擬合 期間看到的特徵名稱。僅當 `X` 具有全部為字串的特徵名稱時才定義。
1.0 版本新增。
- n_features_out_int
輸出特徵的總數,計算方式為 `n_features * n_splines`,其中 `n_splines` 是 B 樣條的基底元素數量,對於非週期性樣條,`n_knots + degree - 1`,對於週期性樣條,`n_knots - 1`。如果 `include_bias=False`,則僅為 `n_features * (n_splines - 1)`。
另請參閱
K 個分箱離散化器 (KBinsDiscretizer)將連續資料分箱為區間的轉換器。
多項式特徵 (PolynomialFeatures)產生多項式和交互特徵的轉換器。
注意
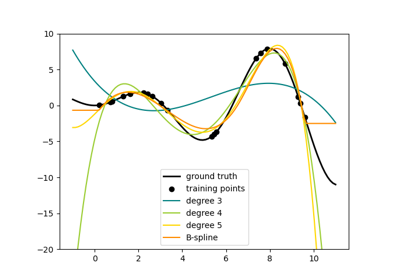
高階數和大量結點可能導致過擬合。
請參閱 examples/linear_model/plot_polynomial_interpolation.py。
範例
>>> import numpy as np >>> from sklearn.preprocessing import SplineTransformer >>> X = np.arange(6).reshape(6, 1) >>> spline = SplineTransformer(degree=2, n_knots=3) >>> spline.fit_transform(X) array([[0.5 , 0.5 , 0. , 0. ], [0.18, 0.74, 0.08, 0. ], [0.02, 0.66, 0.32, 0. ], [0. , 0.32, 0.66, 0.02], [0. , 0.08, 0.74, 0.18], [0. , 0. , 0.5 , 0.5 ]])
- fit(X, y=None, sample_weight=None)[原始碼]#
計算樣條的結點位置。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
資料。
- yNone
已忽略。
- sample_weight形狀為 (n_samples,) 的類陣列,預設值 = None
每個樣本的個別權重。如果
knots="quantile",則用於計算分位數。對於knots="uniform",會忽略權重為零的觀測值,以尋找X的最小值和最大值。
- 回傳:
- self物件
擬合的轉換器。
- fit_transform(X, y=None, **fit_params)[來源]#
將資料擬合,然後轉換。
使用選用參數
fit_params將轉換器擬合到X和y,並回傳X的轉換版本。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列,預設值為 None
目標值(無監督轉換為 None)。
- **fit_params字典
額外的擬合參數。
- 回傳:
- X_new形狀為 (n_samples, n_features_new) 的 ndarray 陣列
已轉換的陣列。
- get_feature_names_out(input_features=None)[來源]#
取得轉換的輸出特徵名稱。
- 參數:
- input_features字串或 None 的類陣列,預設值為 None
輸入特徵。
如果
input_features為None,則會使用feature_names_in_作為輸入特徵名稱。如果未定義feature_names_in_,則會產生下列輸入特徵名稱:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features為類陣列,則如果定義了feature_names_in_,input_features必須符合feature_names_in_。
- 回傳:
- feature_names_out字串物件的 ndarray
已轉換的特徵名稱。
- get_metadata_routing()[來源]#
取得此物件的中繼資料路由。
請查看關於路由機制如何運作的使用者指南。
- 回傳:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[來源]#
取得此估計器的參數。
- 參數:
- deep布林值,預設值為 True
如果為 True,則會回傳此估計器的參數和包含的子物件(估計器)。
- 回傳:
- params字典
對應到其值的參數名稱。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SplineTransformer[來源]#
請求傳遞給
fit方法的中繼資料。請注意,只有在
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請查看關於路由機制如何運作的使用者指南。每個參數的選項為
True:請求中繼資料,如果提供,則傳遞給fit。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,而且元估計器不會將其傳遞給fit。None:不請求中繼資料,如果使用者提供,則元估計器會引發錯誤。str:應使用此指定的別名,而不是原始名稱,將中繼資料傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這可讓您變更某些參數的請求,而不要變更其他參數的請求。在 1.3 版中新增。
注意
只有當此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline內使用。否則,它沒有任何作用。- 參數:
- sample_weight字串、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight參數的中繼資料路由。
- 回傳:
- self物件
更新的物件。
- set_output(*, transform=None)[來源]#
設定輸出容器。
請參閱 「設定輸出 API」簡介,以取得如何使用 API 的範例。
- 參數:
- transform{“預設”, “pandas”, “polars”},預設值為 None
設定
transform和fit_transform的輸出。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換設定未變更
在 1.4 版中新增:新增了
"polars"選項。
- 回傳:
- self估計器實例
估計器實例。