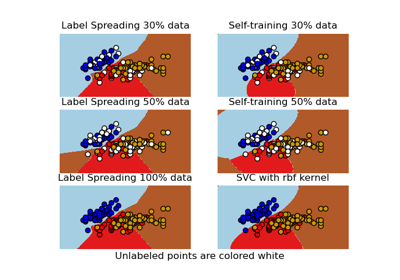
LabelSpreading#
- class sklearn.semi_supervised.LabelSpreading(kernel='rbf', *, gamma=20, n_neighbors=7, alpha=0.2, max_iter=30, tol=0.001, n_jobs=None)[原始碼]#
用於半監督學習的 LabelSpreading 模型。
此模型類似於基本的標籤傳播演算法,但使用基於正規化圖拉普拉斯算子的親和力矩陣,並在標籤之間進行軟鉗位。
請在使用者指南中閱讀更多資訊。
- 參數:
- kernel{‘knn’, ‘rbf’} 或可呼叫物件,預設值 = ‘rbf’
要使用的核心函數的字串識別碼,或核心函數本身。僅 ‘rbf’ 和 ‘knn’ 字串為有效輸入。傳遞的函數應接收兩個輸入,每個輸入的形狀為 (n_samples, n_features),並回傳形狀為 (n_samples, n_samples) 的權重矩陣。
- gamma浮點數,預設值 = 20
rbf 核心的參數。
- n_neighbors整數,預設值 = 7
knn 核心的參數,必須為嚴格正整數。
- alpha浮點數,預設值 = 0.2
鉗位因子。介於 (0, 1) 之間的值,指定實例應從其鄰居採用資訊的相對量,而不是其初始標籤。 alpha=0 表示保留初始標籤資訊; alpha=1 表示取代所有初始資訊。
- max_iter整數,預設值 = 30
允許的最大迭代次數。
- tol浮點數,預設值 = 1e-3
收斂容差:將系統視為穩態的閾值。
- n_jobs整數,預設值 = None
要執行的平行工作數。
None表示 1,除非在joblib.parallel_backend環境中。-1表示使用所有處理器。有關詳細資訊,請參閱詞彙表。
- 屬性:
- X_形狀為 (n_samples, n_features) 的 ndarray
輸入陣列。
- classes_形狀為 (n_classes,) 的 ndarray
用於分類實例的不同標籤。
- label_distributions_形狀為 (n_samples, n_classes) 的 ndarray
每個項目的類別分佈。
- transduction_形狀為 (n_samples,) 的 ndarray
在fit期間分配給每個項目的標籤。
- n_features_in_整數
在fit期間看到的特徵數量。
在版本 0.24 中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在fit期間看到的特徵名稱。僅在
X具有全部為字串的特徵名稱時定義。在版本 1.0 中新增。
- n_iter_整數
執行的迭代次數。
另請參閱
LabelPropagation基於無正規化圖的半監督學習。
參考文獻
範例
>>> import numpy as np >>> from sklearn import datasets >>> from sklearn.semi_supervised import LabelSpreading >>> label_prop_model = LabelSpreading() >>> iris = datasets.load_iris() >>> rng = np.random.RandomState(42) >>> random_unlabeled_points = rng.rand(len(iris.target)) < 0.3 >>> labels = np.copy(iris.target) >>> labels[random_unlabeled_points] = -1 >>> label_prop_model.fit(iris.data, labels) LabelSpreading(...)
- fit(X, y)[原始碼]#
將半監督標籤傳播模型擬合到 X。
輸入樣本(已標記和未標記)由矩陣 X 提供,目標標籤由矩陣 y 提供。我們慣例上在半監督分類中將標籤 -1 應用於矩陣 y 中的未標記樣本。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列, 稀疏矩陣}
訓練資料,其中
n_samples是樣本數,n_features是特徵數。- y形狀為 (n_samples,) 的類陣列
目標類別值,其中未標記點標記為 -1。所有未標記的樣本都將在內部以傳導方式分配標籤,這些標籤儲存在
transduction_中。
- 回傳值:
- self物件
回傳實例本身。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,了解路由機制的運作方式。
- 回傳值:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deep布林值,預設值 = True
如果為 True,將回傳此估算器的參數和包含的子物件(為估算器)。
- 回傳值:
- params字典
對應到其值的參數名稱。
- predict(X)[原始碼]#
在模型中執行歸納推論。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
資料矩陣。
- 回傳值:
- y形狀為 (n_samples,) 的 ndarray
輸入資料的預測結果。
- predict_proba(X)[來源]#
預測每個可能結果的機率。
計算 X 中每個單一樣本以及訓練期間看到的每個可能結果(類別分佈)的機率估計值。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
資料矩陣。
- 回傳值:
- probabilities形狀為 (n_samples, n_classes) 的 ndarray
跨類別標籤的正規化機率分佈。
- score(X, y, sample_weight=None)[來源]#
回傳在給定的測試資料和標籤上的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為您需要每個樣本的每個標籤集都被正確預測。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
測試樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列 (array-like)
X的真實標籤。- sample_weight形狀為 (n_samples,) 的類陣列 (array-like),預設值為 None
樣本權重。
- 回傳值:
- scorefloat
self.predict(X)相對於y的平均準確度。
- set_params(**params)[來源]#
設定此估算器的參數。
此方法適用於簡單的估算器以及巢狀物件(例如
Pipeline)。後者具有<元件>__<參數>形式的參數,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估算器參數。
- 回傳值:
- self估算器實例
估算器實例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LabelSpreading[來源]#
請求傳遞給
score方法的中繼資料。請注意,只有在
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱關於路由機制如何運作的使用者指南。每個參數的選項為
True:請求中繼資料,如果提供,則傳遞給score。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,並且 meta-estimator 不會將其傳遞給score。None:不請求中繼資料,如果使用者提供,則 meta-estimator 會引發錯誤。str:應將中繼資料傳遞給具有此指定別名(而不是原始名稱)的 meta-estimator。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這可讓您變更某些參數的請求,而不要變更其他參數的請求。在 1.3 版本中新增。
注意
只有在將此估算器用作 meta-estimator 的子估算器時(例如,在
Pipeline內使用),此方法才相關。否則沒有效果。- 參數:
- sample_weightstr、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight參數的中繼資料路由。
- 回傳值:
- self物件
更新後的物件。