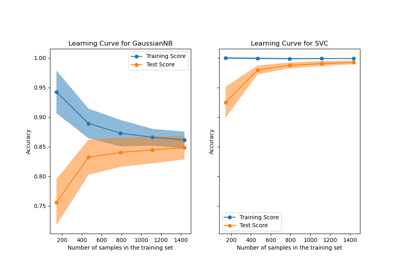
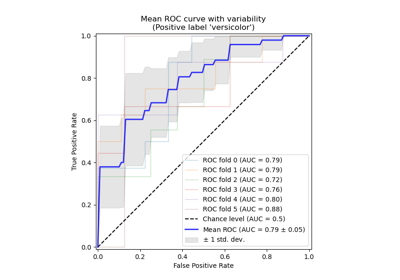
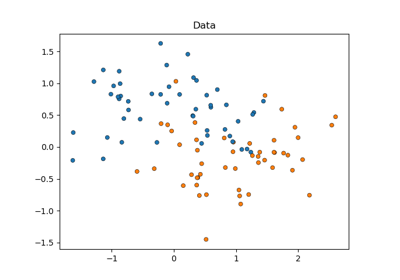
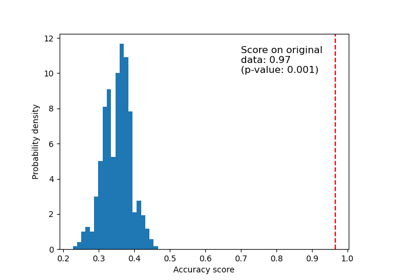
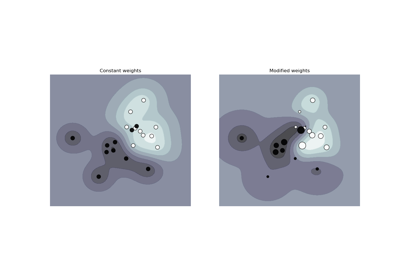
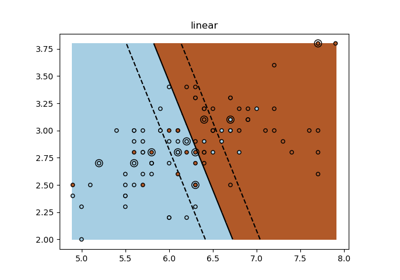
支援向量分類器 (SVC)#
- class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)[原始碼]#
C 支援向量分類器。
此實作基於 libsvm。擬合時間至少與樣本數量呈平方關係,且對於超過數萬個樣本可能不切實際。對於大型資料集,請考慮改用
LinearSVC或SGDClassifier,可能在經過Nystroem轉換器或其他核函數近似之後。多類別支援是根據一對一的方案處理的。
有關提供的核函數的精確數學公式以及
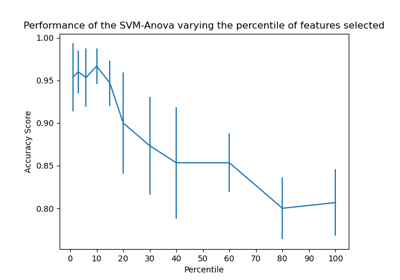
gamma、coef0和degree如何相互影響的詳細資訊,請參閱敘述文件中的相應章節:核函數。要了解如何調整 SVC 的超參數,請參閱以下範例:巢狀與非巢狀交叉驗證
請在使用者指南中閱讀更多資訊。
- 參數:
- Cfloat,預設值=1.0
正規化參數。正規化的強度與 C 成反比。必須為嚴格正值。懲罰是平方 l2 懲罰。如需正規化參數 C 縮放效果的直觀視覺化,請參閱縮放 SVC 的正規化參數。
- kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} 或 callable,預設值='rbf'
指定演算法中要使用的核函數類型。如果未提供,將使用 'rbf'。如果提供了 callable,則用它從資料矩陣預先計算核函數矩陣;該矩陣應為形狀
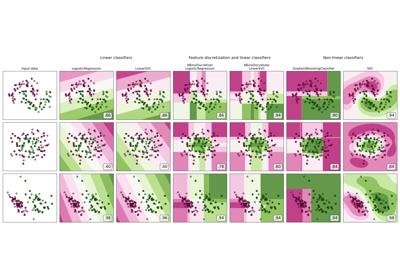
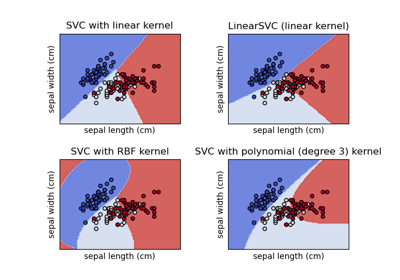
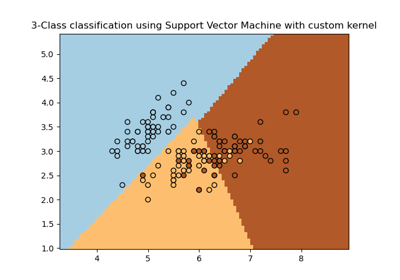
(n_samples, n_samples)的陣列。如需不同核函數類型的直觀視覺化,請參閱繪製具有不同 SVM 核函數的分類邊界。- degreeint,預設值=3
多項式核函數 ('poly') 的次數。必須為非負數。所有其他核函數都會忽略此參數。
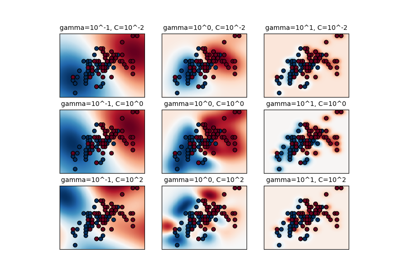
- gamma{‘scale’, ‘auto’} 或 float,預設值='scale'
'rbf'、'poly' 和 'sigmoid' 的核函數係數。
如果傳遞
gamma='scale'(預設),則使用 1 / (n_features * X.var()) 作為 gamma 的值,如果為 ‘auto’,則使用 1 / n_features
如果為 float,則必須為非負數。
在 0.22 版中變更:
gamma的預設值從 'auto' 變更為 'scale'。- coef0float,預設值=0.0
核函數中的獨立項。僅在 'poly' 和 'sigmoid' 中有效。
- shrinkingbool,預設值=True
是否使用縮減啟發式演算法。請參閱使用者指南。
- probabilitybool,預設值=False
是否啟用機率估計。必須先啟用此選項,才能呼叫
fit,這會減慢該方法的速度,因為它會在內部使用 5 折交叉驗證,而且predict_proba可能與predict不一致。請在使用者指南中閱讀更多資訊。- tolfloat,預設值=1e-3
停止準則的容差。
- cache_sizefloat,預設值=200
指定核心快取的大小 (以 MB 為單位)。
- class_weightdict 或 ‘balanced’,預設值=None
為 SVC 設定類別 i 的參數 C 為 class_weight[i]*C。若未提供,則所有類別的權重都假設為 1。「balanced」模式使用 y 的值自動調整權重,使其與輸入資料中類別頻率成反比,計算方式為
n_samples / (n_classes * np.bincount(y))。- verbosebool,預設值為 False
啟用詳細輸出。請注意,此設定利用 libsvm 中每個程序的執行階段設定,如果啟用,可能無法在多執行緒環境中正常運作。
- max_iterint,預設值為 -1
求解器內部的迭代次數硬性限制,-1 表示沒有限制。
- decision_function_shape{‘ovo’, ‘ovr’},預設值為 ‘ovr’
決定是否要像其他分類器一樣,回傳形狀為 (n_samples, n_classes) 的「一對其餘」(one-vs-rest, ‘ovr’) 決策函數,或是回傳 libsvm 原本形狀為 (n_samples, n_classes * (n_classes - 1) / 2) 的「一對一」(one-vs-one, ‘ovo’) 決策函數。然而,請注意,在內部,始終使用「一對一」(‘ovo’) 作為多類別策略來訓練模型;ovr 矩陣僅從 ovo 矩陣建構而來。此參數在二元分類中會被忽略。
在版本 0.19 中變更:decision_function_shape 的預設值為 ‘ovr’。
在版本 0.17 中新增:建議使用 *decision_function_shape=’ovr’*。
在版本 0.17 中變更:已棄用 *decision_function_shape=’ovo’ 和 None*。
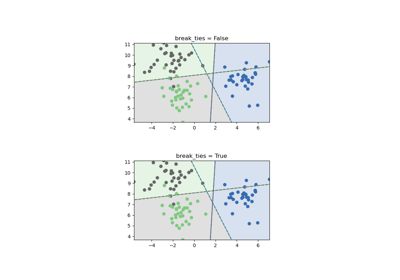
- break_tiesbool,預設值為 False
如果為 true,
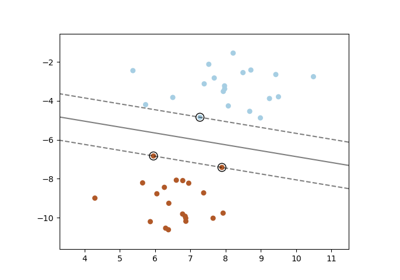
decision_function_shape='ovr',且類別數量 > 2,predict 將根據 decision_function 的信賴度值來打破平局;否則會回傳平局類別中的第一個類別。請注意,與簡單的 predict 相比,打破平局的計算成本相對較高。請參閱 SVM 平局打破範例,了解其與decision_function_shape='ovr'一起使用的範例。在版本 0.22 中新增。
- random_stateint、RandomState 實例或 None,預設值為 None
控制用於機率估計的資料洗牌的偽隨機數字產生。當
probability為 False 時會被忽略。傳遞一個 int 以便在多次函數呼叫中產生可重複的輸出。請參閱詞彙表。
- 屬性:
- class_weight_形狀為 (n_classes,) 的 ndarray
每個類別的參數 C 的乘數。根據
class_weight參數計算得出。- classes_形狀為 (n_classes,) 的 ndarray
類別標籤。
coef_形狀為 (n_classes * (n_classes - 1) / 2, n_features) 的 ndarray當
kernel="linear"時,分配給特徵的權重。- dual_coef_形狀為 (n_classes -1, n_SV) 的 ndarray
決策函數中支持向量的對偶係數(請參閱 數學公式),乘以其目標值。對於多類別,所有 1 對 1 分類器的係數。多類別情況下係數的佈局有些複雜。請參閱使用者指南的多類別章節,以了解詳細資訊。
- fit_status_int
如果正確擬合,則為 0,否則為 1(會引發警告)
- intercept_形狀為 (n_classes * (n_classes - 1) / 2,) 的 ndarray
決策函數中的常數。
- n_features_in_int
在 fit 期間看到的特徵數量。
在版本 0.24 中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有全部為字串的特徵名稱時才定義。在版本 1.0 中新增。
- n_iter_形狀為 (n_classes * (n_classes - 1) // 2,) 的 ndarray
最佳化程序執行以擬合模型的迭代次數。此屬性的形狀取決於最佳化的模型數量,而模型數量又取決於類別數量。
在版本 1.1 中新增。
- support_形狀為 (n_SV) 的 ndarray
支持向量的索引。
- support_vectors_形狀為 (n_SV, n_features) 的 ndarray
支持向量。如果核心是預先計算的,則為空陣列。
n_support_形狀為 (n_classes,),dtype=int32 的 ndarray每個類別的支持向量數量。
probA_形狀為 (n_classes * (n_classes - 1) / 2) 的 ndarray當
probability=True時,在 Platt 縮放中學習的參數。probB_形狀為 (n_classes * (n_classes - 1) / 2) 的 ndarray當
probability=True時,在 Platt 縮放中學習的參數。- shape_fit_形狀為 (n_dimensions_of_X,) 的 int 元組
訓練向量
X的陣列維度。
另請參閱
支援向量迴歸 (SVR)使用 libsvm 實作的迴歸支持向量機。
線性支援向量分類 (LinearSVC)使用 liblinear 實作的可擴展線性支持向量機,用於分類。請查看 LinearSVC 的「另請參閱」章節以取得更多比較元素。
參考文獻
範例
>>> import numpy as np >>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) >>> y = np.array([1, 1, 2, 2]) >>> from sklearn.svm import SVC >>> clf = make_pipeline(StandardScaler(), SVC(gamma='auto')) >>> clf.fit(X, y) Pipeline(steps=[('standardscaler', StandardScaler()), ('svc', SVC(gamma='auto'))])
>>> print(clf.predict([[-0.8, -1]])) [1]
如需將 SVC 與其他分類器進行比較,請參閱:繪製分類機率。
- property coef_#
當
kernel="linear"時,分配給特徵的權重。- 回傳:
- 形狀為 (n_features, n_classes) 的 ndarray
- decision_function(X)[原始碼]#
評估 X 中樣本的決策函數。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
輸入樣本。
- 回傳:
- X形狀為 (n_samples, n_classes * (n_classes-1) / 2) 的 ndarray
返回模型中每個類別的樣本決策函數。如果 decision_function_shape='ovr',則形狀為 (n_samples, n_classes)。
註解
如果 decision_function_shape='ovo',函數值與樣本 X 到分隔超平面的距離成正比。如果需要精確的距離,請將函數值除以權重向量的範數 (
coef_)。有關更多詳細資訊,另請參閱這個問題。如果 decision_function_shape='ovr',則決策函數是 ovo 決策函數的單調轉換。
- fit(X, y, sample_weight=None)[原始碼]#
根據給定的訓練資料擬合 SVM 模型。
- 參數:
- X形狀為 (n_samples, n_features) 或 (n_samples, n_samples) 的 {類陣列 (array-like), 稀疏矩陣}
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。對於 kernel="precomputed",X 的預期形狀為 (n_samples, n_samples)。- y形狀為 (n_samples,) 的類陣列 (array-like)
目標值 (分類中的類別標籤,回歸中的實數)。
- sample_weight形狀為 (n_samples,) 的類陣列 (array-like),預設值為 None
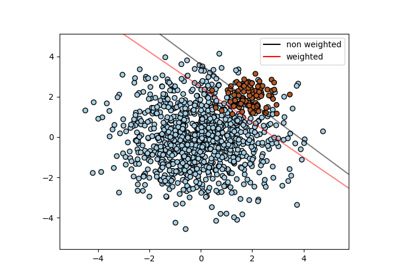
每個樣本的權重。按樣本重新縮放 C。較高的權重會迫使分類器更重視這些點。
- 回傳:
- self物件
擬合的估計器。
註解
如果 X 和 y 不是 C 順序且連續的 np.float64 陣列,並且 X 不是 scipy.sparse.csr_matrix,則可能會複製 X 和/或 y。
如果 X 是密集陣列,則其他方法將不支援稀疏矩陣作為輸入。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請檢查使用者指南,瞭解路由機制如何運作。
- 回傳:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設值為 True
如果為 True,將傳回此估計器和包含的子物件 (屬於估計器) 的參數。
- 回傳:
- paramsdict
參數名稱對應到其值。
- property n_support_#
每個類別的支持向量數量。
- predict(X)[原始碼]#
對 X 中的樣本執行分類。
對於單類模型,會傳回 +1 或 -1。
- 參數:
- X形狀為 (n_samples, n_features) 或 (n_samples_test, n_samples_train) 的 {類陣列 (array-like), 稀疏矩陣}
對於 kernel="precomputed",X 的預期形狀為 (n_samples_test, n_samples_train)。
- 回傳:
- y_pred形狀為 (n_samples,) 的 ndarray
X 中樣本的類別標籤。
- predict_log_proba(X)[原始碼]#
計算 X 中樣本可能結果的對數機率。
模型需要在訓練時計算機率資訊:將屬性
probability設定為 True 來進行擬合。- 參數:
- X形狀為 (n_samples, n_features) 或 (n_samples_test, n_samples_train) 的類陣列 (array-like)
對於 kernel="precomputed",X 的預期形狀為 (n_samples_test, n_samples_train)。
- 回傳:
- T形狀為 (n_samples, n_classes) 的 ndarray
傳回模型中每個類別樣本的對數機率。各列對應到類別的排序順序,如同它們在屬性 classes_ 中顯示的順序。
註解
機率模型是使用交叉驗證建立的,因此結果可能與 predict 取得的結果略有不同。此外,它會在非常小的資料集上產生無意義的結果。
- predict_proba(X)[原始碼]#
計算 X 中樣本可能結果的機率。
模型需要在訓練時計算機率資訊:將屬性
probability設定為 True 來進行擬合。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
對於 kernel="precomputed",X 的預期形狀為 (n_samples_test, n_samples_train)。
- 回傳:
- T形狀為 (n_samples, n_classes) 的 ndarray
傳回模型中每個類別的樣本機率。各列對應到類別的排序順序,如同它們在屬性 classes_ 中顯示的順序。
註解
機率模型是使用交叉驗證建立的,因此結果可能與 predict 取得的結果略有不同。此外,它會在非常小的資料集上產生無意義的結果。
- property probA_#
當
probability=True時,在 Platt 縮放中學習的參數。- 回傳:
- 形狀為 (n_classes * (n_classes - 1) / 2) 的 ndarray
- property probB_#
當
probability=True時,在 Platt 縮放中學習的參數。- 回傳:
- 形狀為 (n_classes * (n_classes - 1) / 2) 的 ndarray
- score(X, y, sample_weight=None)[原始碼]#
傳回給定測試資料和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為您需要每個樣本的每個標籤集都被正確預測。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
測試樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列 (array-like)
用於
X的真實標籤。- sample_weight形狀為 (n_samples,) 的類陣列 (array-like),預設值為 None
樣本權重。
- 回傳:
- score浮點數 (float)
相對於
y的self.predict(X)的平均準確度。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[原始碼]#
請求傳遞給
fit方法的中繼資料。請注意,只有當
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱 使用者指南,了解路由機制如何運作。每個參數的選項如下:
True:請求中繼資料,並在提供時傳遞給fit。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,且元估計器 (meta-estimator) 不會將其傳遞給fit。None:不請求中繼資料,且如果使用者提供中繼資料,則元估計器會引發錯誤。str:中繼資料應使用給定的別名而不是原始名稱傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這允許您變更某些參數的請求,而不變更其他參數的請求。於 1.3 版本新增。
注意
只有當此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline中使用。否則它沒有效果。- 參數:
- sample_weight字串、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight參數的中繼資料路由。
- 回傳:
- self物件
更新後的物件。
- set_params(**params)[原始碼]#
設定此估計器的參數。
此方法適用於簡單的估計器以及巢狀物件(例如
Pipeline)。後者具有<component>__<parameter>形式的參數,因此可以更新巢狀物件的每個組件。- 參數:
- **params字典 (dict)
估計器參數。
- 回傳:
- self估計器執行個體
估計器執行個體。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[原始碼]#
請求傳遞給
score方法的中繼資料。請注意,只有當
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱 使用者指南,了解路由機制如何運作。每個參數的選項如下:
True:請求中繼資料,並在提供時傳遞給score。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,且元估計器不會將其傳遞給score。None:不請求中繼資料,且如果使用者提供中繼資料,則元估計器會引發錯誤。str:中繼資料應使用給定的別名而不是原始名稱傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這允許您變更某些參數的請求,而不變更其他參數的請求。於 1.3 版本新增。
注意
只有當此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline中使用。否則它沒有效果。- 參數:
- sample_weight字串、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight參數的中繼資料路由。
- 回傳:
- self物件
更新後的物件。