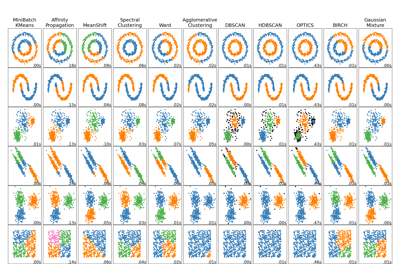
OPTICS#
- class sklearn.cluster.OPTICS(*, min_samples=5, max_eps=inf, metric='minkowski', p=2, metric_params=None, cluster_method='xi', eps=None, xi=0.05, predecessor_correction=True, min_cluster_size=None, algorithm='auto', leaf_size=30, memory=None, n_jobs=None)[原始碼]#
從向量陣列估計叢集結構。
OPTICS(Ordering Points To Identify the Clustering Structure,排序點以識別叢集結構)與 DBSCAN 密切相關,它會找出高密度的核心樣本,並從這些核心樣本擴展叢集 [1]。與 DBSCAN 不同的是,它為可變的鄰域半徑保留了叢集階層。與目前 sklearn 實作的 DBSCAN 相比,更適合用於大型資料集。
然後使用類似 DBSCAN 的方法(cluster_method = ‘dbscan’)或 [1] 中提出的自動技術(cluster_method = ‘xi’)提取叢集。
此實作與原始 OPTICS 的不同之處在於,它首先對所有點執行 k 最近鄰搜尋,以識別核心大小,然後在建構叢集順序時,僅計算到未處理點的距離。請注意,我們不使用堆積來管理擴展候選點,因此時間複雜度將為 O(n^2)。
請在使用者指南中閱讀更多資訊。
- 參數:
- min_samplesint > 1 或介於 0 和 1 之間的浮點數,預設值為 5
一個點要被視為核心點,其鄰域中所需的樣本數。此外,向上和向下的陡峭區域不能有超過
min_samples個連續的非陡峭點。以絕對數字或樣本數的分數表示(四捨五入為至少 2)。- max_epsfloat,預設值為 np.inf
兩個樣本之間的最大距離,其中一個樣本要被視為在另一個樣本的鄰域中。預設值
np.inf將識別所有尺度上的叢集;減少max_eps將會縮短執行時間。- metricstr 或可呼叫物件,預設值為 ‘minkowski’
用於距離計算的度量。可以使用 scikit-learn 或 scipy.spatial.distance 中的任何度量。
如果 metric 是一個可呼叫的函式,則會針對每一對實例(列)呼叫它,並記錄結果值。可呼叫函式應接受兩個陣列作為輸入,並傳回一個值,表示它們之間的距離。這適用於 Scipy 的度量,但不如將度量名稱作為字串傳遞有效率。如果 metric 為 “precomputed”,則假設
X為距離矩陣,並且必須是正方形。metric 的有效值為
來自 scikit-learn:[‘cityblock’, ‘cosine’, ‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’]
來自 scipy.spatial.distance:[‘braycurtis’, ‘canberra’, ‘chebyshev’, ‘correlation’, ‘dice’, ‘hamming’, ‘jaccard’, ‘kulsinski’, ‘mahalanobis’, ‘minkowski’, ‘rogerstanimoto’, ‘russellrao’, ‘seuclidean’, ‘sokalmichener’, ‘sokalsneath’, ‘sqeuclidean’, ‘yule’]
稀疏矩陣僅支援 scikit-learn 度量。如需這些度量的詳細資訊,請參閱 scipy.spatial.distance 的文件。
注意
'kulsinski'從 SciPy 1.9 開始已被棄用,並將在 SciPy 1.11 中移除。- pfloat,預設值為 2
來自
pairwise_distances的 Minkowski 度量的參數。當 p = 1 時,這相當於使用 manhattan_distance (l1);而 p = 2 時,則相當於 euclidean_distance (l2)。對於任意 p,則使用 minkowski_distance (l_p)。- metric_paramsdict,預設值為 None
度量函式的其他關鍵字引數。
- cluster_methodstr,預設值為 ‘xi’
使用計算出的可達性和排序來提取叢集所用的提取方法。可能的值為 “xi” 和 “dbscan”。
- epsfloat,預設值為 None
兩個樣本之間的最大距離,其中一個樣本要被視為在另一個樣本的鄰域中。預設情況下,它假設與
max_eps相同的值。僅在cluster_method='dbscan'時使用。- xi介於 0 和 1 之間的浮點數,預設值為 0.05
決定可達性圖中構成叢集邊界的最小陡度。例如,可達性圖中的向上點定義為一個點到其後繼點的比率最多為 1-xi。僅在
cluster_method='xi'時使用。- predecessor_correctionbool,預設值為 True
根據 OPTICS 計算出的前導點修正群集 [2]。此參數對大多數數據集影響極小。僅在
cluster_method='xi'時使用。- min_cluster_sizeint > 1 或介於 0 和 1 之間的 float,預設值為 None
OPTICS 群集中最小的樣本數,以絕對數字或樣本數的比例表示(四捨五入至少為 2)。如果為
None,則改為使用min_samples的值。僅在cluster_method='xi'時使用。- algorithm{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, 預設值為 ‘auto’
用於計算最近鄰的演算法
‘ball_tree’ 將使用
BallTree。‘kd_tree’ 將使用
KDTree。‘brute’ 將使用暴力搜尋。
‘auto’(預設值)將嘗試根據傳遞給
fit方法的值來決定最合適的演算法。
注意:在稀疏輸入上進行擬合將覆寫此參數的設定,使用暴力搜尋。
- leaf_sizeint,預設值為 30
傳遞給
BallTree或KDTree的葉節點大小。這可能會影響建構和查詢的速度,以及儲存樹所需的記憶體。最佳值取決於問題的性質。- memory具有 joblib.Memory 介面的 str 或物件,預設值為 None
用於快取樹狀計算的輸出。預設情況下,不進行快取。如果給定字串,則它是快取目錄的路徑。
- n_jobsint,預設值為 None
用於執行鄰居搜尋的並行作業數量。
None表示 1,除非在joblib.parallel_backend環境中。-1表示使用所有處理器。請參閱 詞彙表 以獲取更多詳細資訊。
- 屬性:
- labels_形狀為 (n_samples,) 的 ndarray
給定 fit() 的數據集中每個點的群集標籤。雜訊樣本和未包含在
cluster_hierarchy_的葉節點群集中的點將標記為 -1。- reachability_形狀為 (n_samples,) 的 ndarray
每個樣本的可達距離,依物件順序索引。使用
clust.reachability_[clust.ordering_]以群集順序存取。- ordering_形狀為 (n_samples,) 的 ndarray
樣本索引的群集排序列表。
- core_distances_形狀為 (n_samples,) 的 ndarray
每個樣本成為核心點的距離,依物件順序索引。永遠不會成為核心的點的距離為 inf。使用
clust.core_distances_[clust.ordering_]以群集順序存取。- predecessor_形狀為 (n_samples,) 的 ndarray
樣本從哪個點到達,依物件順序索引。種子點的前導點為 -1。
- cluster_hierarchy_形狀為 (n_clusters, 2) 的 ndarray
以每行
[開始, 結束]形式的群集列表,所有索引都包含在內。群集按照(結束, -開始)(升序)排序,以便包含較小群集的較大群集排在這些較小群集之後。由於labels_不反映層次結構,因此通常len(cluster_hierarchy_) > np.unique(optics.labels_)。另請注意,這些索引是ordering_的索引,即X[ordering_][start:end + 1]形成一個群集。僅在cluster_method='xi'時可用。- n_features_in_int
在 fit 期間看到的特徵數量。
在 0.24 版中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有全部為字串的特徵名稱時才定義。在 1.0 版中新增。
另請參閱
DBSCAN針對指定鄰域半徑 (eps) 的類似群集。我們的實作針對運行時間進行了最佳化。
參考文獻
[1] (1,2)Ankerst, Mihael, Markus M. Breunig, Hans-Peter Kriegel 和 Jörg Sander。“OPTICS:對點進行排序以識別群集結構。” ACM SIGMOD Record 28, no. 2 (1999): 49-60。
[2]Schubert, Erich, Michael Gertz。“改善從 OPTICS 圖中提取的群集結構。” Proc. of the Conference “Lernen, Wissen, Daten, Analysen” (LWDA) (2018): 318-329。
範例
>>> from sklearn.cluster import OPTICS >>> import numpy as np >>> X = np.array([[1, 2], [2, 5], [3, 6], ... [8, 7], [8, 8], [7, 3]]) >>> clustering = OPTICS(min_samples=2).fit(X) >>> clustering.labels_ array([0, 0, 0, 1, 1, 1])
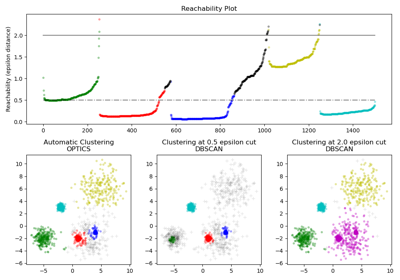
如需更詳細的範例,請參閱 OPTICS 群集演算法的示範。
- fit(X, y=None)[原始碼]#
執行 OPTICS 群集。
提取點和可達距離的排序列表,並使用在 OPTICS 物件實例化時指定的
max_eps距離執行初始群集。- 參數:
- X形狀為 (n_samples, n_features) 的 {ndarray, sparse matrix},或如果 metric=’precomputed’,則為 (n_samples, n_samples)
如果 metric=’precomputed’,則為特徵陣列或樣本之間距離的陣列。如果提供了稀疏矩陣,它將被轉換為 CSR 格式。
- y忽略
未使用,依慣例為 API 一致性而存在。
- 回傳值:
- self物件
回傳 self 的已擬合實例。
- fit_predict(X, y=None, **kwargs)[原始碼]#
對
X執行分群並回傳群集標籤。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入資料。
- y忽略
未使用,依慣例為 API 一致性而存在。
- **kwargs字典
要傳遞給
fit的引數。在 1.4 版中新增。
- 回傳值:
- labels形狀為 (n_samples,),dtype=np.int64 的 ndarray
群集標籤。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看 使用者指南 以了解路由機制的運作方式。
- 回傳值:
- routingMetadataRequest
一個封裝路由資訊的
MetadataRequest。