注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
scikit-learn 1.5 的發行重點#
我們很高興宣布 scikit-learn 1.5 的發布!新增了許多錯誤修復和改進,以及一些關鍵的新功能。以下我們詳細說明了此版本的重點。有關所有變更的詳盡列表,請參閱發行說明。
使用 pip 安裝最新版本
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
FixedThresholdClassifier:設定二元分類器的決策閾值#
scikit-learn 的所有二元分類器都使用 0.5 的固定決策閾值,將機率估計值(即 predict_proba 的輸出)轉換為類別預測。然而,0.5 幾乎從來都不是給定問題的理想閾值。FixedThresholdClassifier 允許包裝任何二元分類器並設定自訂決策閾值。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import ConfusionMatrixDisplay
X, y = make_classification(n_samples=10_000, weights=[0.9, 0.1], random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
classifier_05 = LogisticRegression(C=1e6, random_state=0).fit(X_train, y_train)
_ = ConfusionMatrixDisplay.from_estimator(classifier_05, X_test, y_test)
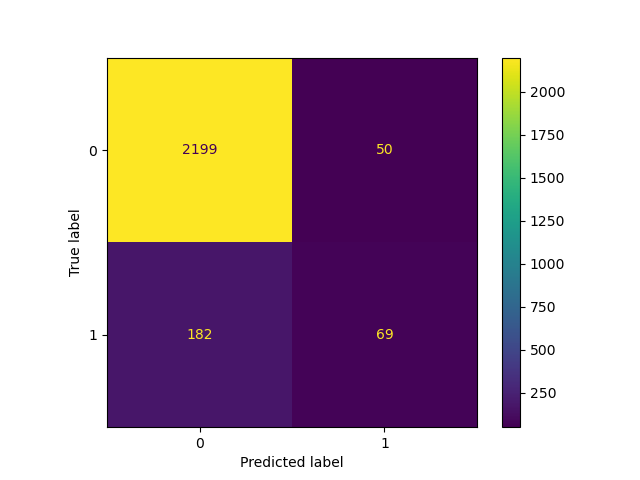
降低閾值,即允許更多樣本分類為正類別,會增加真陽性的數量,但會以增加偽陽性的代價為代價(正如從 ROC 曲線的凹度所知)。
from sklearn.model_selection import FixedThresholdClassifier
classifier_01 = FixedThresholdClassifier(classifier_05, threshold=0.1)
classifier_01.fit(X_train, y_train)
_ = ConfusionMatrixDisplay.from_estimator(classifier_01, X_test, y_test)
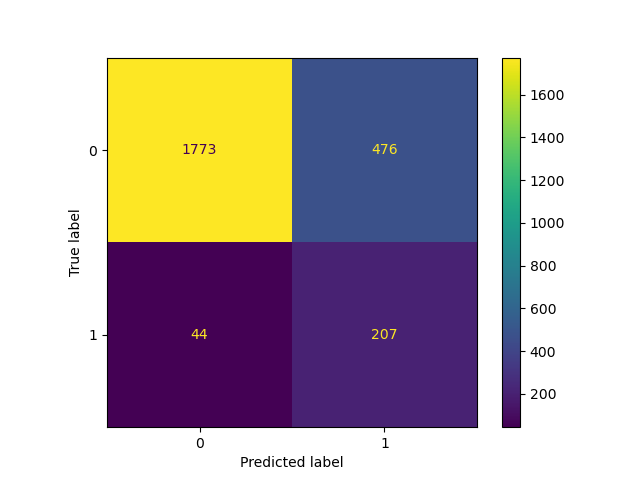
TunedThresholdClassifierCV:調整二元分類器的決策閾值#
可以使用 TunedThresholdClassifierCV 調整二元分類器的決策閾值,以最佳化給定的指標。
當模型要在特定的應用程式環境中部署時,這特別有用,在這種環境中,我們可以為真陽性、真陰性、偽陽性和偽陰性分配不同的增益或成本。
讓我們考慮一個任意的案例來說明這一點,其中
每個真陽性可獲得 1 個單位的利潤,例如,歐元、良好健康的壽命年限等等;
真陰性沒有增益或成本;
每個偽陰性的成本為 2;
每個偽陽性的成本為 0.1。
我們的指標量化每個樣本的平均利潤,該指標由以下 Python 函數定義
from sklearn.metrics import confusion_matrix
def custom_score(y_observed, y_pred):
tn, fp, fn, tp = confusion_matrix(y_observed, y_pred, normalize="all").ravel()
return tp - 2 * fn - 0.1 * fp
print("Untuned decision threshold: 0.5")
print(f"Custom score: {custom_score(y_test, classifier_05.predict(X_test)):.2f}")
Untuned decision threshold: 0.5
Custom score: -0.12
有趣的是,觀察到每次預測的平均增益為負值,這意味著此決策系統平均會產生損失。
調整閾值以最佳化此自訂指標會產生較小的閾值,該閾值允許更多樣本分類為正類別。結果,每次預測的平均增益都會提高。
from sklearn.model_selection import TunedThresholdClassifierCV
from sklearn.metrics import make_scorer
custom_scorer = make_scorer(
custom_score, response_method="predict", greater_is_better=True
)
tuned_classifier = TunedThresholdClassifierCV(
classifier_05, cv=5, scoring=custom_scorer
).fit(X, y)
print(f"Tuned decision threshold: {tuned_classifier.best_threshold_:.3f}")
print(f"Custom score: {custom_score(y_test, tuned_classifier.predict(X_test)):.2f}")
Tuned decision threshold: 0.071
Custom score: 0.04
我們觀察到,調整決策閾值可以將平均產生損失的基於機器學習的系統轉變為有益的系統。
實際上,定義有意義的特定應用程式指標可能涉及使那些對不良預測的成本和對良好預測的增益取決於每個個別數據點的輔助元數據,例如欺詐偵測系統中的交易金額。
為了實現這一點,TunedThresholdClassifierCV 利用元數據路由支援 (元數據路由使用者指南),允許最佳化複雜的業務指標,如為成本敏感學習事後調整決策閾值中所詳述。
PCA 的效能改進#
PCA 有一個新的求解器 "covariance_eigh",對於具有許多數據點和少數特徵的資料集,它比其他求解器快一個數量級,並且記憶體效率更高。
from sklearn.datasets import make_low_rank_matrix
from sklearn.decomposition import PCA
X = make_low_rank_matrix(
n_samples=10_000, n_features=100, tail_strength=0.1, random_state=0
)
pca = PCA(n_components=10, svd_solver="covariance_eigh").fit(X)
print(f"Explained variance: {pca.explained_variance_ratio_.sum():.2f}")
Explained variance: 0.88
新的求解器也接受稀疏輸入數據
Explained variance: 0.13
"full" 求解器也已得到改進,可使用更少的記憶體並允許更快的轉換。預設 svd_solver="auto"` 選項利用新的求解器,現在能夠為稀疏資料集選擇適當的求解器。
與大多數其他 PCA 求解器類似,如果輸入數據作為 PyTorch 或 CuPy 陣列傳遞,新的 "covariance_eigh" 求解器可以透過啟用 Array API 的實驗性支援來利用 GPU 計算。
ColumnTransformer 可下標#
現在可以使用名稱索引直接存取 ColumnTransformer 的轉換器。
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
X = np.array([[0, 1, 2], [3, 4, 5]])
column_transformer = ColumnTransformer(
[("std_scaler", StandardScaler(), [0]), ("one_hot", OneHotEncoder(), [1, 2])]
)
column_transformer.fit(X)
print(column_transformer["std_scaler"])
print(column_transformer["one_hot"])
StandardScaler()
OneHotEncoder()
SimpleImputer 的自訂填補策略#
SimpleImputer 現在支援自訂填補策略,使用可呼叫物件,從列向量的非缺失值計算標量值。
from sklearn.impute import SimpleImputer
X = np.array(
[
[-1.1, 1.1, 1.1],
[3.9, -1.2, np.nan],
[np.nan, 1.3, np.nan],
[-0.1, -1.4, -1.4],
[-4.9, 1.5, -1.5],
[np.nan, 1.6, 1.6],
]
)
def smallest_abs(arr):
"""Return the smallest absolute value of a 1D array."""
return np.min(np.abs(arr))
imputer = SimpleImputer(strategy=smallest_abs)
imputer.fit_transform(X)
array([[-1.1, 1.1, 1.1],
[ 3.9, -1.2, 1.1],
[ 0.1, 1.3, 1.1],
[-0.1, -1.4, -1.4],
[-4.9, 1.5, -1.5],
[ 0.1, 1.6, 1.6]])
具有非數值陣列的成對距離#
pairwise_distances 現在可以使用可呼叫指標來計算非數值陣列之間的距離。
from sklearn.metrics import pairwise_distances
X = ["cat", "dog"]
Y = ["cat", "fox"]
def levenshtein_distance(x, y):
"""Return the Levenshtein distance between two strings."""
if x == "" or y == "":
return max(len(x), len(y))
if x[0] == y[0]:
return levenshtein_distance(x[1:], y[1:])
return 1 + min(
levenshtein_distance(x[1:], y),
levenshtein_distance(x, y[1:]),
levenshtein_distance(x[1:], y[1:]),
)
pairwise_distances(X, Y, metric=levenshtein_distance)
array([[0., 3.],
[3., 2.]])
腳本的總執行時間:(0 分鐘 0.723 秒)
相關範例