注意
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
繪製分類機率#
繪製不同分類器的分類機率。我們使用一個 3 類別資料集,並使用支持向量分類器、L1 和 L2 懲罰邏輯迴歸(多項多類別)、具有邏輯迴歸的一對多版本以及高斯過程分類對其進行分類。
線性 SVC 預設不是機率分類器,但在此範例中已啟用內建校準選項 (probability=True)。
具有一對多的邏輯迴歸並非開箱即用的多類別分類器。 因此,在分離第 2 類和第 3 類時,它比其他估計器更困難。
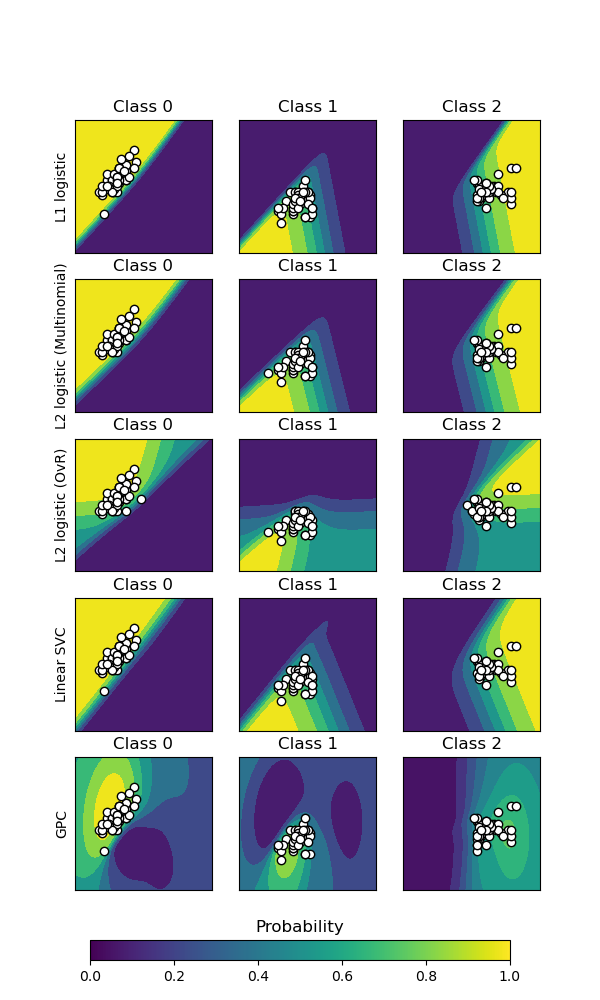
Accuracy (train) for L1 logistic: 83.3%
Accuracy (train) for L2 logistic (Multinomial): 82.7%
Accuracy (train) for L2 logistic (OvR): 79.3%
Accuracy (train) for Linear SVC: 82.0%
Accuracy (train) for GPC: 82.7%
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import cm
from sklearn import datasets
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
iris = datasets.load_iris()
X = iris.data[:, 0:2] # we only take the first two features for visualization
y = iris.target
n_features = X.shape[1]
C = 10
kernel = 1.0 * RBF([1.0, 1.0]) # for GPC
# Create different classifiers.
classifiers = {
"L1 logistic": LogisticRegression(C=C, penalty="l1", solver="saga", max_iter=10000),
"L2 logistic (Multinomial)": LogisticRegression(
C=C, penalty="l2", solver="saga", max_iter=10000
),
"L2 logistic (OvR)": OneVsRestClassifier(
LogisticRegression(C=C, penalty="l2", solver="saga", max_iter=10000)
),
"Linear SVC": SVC(kernel="linear", C=C, probability=True, random_state=0),
"GPC": GaussianProcessClassifier(kernel),
}
n_classifiers = len(classifiers)
fig, axes = plt.subplots(
nrows=n_classifiers,
ncols=len(iris.target_names),
figsize=(3 * 2, n_classifiers * 2),
)
for classifier_idx, (name, classifier) in enumerate(classifiers.items()):
y_pred = classifier.fit(X, y).predict(X)
accuracy = accuracy_score(y, y_pred)
print(f"Accuracy (train) for {name}: {accuracy:0.1%}")
for label in np.unique(y):
# plot the probability estimate provided by the classifier
disp = DecisionBoundaryDisplay.from_estimator(
classifier,
X,
response_method="predict_proba",
class_of_interest=label,
ax=axes[classifier_idx, label],
vmin=0,
vmax=1,
)
axes[classifier_idx, label].set_title(f"Class {label}")
# plot data predicted to belong to given class
mask_y_pred = y_pred == label
axes[classifier_idx, label].scatter(
X[mask_y_pred, 0], X[mask_y_pred, 1], marker="o", c="w", edgecolor="k"
)
axes[classifier_idx, label].set(xticks=(), yticks=())
axes[classifier_idx, 0].set_ylabel(name)
ax = plt.axes([0.15, 0.04, 0.7, 0.02])
plt.title("Probability")
_ = plt.colorbar(
cm.ScalarMappable(norm=None, cmap="viridis"), cax=ax, orientation="horizontal"
)
plt.show()
腳本的總執行時間:(0 分鐘 1.444 秒)
相關範例