注意
前往結尾下載完整範例程式碼。或透過 JupyterLite 或 Binder 在瀏覽器中執行此範例
scikit-learn 1.2 的發行重點#
我們很高興宣布發布 scikit-learn 1.2!新增了許多錯誤修復和改進,以及一些新的主要功能。我們在下面詳細介紹了此版本的一些主要功能。如需所有變更的詳盡清單,請參閱發行說明。
若要安裝最新版本 (使用 pip)
pip install --upgrade scikit-learn
或使用 conda
conda install -c conda-forge scikit-learn
使用 set_output API 的 Pandas 輸出#
scikit-learn 的轉換器現在支援使用 set_output API 的 pandas 輸出。若要進一步了解 set_output API,請參閱範例:介紹 set_output API和#這個影片,適用於 scikit-learn 轉換器的 pandas DataFrame 輸出 (一些範例)。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler, KBinsDiscretizer
from sklearn.compose import ColumnTransformer
X, y = load_iris(as_frame=True, return_X_y=True)
sepal_cols = ["sepal length (cm)", "sepal width (cm)"]
petal_cols = ["petal length (cm)", "petal width (cm)"]
preprocessor = ColumnTransformer(
[
("scaler", StandardScaler(), sepal_cols),
("kbin", KBinsDiscretizer(encode="ordinal"), petal_cols),
],
verbose_feature_names_out=False,
).set_output(transform="pandas")
X_out = preprocessor.fit_transform(X)
X_out.sample(n=5, random_state=0)
基於直方圖的梯度提升樹中的互動約束#
HistGradientBoostingRegressor和HistGradientBoostingClassifier現在支援使用 interaction_cst 參數的互動約束。如需詳細資料,請參閱使用者指南。在以下範例中,不允許特徵互動。
from sklearn.datasets import load_diabetes
from sklearn.ensemble import HistGradientBoostingRegressor
X, y = load_diabetes(return_X_y=True, as_frame=True)
hist_no_interact = HistGradientBoostingRegressor(
interaction_cst=[[i] for i in range(X.shape[1])], random_state=0
)
hist_no_interact.fit(X, y)
全新和增強的顯示#
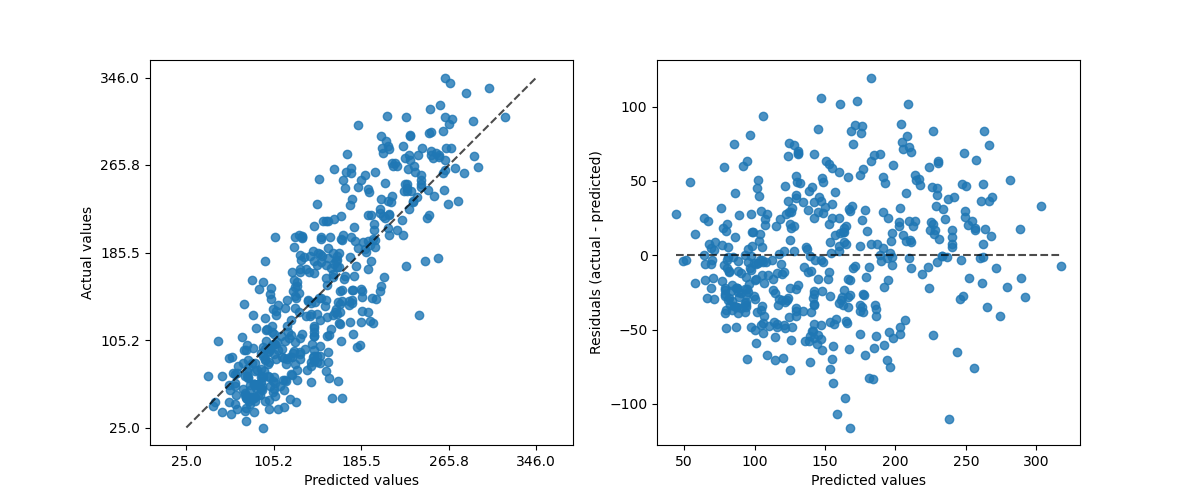
PredictionErrorDisplay提供了一種以定性方式分析迴歸模型的方法。
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 5))
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="actual_vs_predicted", ax=axs[0]
)
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="residual_vs_predicted", ax=axs[1]
)
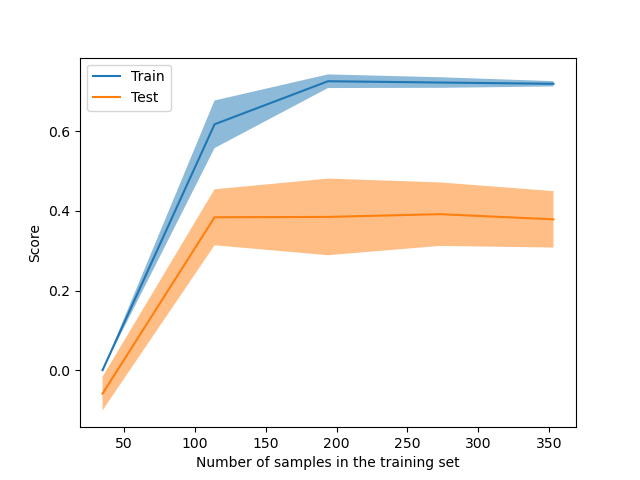
LearningCurveDisplay現在可用於繪製來自learning_curve的結果。
from sklearn.model_selection import LearningCurveDisplay
_ = LearningCurveDisplay.from_estimator(
hist_no_interact, X, y, cv=5, n_jobs=2, train_sizes=np.linspace(0.1, 1, 5)
)
/home/circleci/miniforge3/envs/testenv/lib/python3.9/site-packages/joblib/externals/loky/backend/fork_exec.py:38: RuntimeWarning:
Using fork() can cause Polars to deadlock in the child process.
In addition, using fork() with Python in general is a recipe for mysterious
deadlocks and crashes.
The most likely reason you are seeing this error is because you are using the
multiprocessing module on Linux, which uses fork() by default. This will be
fixed in Python 3.14. Until then, you want to use the "spawn" context instead.
See https://docs.pola.rs/user-guide/misc/multiprocessing/ for details.
If you really know what your doing, you can silence this warning with the warning module
or by setting POLARS_ALLOW_FORKING_THREAD=1.
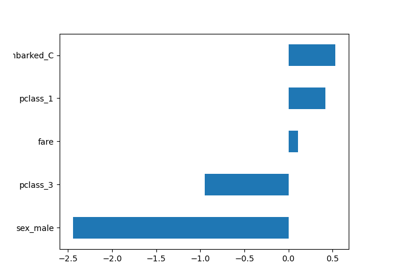
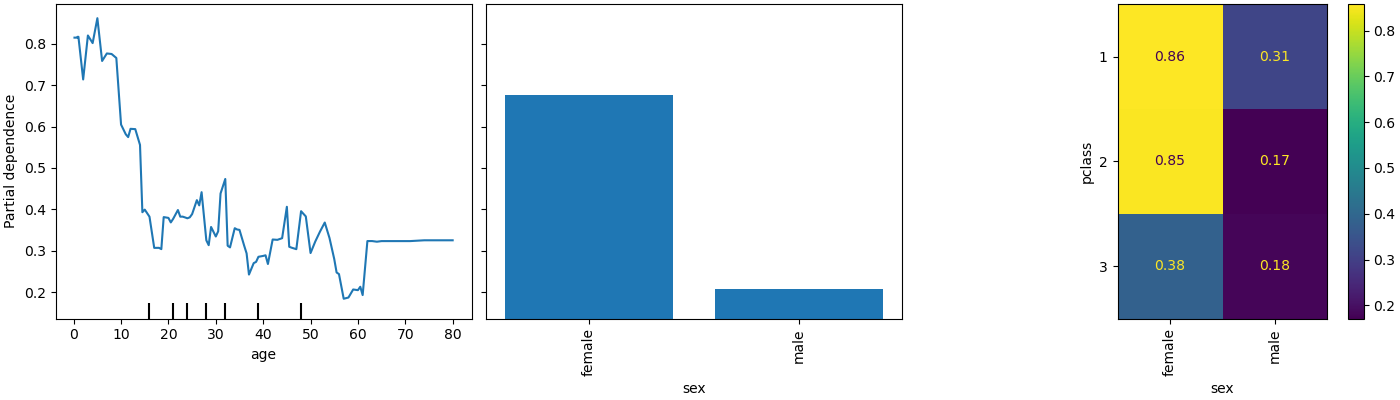
PartialDependenceDisplay公開一個新的參數 categorical_features,以使用長條圖和熱圖顯示類別特徵的部分依賴性。
from sklearn.datasets import fetch_openml
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X = X.select_dtypes(["number", "category"]).drop(columns=["body"])
from sklearn.preprocessing import OrdinalEncoder
from sklearn.pipeline import make_pipeline
categorical_features = ["pclass", "sex", "embarked"]
model = make_pipeline(
ColumnTransformer(
transformers=[("cat", OrdinalEncoder(), categorical_features)],
remainder="passthrough",
),
HistGradientBoostingRegressor(random_state=0),
).fit(X, y)
from sklearn.inspection import PartialDependenceDisplay
fig, ax = plt.subplots(figsize=(14, 4), constrained_layout=True)
_ = PartialDependenceDisplay.from_estimator(
model,
X,
features=["age", "sex", ("pclass", "sex")],
categorical_features=categorical_features,
ax=ax,
)
fetch_openml中的更快速剖析器#
fetch_openml現在支援一個新的 "pandas" 剖析器,該剖析器具有更高的記憶體和 CPU 效率。在 v1.4 中,預設值將變更為 parser="auto",這將自動針對密集資料使用 "pandas" 剖析器,而針對稀疏資料使用 "liac-arff"。
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X.head()
LinearDiscriminantAnalysis 中實驗性陣列 API 支援#
已在 LinearDiscriminantAnalysis 中加入對 陣列 API 規格的實驗性支援。此估算器現在可以運行在任何符合陣列 API 的函式庫上,例如 GPU 加速的陣列函式庫 CuPy。詳情請參閱使用者指南。
許多估算器的效率提升#
在 1.1 版本中,許多依賴成對距離計算的估算器(基本上是與群集、流形學習和鄰近搜尋演算法相關的估算器)針對 float64 密集輸入的效率大幅提高。效率的提升尤其包括減少記憶體佔用空間以及在多核心機器上更好的擴展性。在 1.2 版本中,這些估算器針對 float32 和 float64 資料集上所有密集和稀疏輸入的組合進一步提高了效率,但歐幾里德距離和平方歐幾里德距離指標的稀疏-密集和密集-稀疏組合除外。受影響的估算器詳細列表可以在變更日誌中找到。
腳本總執行時間:(0 分鐘 4.988 秒)
相關範例