注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
縮放 SVC 的正規化參數#
以下範例說明當使用支持向量機進行分類時,縮放正規化參數的效果。對於 SVC 分類,我們對以下方程式的風險最小化感興趣
其中
\(C\) 用於設定正規化的量
\(\mathcal{L}\) 是我們樣本和模型參數的
損失函數。\(\Omega\) 是我們模型參數的
懲罰函數
如果我們將損失函數視為每個樣本的個別誤差,那麼資料擬合項,或每個樣本的誤差總和,會隨著我們增加更多樣本而增加。然而,懲罰項不會增加。
例如,當使用交叉驗證,透過C設定正規化量時,主要問題和交叉驗證摺疊內較小的問題之間會有不同的樣本量。
由於損失函數取決於樣本量,後者會影響C的選定值。產生的問題是「我們如何最佳調整 C 以考慮不同的訓練樣本量?」
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
資料產生#
在此範例中,我們研究在使用 L1 或 L2 懲罰時,重新參數化正規化參數C以考慮樣本數的效果。為此,我們建立一個具有大量特徵的合成資料集,其中只有少數是有資訊的。因此,我們預期正規化會將係數縮減為零(L2 懲罰)或完全為零(L1 懲罰)。
from sklearn.datasets import make_classification
n_samples, n_features = 100, 300
X, y = make_classification(
n_samples=n_samples, n_features=n_features, n_informative=5, random_state=1
)
L1 懲罰案例#
在 L1 的情況下,理論認為,如果提供強烈的正規化,估計器無法像知道真實分佈的模型一樣進行良好預測(即使在樣本大小成長到無限大的情況下),因為它可能會將某些預測特徵的權重設定為零,這會導致偏差。然而,它確實指出,可以透過調整C來找到正確的非零參數集及其符號。
我們定義一個具有 L1 懲罰的線性 SVC。
我們透過交叉驗證計算C不同值的平均測試分數。
import numpy as np
import pandas as pd
from sklearn.model_selection import ShuffleSplit, validation_curve
Cs = np.logspace(-2.3, -1.3, 10)
train_sizes = np.linspace(0.3, 0.7, 3)
labels = [f"fraction: {train_size}" for train_size in train_sizes]
shuffle_params = {
"test_size": 0.3,
"n_splits": 150,
"random_state": 1,
}
results = {"C": Cs}
for label, train_size in zip(labels, train_sizes):
cv = ShuffleSplit(train_size=train_size, **shuffle_params)
train_scores, test_scores = validation_curve(
model_l1,
X,
y,
param_name="C",
param_range=Cs,
cv=cv,
n_jobs=2,
)
results[label] = test_scores.mean(axis=1)
results = pd.DataFrame(results)
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=1, ncols=2, sharey=True, figsize=(12, 6))
# plot results without scaling C
results.plot(x="C", ax=axes[0], logx=True)
axes[0].set_ylabel("CV score")
axes[0].set_title("No scaling")
for label in labels:
best_C = results.loc[results[label].idxmax(), "C"]
axes[0].axvline(x=best_C, linestyle="--", color="grey", alpha=0.7)
# plot results by scaling C
for train_size_idx, label in enumerate(labels):
train_size = train_sizes[train_size_idx]
results_scaled = results[[label]].assign(
C_scaled=Cs * float(n_samples * np.sqrt(train_size))
)
results_scaled.plot(x="C_scaled", ax=axes[1], logx=True, label=label)
best_C_scaled = results_scaled["C_scaled"].loc[results[label].idxmax()]
axes[1].axvline(x=best_C_scaled, linestyle="--", color="grey", alpha=0.7)
axes[1].set_title("Scaling C by sqrt(1 / n_samples)")
_ = fig.suptitle("Effect of scaling C with L1 penalty")
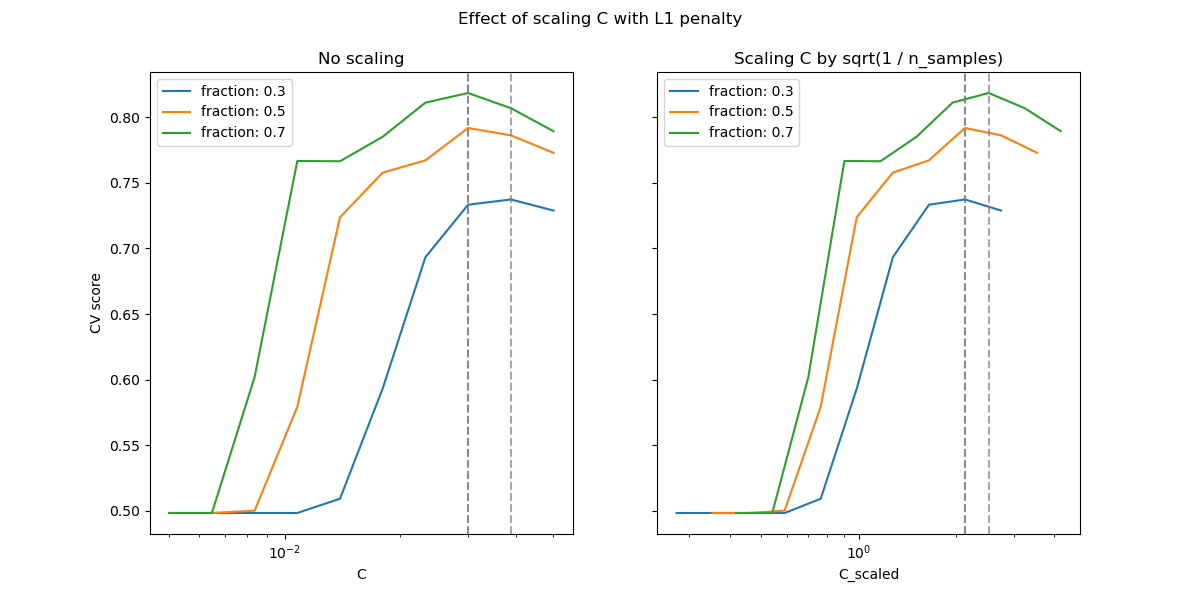
在小的C(強烈正規化)區域,模型學習到的所有係數均為零,導致嚴重的欠擬合。實際上,此區域的準確性處於機會水準。
使用預設縮放會導致C的略微穩定的最佳值,而退出欠擬合區域的轉換取決於訓練樣本的數量。重新參數化會產生更穩定的結果。
請參閱例如Lasso 的預測效能或Lasso 和 Dantzig 選擇器的同時分析的定理 3,其中正規化參數始終被假設為與 1 / sqrt(n_samples) 成比例。
L2 懲罰案例#
我們可以對 L2 懲罰執行類似的實驗。在這種情況下,理論認為為了實現預測一致性,懲罰參數應隨著樣本數量的增加而保持不變。
model_l2 = LinearSVC(penalty="l2", loss="squared_hinge", dual=True)
Cs = np.logspace(-8, 4, 11)
labels = [f"fraction: {train_size}" for train_size in train_sizes]
results = {"C": Cs}
for label, train_size in zip(labels, train_sizes):
cv = ShuffleSplit(train_size=train_size, **shuffle_params)
train_scores, test_scores = validation_curve(
model_l2,
X,
y,
param_name="C",
param_range=Cs,
cv=cv,
n_jobs=2,
)
results[label] = test_scores.mean(axis=1)
results = pd.DataFrame(results)
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=1, ncols=2, sharey=True, figsize=(12, 6))
# plot results without scaling C
results.plot(x="C", ax=axes[0], logx=True)
axes[0].set_ylabel("CV score")
axes[0].set_title("No scaling")
for label in labels:
best_C = results.loc[results[label].idxmax(), "C"]
axes[0].axvline(x=best_C, linestyle="--", color="grey", alpha=0.8)
# plot results by scaling C
for train_size_idx, label in enumerate(labels):
results_scaled = results[[label]].assign(
C_scaled=Cs * float(n_samples * np.sqrt(train_sizes[train_size_idx]))
)
results_scaled.plot(x="C_scaled", ax=axes[1], logx=True, label=label)
best_C_scaled = results_scaled["C_scaled"].loc[results[label].idxmax()]
axes[1].axvline(x=best_C_scaled, linestyle="--", color="grey", alpha=0.8)
axes[1].set_title("Scaling C by sqrt(1 / n_samples)")
fig.suptitle("Effect of scaling C with L2 penalty")
plt.show()
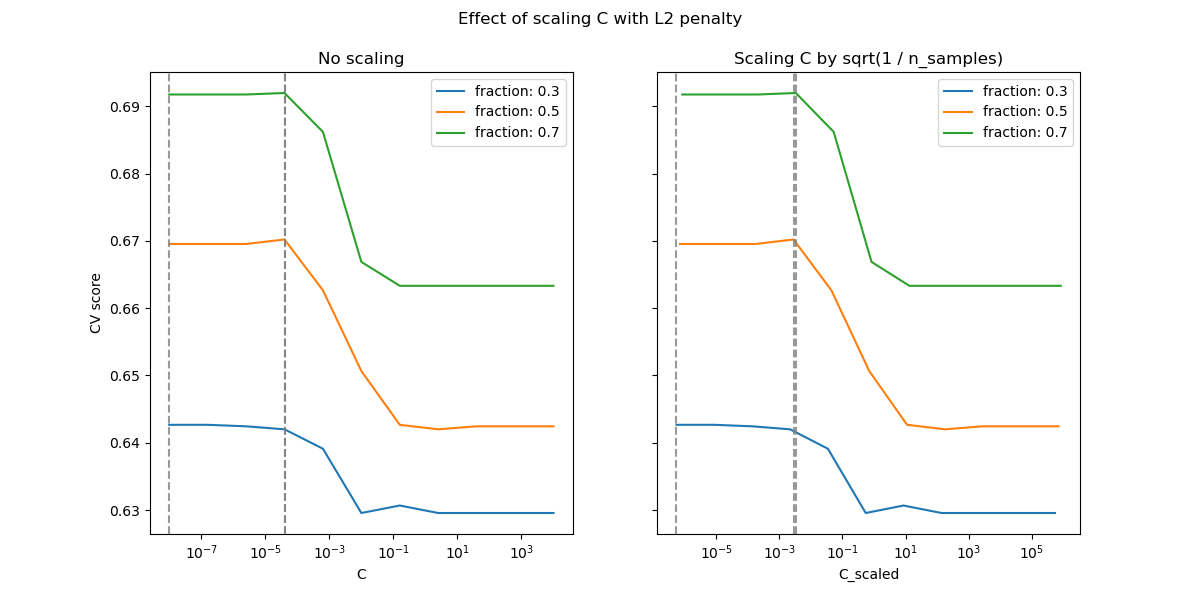
對於 L2 懲罰情況,重新參數化似乎對正規化的最佳值的穩定性影響較小。退出過擬合區域的轉換發生在更廣泛的範圍內,並且準確性似乎沒有降低到機會水平。
嘗試將值增加到n_splits=1_000,以在 L2 情況下獲得更好的結果,由於文件產生器的限制,這裡未顯示。
腳本總執行時間:(0 分鐘 20.600 秒)
相關範例