注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
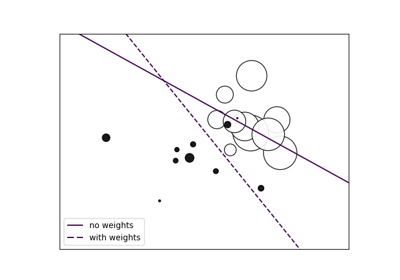
SVM:加權樣本#
繪製加權資料集的決策函數,其中點的大小與其權重成正比。
樣本加權會重新調整 C 參數,這意味著分類器會更加強調正確地處理這些點。這種影響通常可能很微妙。為了強調此處的影響,我們特別加權離群值,使決策邊界的變形非常明顯。
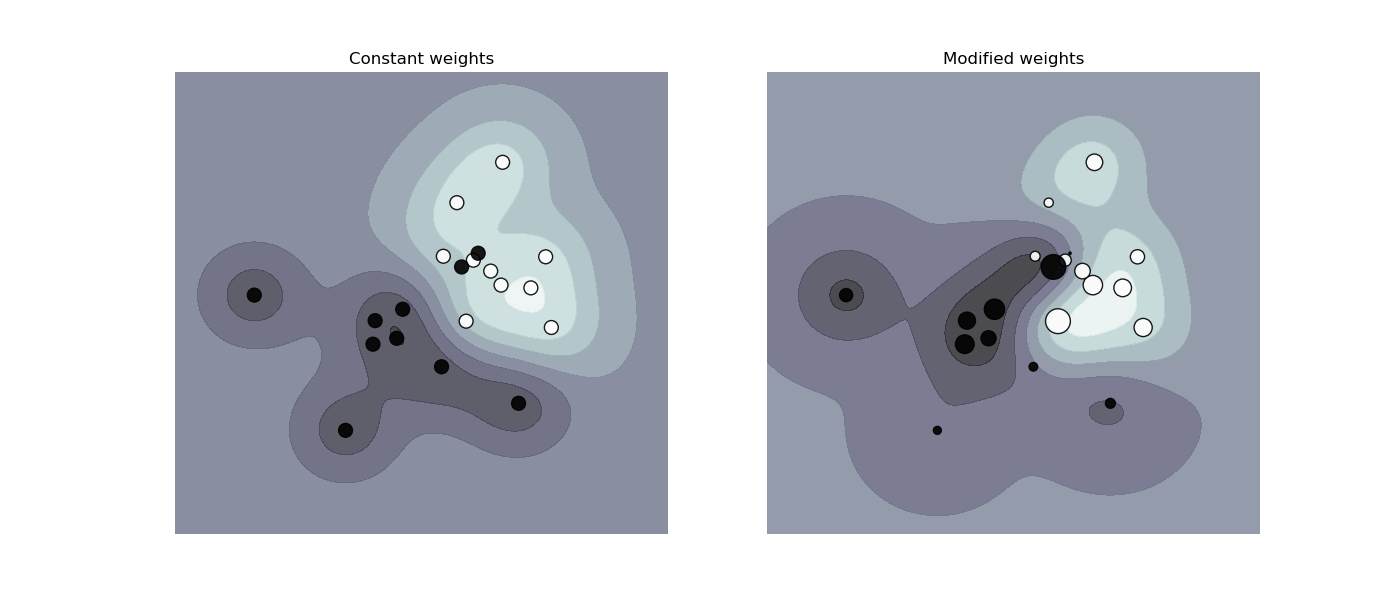
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svm
def plot_decision_function(classifier, sample_weight, axis, title):
# plot the decision function
xx, yy = np.meshgrid(np.linspace(-4, 5, 500), np.linspace(-4, 5, 500))
Z = classifier.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# plot the line, the points, and the nearest vectors to the plane
axis.contourf(xx, yy, Z, alpha=0.75, cmap=plt.cm.bone)
axis.scatter(
X[:, 0],
X[:, 1],
c=y,
s=100 * sample_weight,
alpha=0.9,
cmap=plt.cm.bone,
edgecolors="black",
)
axis.axis("off")
axis.set_title(title)
# we create 20 points
np.random.seed(0)
X = np.r_[np.random.randn(10, 2) + [1, 1], np.random.randn(10, 2)]
y = [1] * 10 + [-1] * 10
sample_weight_last_ten = abs(np.random.randn(len(X)))
sample_weight_constant = np.ones(len(X))
# and bigger weights to some outliers
sample_weight_last_ten[15:] *= 5
sample_weight_last_ten[9] *= 15
# Fit the models.
# This model does not take into account sample weights.
clf_no_weights = svm.SVC(gamma=1)
clf_no_weights.fit(X, y)
# This other model takes into account some dedicated sample weights.
clf_weights = svm.SVC(gamma=1)
clf_weights.fit(X, y, sample_weight=sample_weight_last_ten)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
plot_decision_function(
clf_no_weights, sample_weight_constant, axes[0], "Constant weights"
)
plot_decision_function(clf_weights, sample_weight_last_ten, axes[1], "Modified weights")
plt.show()
腳本的總執行時間:(0 分鐘 0.491 秒)
相關範例