注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
RBF SVM 參數#
此範例說明徑向基底函數 (RBF) 核 SVM 的參數 gamma 和 C 的影響。
直觀地說,gamma 參數定義單個訓練範例的影響範圍,低值表示「遠」,高值表示「近」。gamma 參數可以視為模型選取為支持向量的樣本的影響半徑的倒數。
C 參數在正確分類訓練範例和最大化決策函數的邊距之間進行權衡。對於較大的 C 值,如果決策函數可以更好地正確分類所有訓練點,則可以接受較小的邊距。較低的 C 將鼓勵更大的邊距,因此決策函數更簡單,但會犧牲訓練準確性。換句話說,C 在 SVM 中充當正規化參數。
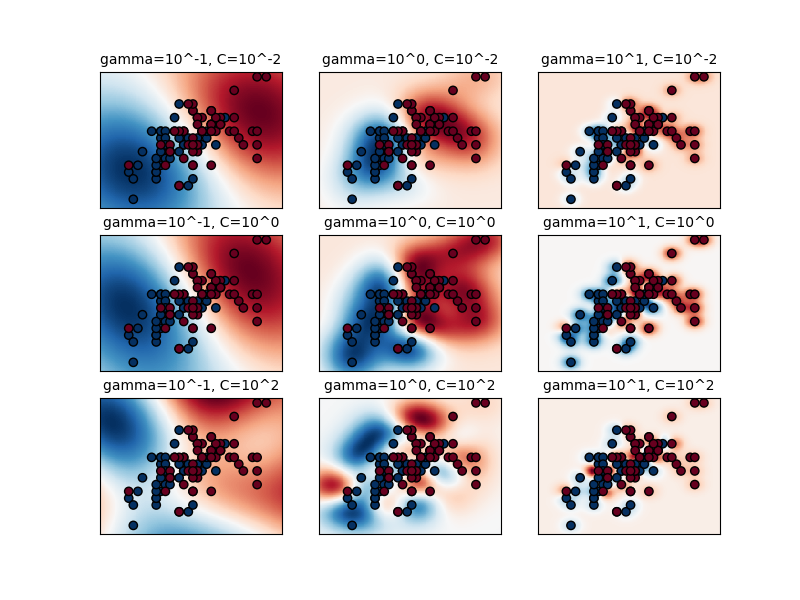
第一個圖是針對一個簡化的分類問題,在僅包含 2 個輸入特徵和 2 個可能目標類別(二元分類)的情況下,針對各種參數值的決策函數的可視化。請注意,這種圖無法針對具有更多特徵或目標類別的問題執行。
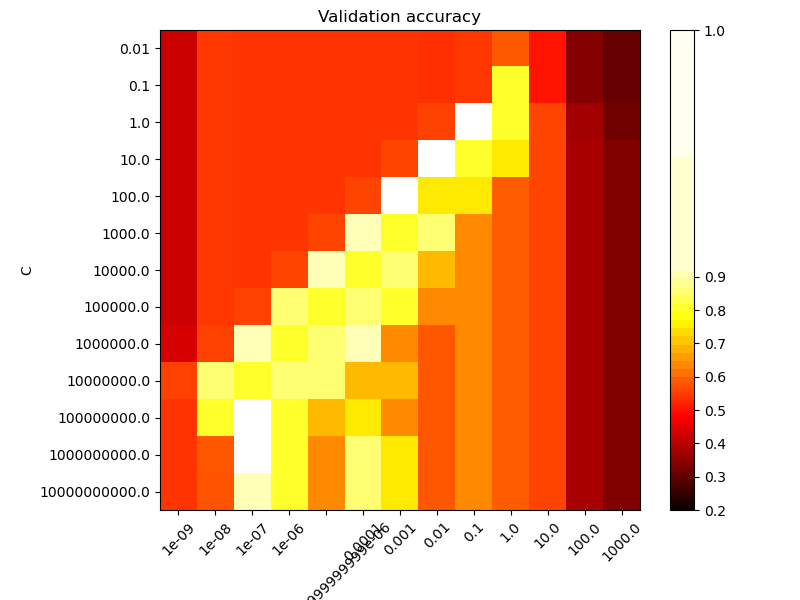
第二個圖是分類器的交叉驗證準確性作為 C 和 gamma 函數的熱圖。在此範例中,我們探索了相對較大的網格以進行說明。實際上,從 \(10^{-3}\) 到 \(10^3\) 的對數網格通常就足夠了。如果最佳參數位於網格的邊界上,則可以在後續搜尋中朝該方向延伸。
請注意,熱圖具有特殊色彩條,其中點值接近效能最佳模型的得分值,以便一眼就能輕鬆分辨它們。
模型的行為對 gamma 參數非常敏感。如果 gamma 太大,則支持向量的影響範圍僅包含支持向量本身,而任何 C 的正規化都無法防止過擬合。
當 gamma 非常小時,模型會受到過多的限制,並且無法擷取資料的複雜性或「形狀」。任何選定的支持向量的影響範圍都將包括整個訓練集。所得模型行為與線性模型類似,具有一組超平面,可分隔任何兩個類別的高密度中心。
對於中間值,我們可以在第二個圖中看到,在 C 和 gamma 的對角線上可以找到良好的模型。透過增加正確分類每個點的重要性(較大的 C 值),可以使平滑模型(較低的 gamma 值)變得更複雜,因此具有良好效能的模型的對角線。
最後,還可以觀察到,對於某些中間 gamma 值,當 C 變得非常大時,我們得到效能相同的模型。這表示支持向量的集合不再變更。RBF 核的半徑本身會充當良好的結構正規化器。進一步增加 C 並無幫助,可能是因為沒有更多訓練點違反(在邊距內或錯誤分類),或至少無法找到更好的解決方案。在分數相等的情況下,使用較小的 C 值可能更有意義,因為非常高的 C 值通常會增加擬合時間。
另一方面,較低的 C 值通常會導致更多支持向量,這可能會增加預測時間。因此,降低 C 的值會在擬合時間和預測時間之間進行權衡。
我們還應該注意,分數的微小差異是由交叉驗證程序的隨機分割造成的。透過增加 CV 迭代次數 n_splits 可以消除這些虛假變化,但會增加計算時間。增加 C_range 和 gamma_range 步驟的值將增加超參數熱圖的解析度。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
實用程式類別,可將色彩圖的中點移至感興趣的值附近。
import numpy as np
from matplotlib.colors import Normalize
class MidpointNormalize(Normalize):
def __init__(self, vmin=None, vmax=None, midpoint=None, clip=False):
self.midpoint = midpoint
Normalize.__init__(self, vmin, vmax, clip)
def __call__(self, value, clip=None):
x, y = [self.vmin, self.midpoint, self.vmax], [0, 0.5, 1]
return np.ma.masked_array(np.interp(value, x, y))
載入和準備資料集#
用於網格搜尋的資料集
用於決策函數可視化的資料集:我們只保留 X 中的前兩個特徵,並對資料集進行子採樣以僅保留 2 個類別,並使其成為二元分類問題。
X_2d = X[:, :2]
X_2d = X_2d[y > 0]
y_2d = y[y > 0]
y_2d -= 1
通常最好縮放用於 SVM 訓練的資料。在此範例中,我們稍微作弊,縮放所有資料,而不是將轉換擬合到訓練集並僅將其應用於測試集。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_2d = scaler.fit_transform(X_2d)
訓練分類器#
對於初始搜尋,以 10 為底的對數網格通常很有幫助。使用 2 為底,可以實現更精細的微調,但成本會高得多。
from sklearn.model_selection import GridSearchCV, StratifiedShuffleSplit
from sklearn.svm import SVC
C_range = np.logspace(-2, 10, 13)
gamma_range = np.logspace(-9, 3, 13)
param_grid = dict(gamma=gamma_range, C=C_range)
cv = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
grid = GridSearchCV(SVC(), param_grid=param_grid, cv=cv)
grid.fit(X, y)
print(
"The best parameters are %s with a score of %0.2f"
% (grid.best_params_, grid.best_score_)
)
The best parameters are {'C': np.float64(1.0), 'gamma': np.float64(0.1)} with a score of 0.97
現在,我們需要為 2D 版本中的所有參數擬合分類器(我們在這裡使用一組較小的參數,因為訓練需要一些時間)
C_2d_range = [1e-2, 1, 1e2]
gamma_2d_range = [1e-1, 1, 1e1]
classifiers = []
for C in C_2d_range:
for gamma in gamma_2d_range:
clf = SVC(C=C, gamma=gamma)
clf.fit(X_2d, y_2d)
classifiers.append((C, gamma, clf))
視覺化#
繪製參數影響的可視化
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
xx, yy = np.meshgrid(np.linspace(-3, 3, 200), np.linspace(-3, 3, 200))
for k, (C, gamma, clf) in enumerate(classifiers):
# evaluate decision function in a grid
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# visualize decision function for these parameters
plt.subplot(len(C_2d_range), len(gamma_2d_range), k + 1)
plt.title("gamma=10^%d, C=10^%d" % (np.log10(gamma), np.log10(C)), size="medium")
# visualize parameter's effect on decision function
plt.pcolormesh(xx, yy, -Z, cmap=plt.cm.RdBu)
plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y_2d, cmap=plt.cm.RdBu_r, edgecolors="k")
plt.xticks(())
plt.yticks(())
plt.axis("tight")
scores = grid.cv_results_["mean_test_score"].reshape(len(C_range), len(gamma_range))
繪製驗證準確性作為 gamma 和 C 函數的熱圖
分數編碼為顏色,使用從深紅色到亮黃色的熱色彩圖。由於最有趣的分數都位於 0.92 到 0.97 的範圍內,因此我們使用自訂標準化器將中點設定為 0.92,以便更容易視覺化有趣範圍內分數值的微小變化,同時不會將所有低分值粗暴地摺疊成相同的顏色。
plt.figure(figsize=(8, 6))
plt.subplots_adjust(left=0.2, right=0.95, bottom=0.15, top=0.95)
plt.imshow(
scores,
interpolation="nearest",
cmap=plt.cm.hot,
norm=MidpointNormalize(vmin=0.2, midpoint=0.92),
)
plt.xlabel("gamma")
plt.ylabel("C")
plt.colorbar()
plt.xticks(np.arange(len(gamma_range)), gamma_range, rotation=45)
plt.yticks(np.arange(len(C_range)), C_range)
plt.title("Validation accuracy")
plt.show()
腳本總執行時間: (0 分鐘 5.290 秒)
相關範例