注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
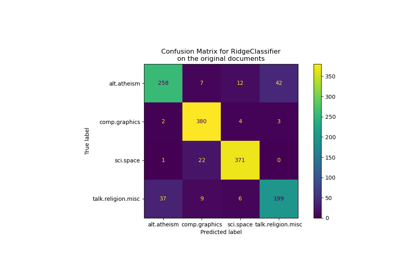
使用譜系共分群演算法對文件進行雙向分群#
此範例展示了在二十新聞組資料集上的譜系共分群演算法。排除了 'comp.os.ms-windows.misc' 類別,因為它包含許多只包含資料的帖子。
TF-IDF 向量化的帖子形成一個詞頻矩陣,然後使用 Dhillon 的譜系共分群演算法進行雙向分群。產生的文件-詞語雙向群集表示在這些文件子集中更常使用的詞語子集。
對於一些最佳的雙向群集,會印出其最常見的文件類別及其十個最重要的詞語。最佳的雙向群集由其正規化切割確定。最佳的詞語則透過比較其在雙向群集內外的總和來確定。
為了比較,文件也使用 MiniBatchKMeans 進行分群。從雙向群集得出的文件群集比 MiniBatchKMeans 找到的群集獲得更好的 V 值。
Vectorizing...
Coclustering...
Done in 1.28s. V-measure: 0.4415
MiniBatchKMeans...
Done in 2.28s. V-measure: 0.3015
Best biclusters:
----------------
bicluster 0 : 8 documents, 6 words
categories : 100% talk.politics.mideast
words : cosmo, angmar, alfalfa, alphalpha, proline, benson
bicluster 1 : 1948 documents, 4325 words
categories : 23% talk.politics.guns, 18% talk.politics.misc, 17% sci.med
words : gun, guns, geb, banks, gordon, clinton, pitt, cdt, surrender, veal
bicluster 2 : 1259 documents, 3534 words
categories : 27% soc.religion.christian, 25% talk.politics.mideast, 25% alt.atheism
words : god, jesus, christians, kent, sin, objective, belief, christ, faith, moral
bicluster 3 : 775 documents, 1623 words
categories : 30% comp.windows.x, 25% comp.sys.ibm.pc.hardware, 20% comp.graphics
words : scsi, nada, ide, vga, esdi, isa, kth, s3, vlb, bmug
bicluster 4 : 2180 documents, 2802 words
categories : 18% comp.sys.mac.hardware, 16% sci.electronics, 16% comp.sys.ibm.pc.hardware
words : voltage, shipping, circuit, receiver, processing, scope, mpce, analog, kolstad, umass
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from collections import Counter
from time import time
import numpy as np
from sklearn.cluster import MiniBatchKMeans, SpectralCoclustering
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.cluster import v_measure_score
def number_normalizer(tokens):
"""Map all numeric tokens to a placeholder.
For many applications, tokens that begin with a number are not directly
useful, but the fact that such a token exists can be relevant. By applying
this form of dimensionality reduction, some methods may perform better.
"""
return ("#NUMBER" if token[0].isdigit() else token for token in tokens)
class NumberNormalizingVectorizer(TfidfVectorizer):
def build_tokenizer(self):
tokenize = super().build_tokenizer()
return lambda doc: list(number_normalizer(tokenize(doc)))
# exclude 'comp.os.ms-windows.misc'
categories = [
"alt.atheism",
"comp.graphics",
"comp.sys.ibm.pc.hardware",
"comp.sys.mac.hardware",
"comp.windows.x",
"misc.forsale",
"rec.autos",
"rec.motorcycles",
"rec.sport.baseball",
"rec.sport.hockey",
"sci.crypt",
"sci.electronics",
"sci.med",
"sci.space",
"soc.religion.christian",
"talk.politics.guns",
"talk.politics.mideast",
"talk.politics.misc",
"talk.religion.misc",
]
newsgroups = fetch_20newsgroups(categories=categories)
y_true = newsgroups.target
vectorizer = NumberNormalizingVectorizer(stop_words="english", min_df=5)
cocluster = SpectralCoclustering(
n_clusters=len(categories), svd_method="arpack", random_state=0
)
kmeans = MiniBatchKMeans(
n_clusters=len(categories), batch_size=20000, random_state=0, n_init=3
)
print("Vectorizing...")
X = vectorizer.fit_transform(newsgroups.data)
print("Coclustering...")
start_time = time()
cocluster.fit(X)
y_cocluster = cocluster.row_labels_
print(
f"Done in {time() - start_time:.2f}s. V-measure: \
{v_measure_score(y_cocluster, y_true):.4f}"
)
print("MiniBatchKMeans...")
start_time = time()
y_kmeans = kmeans.fit_predict(X)
print(
f"Done in {time() - start_time:.2f}s. V-measure: \
{v_measure_score(y_kmeans, y_true):.4f}"
)
feature_names = vectorizer.get_feature_names_out()
document_names = list(newsgroups.target_names[i] for i in newsgroups.target)
def bicluster_ncut(i):
rows, cols = cocluster.get_indices(i)
if not (np.any(rows) and np.any(cols)):
import sys
return sys.float_info.max
row_complement = np.nonzero(np.logical_not(cocluster.rows_[i]))[0]
col_complement = np.nonzero(np.logical_not(cocluster.columns_[i]))[0]
# Note: the following is identical to X[rows[:, np.newaxis],
# cols].sum() but much faster in scipy <= 0.16
weight = X[rows][:, cols].sum()
cut = X[row_complement][:, cols].sum() + X[rows][:, col_complement].sum()
return cut / weight
bicluster_ncuts = list(bicluster_ncut(i) for i in range(len(newsgroups.target_names)))
best_idx = np.argsort(bicluster_ncuts)[:5]
print()
print("Best biclusters:")
print("----------------")
for idx, cluster in enumerate(best_idx):
n_rows, n_cols = cocluster.get_shape(cluster)
cluster_docs, cluster_words = cocluster.get_indices(cluster)
if not len(cluster_docs) or not len(cluster_words):
continue
# categories
counter = Counter(document_names[doc] for doc in cluster_docs)
cat_string = ", ".join(
f"{(c / n_rows * 100):.0f}% {name}" for name, c in counter.most_common(3)
)
# words
out_of_cluster_docs = cocluster.row_labels_ != cluster
out_of_cluster_docs = np.where(out_of_cluster_docs)[0]
word_col = X[:, cluster_words]
word_scores = np.array(
word_col[cluster_docs, :].sum(axis=0)
- word_col[out_of_cluster_docs, :].sum(axis=0)
)
word_scores = word_scores.ravel()
important_words = list(
feature_names[cluster_words[i]] for i in word_scores.argsort()[:-11:-1]
)
print(f"bicluster {idx} : {n_rows} documents, {n_cols} words")
print(f"categories : {cat_string}")
print(f"words : {', '.join(important_words)}\n")
腳本總執行時間: (0 分鐘 6.456 秒)
相關範例