跳到主要內容
返回頂部
Ctrl
+
K
安裝
使用者指南
API
範例
社群
更多
開始使用
發行歷史
詞彙表
開發
常見問題
支援
相關專案
路線圖
治理
關於我們
GitHub
選擇版本
安裝
使用者指南
API
範例
社群
開始使用
發行歷史
詞彙表
開發
常見問題
支援
相關專案
路線圖
治理
關於我們
GitHub
選擇版本
章節導覽
發行重點
scikit-learn 1.6 的發行重點
scikit-learn 1.5 的發行重點
scikit-learn 1.4 的發行重點
scikit-learn 1.3 的發行重點
scikit-learn 1.2 的發行重點
scikit-learn 1.1 的發行重點
scikit-learn 1.0 的發行重點
scikit-learn 0.24 的發行重點
scikit-learn 0.23 的發行重點
scikit-learn 0.22 的發行重點
雙向分群
譜雙向分群演算法的示範
譜共分群演算法的示範
使用譜共分群演算法對文件進行雙向分群
校準
分類器校準的比較
機率校準曲線
三類分類的機率校準
分類器的機率校準
分類
分類器比較
具有共變異數橢球的線性與二次判別分析
用於分類的常態、Ledoit-Wolf 和 OAS 線性判別分析
繪製分類機率
辨識手寫數字
分群
手寫數字資料上 K 平均分群的示範
硬幣影像上結構化 Ward 階層式分群的示範
均值漂移分群演算法的示範
分群效能評估中針對機率的調整
具有和不具有結構的聚合分群
具有不同度量的聚合分群
K-Means++ 初始化範例
二分 K 平均和常規 K 平均效能比較
比較 BIRCH 和 MiniBatchKMeans
比較玩具資料集上不同的分群演算法
比較玩具資料集上不同的階層式連結方法
K 平均和 MiniBatchKMeans 分群演算法的比較
DBSCAN 分群演算法的示範
HDBSCAN 分群演算法的示範
OPTICS 分群演算法的示範
親和力傳播分群演算法的示範
k 平均假設的示範
k 平均初始化影響的實證評估
特徵聚合
特徵聚合 vs. 單變量選擇
階層式分群:結構化 vs 非結構化 ward
歸納分群
線上學習人臉部分的字典
繪製階層式分群樹狀圖
將希臘硬幣圖片分割成區域
使用 KMeans 分群上的輪廓分析選擇叢集數量
用於影像分割的譜分群
數位 2D 嵌入上各種聚合分群
向量量化範例
共變異數估計
Ledoit-Wolf vs OAS 估計
穩健的共變異數估計和馬氏距離相關性
穩健 vs 經驗共變異數估計
收縮共變異數估計:LedoitWolf vs OAS 和最大似然
稀疏反共變異數估計
交叉分解
比較交叉分解方法
主成分迴歸 vs 部分最小平方迴歸
資料集範例
繪製隨機產生的多標籤資料集
決策樹
決策樹迴歸
繪製在虹膜資料集上訓練的決策樹的決策面
使用成本複雜度修剪來進行決策樹的後修剪
理解決策樹結構
分解
使用 FastICA 進行盲源分離
虹膜資料集 LDA 和 PCA 2D 投影的比較
人臉資料集分解
(帶旋轉的)因子分析以視覺化模式
2D 點雲上的 FastICA
使用字典學習進行影像去噪
增量 PCA
核 PCA
使用機率 PCA 和因子分析 (FA) 進行模型選擇
虹膜資料集上的主成分分析 (PCA)
使用預先計算的字典進行稀疏編碼
開發估計器
__sklearn_is_fitted__
作為開發人員 API
集成方法
梯度提升中的類別特徵支援
使用堆疊組合預測器
比較隨機森林和直方圖梯度提升模型
比較隨機森林和多輸出元估計器
具有 AdaBoost 的決策樹迴歸
梯度提升中的提前停止
使用樹林進行特徵重要性
使用樹集成進行特徵轉換
直方圖梯度提升樹中的特徵
梯度提升袋外估計
梯度提升迴歸
梯度提升正規化
使用完全隨機樹進行雜湊特徵轉換
IsolationForest 範例
單調約束
多類別 AdaBoosted 決策樹
隨機森林的袋外錯誤
繪製 VotingClassifier 計算的類別機率
繪製個別和投票迴歸預測
繪製 VotingClassifier 的決策邊界
繪製虹膜資料集上樹集成的決策面
梯度提升迴歸的預測區間
單一估計器與套袋:偏差-變異數分解
雙類別 AdaBoost
基於真實世界資料集的範例
壓縮感知:具有 L1 先驗 (Lasso) 的斷層掃描重建
使用 eigenfaces 和 SVM 的人臉辨識範例
使用核 PCA 的影像去噪
時間序列預測的滯後特徵
模型複雜度影響
文字文件的核心外分類
實際資料集上的離群值偵測
預測延遲
物種分布建模
時間相關的特徵工程
使用非負矩陣分解和潛在狄利克雷分配進行主題提取
視覺化股票市場結構
維基百科主特徵向量
特徵選擇
F 檢定和互資訊的比較
基於模型和循序的特徵選擇
管線 ANOVA SVM
遞迴特徵消除
使用交叉驗證的遞迴特徵消除
單變量特徵選擇
凍結估計器
使用
FrozenEstimator
的範例
高斯混合模型
變異數貝氏高斯混合的濃度先驗類型分析
高斯混合的密度估計
GMM 初始化方法
GMM 共變異數
高斯混合模型橢圓體
高斯混合模型選擇
高斯混合模型正弦曲線
用於機器學習的高斯過程
高斯過程迴歸 (GPR) 估計資料雜訊水準的能力
核嶺迴歸和高斯過程迴歸的比較
使用高斯過程迴歸 (GPR) 預測莫納羅亞資料集上的 CO2 水平
高斯過程迴歸:基本入門範例
虹膜資料集上的高斯過程分類 (GPC)
離散資料結構上的高斯過程
XOR 資料集上高斯過程分類 (GPC) 的說明
不同核的先驗和後驗高斯過程的說明
高斯過程分類 (GPC) 的等機率線
使用高斯過程分類 (GPC) 進行機率預測
廣義線性模型
比較線性貝氏迴歸器
比較各種線上求解器
使用貝氏嶺迴歸進行曲線擬合
多項式和一對其餘邏輯迴歸的決策邊界
隨機梯度下降的提前停止
使用預先計算的 Gram 矩陣和加權樣本擬合彈性網路
具有強烈離群值的資料集上的 HuberRegressor 與 Ridge
使用多任務 Lasso 進行聯合特徵選擇
邏輯迴歸中的 L1 懲罰和稀疏性
用於稀疏訊號的基於 L1 的模型
透過資訊準則進行 Lasso 模型選擇
Lasso 模型選擇:AIC-BIC / 交叉驗證
稠密和稀疏資料上的 Lasso
Lasso、Lasso-LARS 和彈性網路路徑
邏輯函數
使用多項式邏輯 + L1 進行 MNIST 分類
20newgroups 上的多類別稀疏邏輯迴歸
非負最小平方
一類 SVM 與使用隨機梯度下降的一類 SVM
普通最小平方法範例
普通最小平方法和嶺迴歸變異數
正交匹配追蹤
繪製嶺係數作為正規化的函數
繪製虹膜資料集上的多類別 SGD
泊松迴歸和非常態損失
多項式和樣條內插
分位數迴歸
L1 邏輯迴歸的正規化路徑
嶺係數作為 L2 正規化的函數
穩健線性估計器擬合
使用 RANSAC 進行穩健線性模型估計
SGD:最大邊距分離超平面
SGD:懲罰
SGD:加權樣本
SGD:凸損失函數
Theil-Sen 迴歸
保險索賠的 Tweedie 迴歸
檢查
線性模型係數解釋中的常見陷阱
機器學習無法推斷因果效應
部分依賴和個別條件期望圖
排列重要性 vs 隨機森林特徵重要性 (MDI)
具有多重共線性或相關特徵的排列重要性
核近似
使用多項式核近似進行可擴展學習
流形學習
流形學習方法的比較
在切斷球體上的流形學習方法
手寫數字上的流形學習:局部線性嵌入、Isomap…
多維尺度
瑞士捲和瑞士孔縮減
t-SNE:各種困惑值對形狀的影響
雜項
具有部分依賴的高階繪圖
比較玩具資料集上離群值偵測的異常偵測演算法
核嶺迴歸和 SVR 的比較
顯示管線
顯示估計器和複雜管線
離群值偵測估計器的評估
RBF 核的顯式特徵映射近似
使用多輸出估計器完成人臉
介紹
set_output
API
等張迴歸 (Isotonic Regression)
元數據路由 (Metadata Routing)
多標籤分類 (Multilabel classification)
使用可視化 API 的 ROC 曲線
使用隨機投影進行嵌入的 Johnson-Lindenstrauss 界限
使用顯示物件的可視化
缺失值填補 (Missing Value Imputation)
在建立估計器之前填補缺失值
使用 IterativeImputer 的變體填補缺失值
模型選擇 (Model Selection)
平衡模型複雜度和交叉驗證分數
使用類別似然比來衡量分類效能
比較用於超參數估計的隨機搜尋和網格搜尋
網格搜尋和連續減半之間的比較
混淆矩陣 (Confusion matrix)
使用交叉驗證的網格搜尋的自訂重新擬合策略
在 cross_val_score 和 GridSearchCV 上演示多指標評估
檢測錯誤權衡 (DET) 曲線
模型正規化對訓練和測試錯誤的影響
多類別接收者操作特徵 (ROC)
巢狀與非巢狀交叉驗證
繪製交叉驗證預測
繪製學習曲線並檢查模型的可擴展性
事後調整決策函數的截止點
事後調整成本敏感學習的決策閾值
精確率-召回率 (Precision-Recall)
使用交叉驗證的接收者操作特徵 (ROC)
用於文字特徵提取和評估的範例管道
使用網格搜尋對模型進行統計比較
連續減半迭代
使用排列測試分類分數的顯著性
欠擬合與過擬合 (Underfitting vs. Overfitting)
可視化 scikit-learn 中的交叉驗證行為
多類別方法
多類別訓練元估計器概述
多輸出方法
使用分類器鏈進行多標籤分類
最近鄰 (Nearest Neighbors)
TSNE 中的近似最近鄰
快取最近鄰
比較具有和不具有鄰域成分分析的最近鄰
使用鄰域成分分析進行降維
物種分佈的核密度估計
核密度估計 (Kernel Density Estimation)
最近質心分類 (Nearest Centroid Classification)
最近鄰分類 (Nearest Neighbors Classification)
最近鄰迴歸 (Nearest Neighbors regression)
鄰域成分分析說明
使用局部離群因子 (LOF) 進行新穎性檢測
使用局部離群因子 (LOF) 進行離群值檢測
簡單的 1D 核密度估計
神經網路 (Neural Networks)
比較 MLPClassifier 的隨機學習策略
用於數字分類的受限波茲曼機特徵
多層感知器中的不同正規化
MNIST 上 MLP 權重的可視化
管道和複合估計器
具有異質數據來源的 Column Transformer
具有混合類型的 Column Transformer
串聯多個特徵提取方法
轉換迴歸模型中目標的影響
管道化:鏈接 PCA 和邏輯迴歸
使用 Pipeline 和 GridSearchCV 選擇降維
預處理 (Preprocessing)
比較不同縮放器對具有離群值數據的影響
比較目標編碼器與其他編碼器
示範 KBinsDiscretizer 的不同策略
特徵離散化 (Feature discretization)
特徵縮放的重要性
將數據映射到常態分佈
目標編碼器的內部交叉擬合
使用 KBinsDiscretizer 離散化連續特徵
半監督分類 (Semi Supervised Classification)
半監督分類器與 SVM 在 Iris 數據集上的決策邊界
自訓練不同閾值的影響
標籤傳播數字主動學習
標籤傳播數字:示範效能
標籤傳播學習複雜結構
文字數據集上的半監督分類
支持向量機 (Support Vector Machines)
具有非線性核 (RBF) 的單類 SVM
繪製具有不同 SVM 核的分類邊界
繪製 Iris 數據集中不同的 SVM 分類器
繪製 LinearSVC 中的支持向量
RBF SVM 參數
SVM 邊距範例
SVM 平手打破範例
具有自訂核的 SVM
SVM-Anova:具有單變量特徵選擇的 SVM
SVM:最大邊距分離超平面
SVM:不平衡類別的分離超平面
SVM:加權樣本
縮放 SVC 的正規化參數
使用線性和非線性核的支持向量迴歸 (SVR)
教學練習
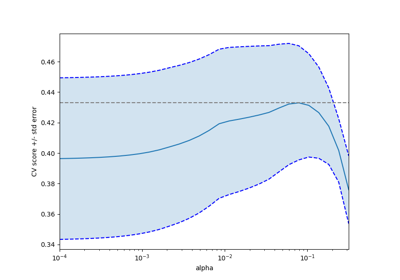
糖尿病數據集練習的交叉驗證
數字分類練習
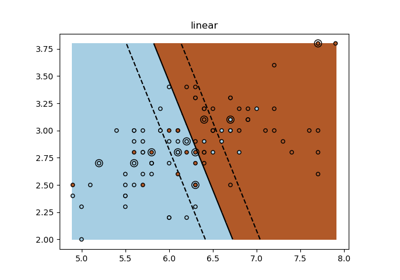
SVM 練習
使用文字文件
使用稀疏特徵對文字文件進行分類
使用 k-means 對文字文件進行分群
FeatureHasher 和 DictVectorizer 的比較
範例
教學練習
教學練習
#
教學的練習
糖尿病數據集練習的交叉驗證
糖尿病數據集練習的交叉驗證
數字分類練習
數字分類練習
SVM 練習
SVM 練習