注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
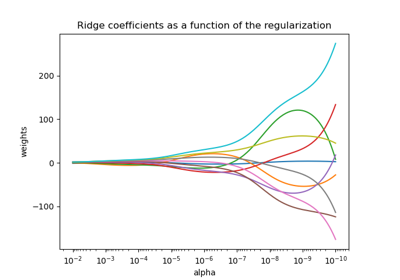
Ridge 係數作為 L2 正規化的函數#
一個過度擬合的模型會過度學習訓練資料,同時捕獲資料中的潛在模式和雜訊。但是,當應用於未見過的資料時,學習到的關聯可能無效。當我們將訓練好的預測應用於測試資料,並且看到統計效能與訓練資料相比顯著下降時,通常會偵測到這種情況。
克服過度擬合的一種方法是透過正規化,這可以透過懲罰線性模型中的大型權重(係數)來完成,迫使模型縮小所有係數。正規化減少了模型對從訓練樣本獲得的特定資訊的依賴。
這個範例說明了 Ridge 迴歸中的 L2 正規化如何透過在損失中加入一個隨係數 \(\beta\) 增加的懲罰項來影響模型的效能。
正規化後的損失函數由下式給出:\(\mathcal{L}(X, y, \beta) = \| y - X \beta \|^{2}_{2} + \alpha \| \beta \|^{2}_{2}\)
其中 \(X\) 是輸入資料,\(y\) 是目標變數,\(\beta\) 是與特徵相關的係數向量,而 \(\alpha\) 是正規化強度。
正規化後的損失函數旨在平衡準確預測訓練集和防止過度擬合之間的權衡。
在這個正規化的損失中,左側(例如 \(\|y - X\beta\|^{2}_{2}\))衡量實際目標變數 \(y\) 與預測值之間的平方差。僅最小化這個項可能會導致過度擬合,因為模型可能會變得過於複雜並且對訓練資料中的雜訊敏感。
為了解決過度擬合,Ridge 正規化在損失函數中加入了一個約束,稱為懲罰項(\(\alpha \| \beta\|^{2}_{2}\))。這個懲罰項是模型係數的平方和,乘以正規化強度 \(\alpha\)。透過引入此約束,Ridge 正規化阻止任何單個係數 \(\beta_{i}\) 採用過大的值,並鼓勵較小且更均勻分佈的係數。\(\alpha\) 的值越高,會迫使係數趨於零。但是,過高的 \(\alpha\) 可能會導致欠擬合模型,無法捕捉到資料中的重要模式。
因此,正規化後的損失函數結合了預測準確度項和懲罰項。透過調整正規化強度,實務人員可以微調施加在權重上的約束程度,訓練出一個能夠很好地泛化到未見過的資料同時避免過度擬合的模型。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
此範例的目的#
為了展示 Ridge 正規化的工作原理,我們將建立一個無雜訊的資料集。然後我們將在一系列正規化強度(\(\alpha\))上訓練一個正規化模型,並繪製訓練後的係數以及它們與原始值之間的均方誤差如何作為正規化強度的函數表現。
建立無雜訊資料集#
我們建立一個具有 100 個樣本和 10 個特徵的玩具資料集,適用於檢測迴歸。在這 10 個特徵中,有 8 個特徵是有資訊的,並有助於迴歸,而其餘 2 個特徵對目標變數沒有任何影響(它們的真實係數為 0)。請注意,在此範例中,資料是無雜訊的,因此我們可以預期我們的迴歸模型會準確地恢復真實係數 w。
from sklearn.datasets import make_regression
X, y, w = make_regression(
n_samples=100, n_features=10, n_informative=8, coef=True, random_state=1
)
# Obtain the true coefficients
print(f"The true coefficient of this regression problem are:\n{w}")
The true coefficient of this regression problem are:
[38.32634568 88.49665188 0. 29.75747153 0. 19.08699432
25.44381023 38.69892343 49.28808734 71.75949622]
訓練 Ridge 迴歸器#
我們使用 Ridge,這是一個具有 L2 正規化的線性模型。我們訓練幾個模型,每個模型對於模型參數 alpha 都有不同的值,alpha 是一個正常數,它乘以懲罰項,控制正規化強度。對於每個訓練好的模型,我們然後計算真實係數 w 與模型 clf 找到的係數之間的誤差。我們將識別出的係數和計算出的相應係數的誤差儲存在列表中,這讓我們可以方便地繪製它們。
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
clf = Ridge()
# Generate values for `alpha` that are evenly distributed on a logarithmic scale
alphas = np.logspace(-3, 4, 200)
coefs = []
errors_coefs = []
# Train the model with different regularisation strengths
for a in alphas:
clf.set_params(alpha=a).fit(X, y)
coefs.append(clf.coef_)
errors_coefs.append(mean_squared_error(clf.coef_, w))
繪製訓練後的係數和均方誤差#
我們現在將 10 個不同的正規化係數繪製為正規化參數 alpha 的函數,其中每種顏色代表不同的係數。
在右側,我們繪製了估計器的係數誤差如何隨著正規化的函數而變化。
import matplotlib.pyplot as plt
import pandas as pd
alphas = pd.Index(alphas, name="alpha")
coefs = pd.DataFrame(coefs, index=alphas, columns=[f"Feature {i}" for i in range(10)])
errors = pd.Series(errors_coefs, index=alphas, name="Mean squared error")
fig, axs = plt.subplots(1, 2, figsize=(20, 6))
coefs.plot(
ax=axs[0],
logx=True,
title="Ridge coefficients as a function of the regularization strength",
)
axs[0].set_ylabel("Ridge coefficient values")
errors.plot(
ax=axs[1],
logx=True,
title="Coefficient error as a function of the regularization strength",
)
_ = axs[1].set_ylabel("Mean squared error")
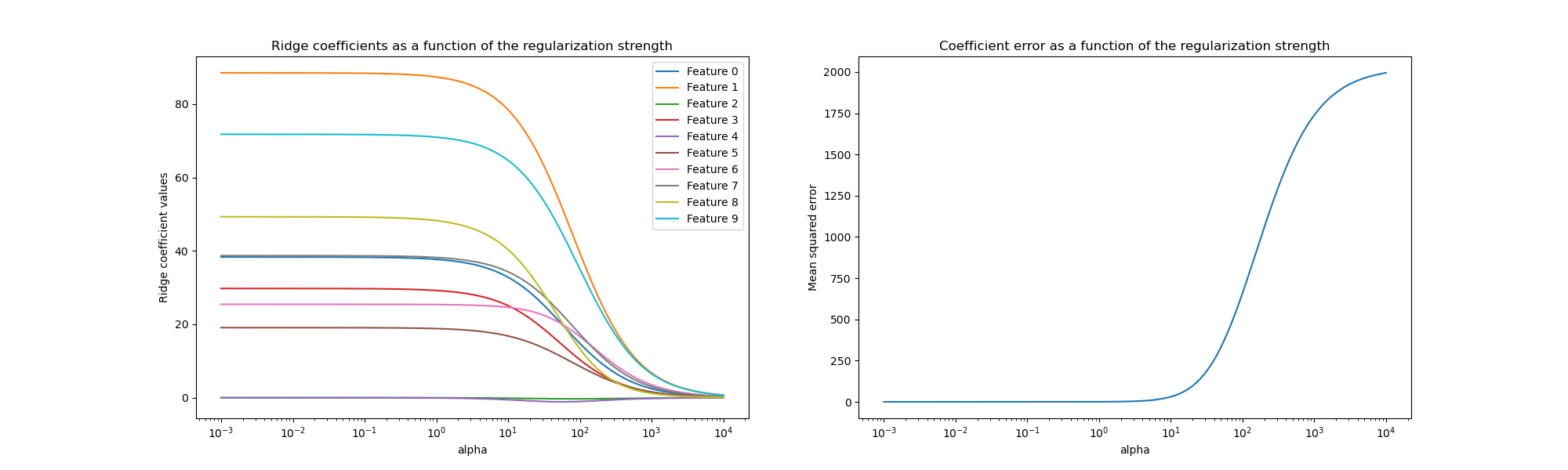
解釋圖表#
左側的圖表顯示了正規化強度 (alpha) 如何影響 Ridge 迴歸係數。較小的 alpha 值(弱正規化)允許係數與用於產生資料集的真實係數 (w) 非常相似。這是因為沒有將額外的雜訊加入到我們的人工資料集中。隨著 alpha 增加,係數會向零縮小,逐漸減少以前更重要的特徵的影響。
右側的圖表顯示模型找到的係數與真實係數(w)之間的均方誤差(MSE)。它提供了一個衡量標準,可以比較我們的嶺迴歸模型與真實生成模型的精確程度。較低的誤差表示找到的係數更接近真實生成模型的係數。在這個例子中,由於我們的玩具數據集沒有雜訊,我們可以看到,正規化程度最小的模型所檢索到的係數最接近真實係數(w)(誤差接近於 0)。
當 alpha 值較小時,模型會捕捉訓練數據的細微細節,無論這些細節是由雜訊還是實際資訊引起的。隨著 alpha 值的增加,最高的係數會更快地縮小,使其對應的特徵在訓練過程中的影響力降低。這可以增強模型泛化到未見數據的能力(如果有很多雜訊需要捕捉),但如果正規化相對於數據中包含的雜訊量而言變得太強,也存在性能損失的風險(如本例所示)。
在真實世界的場景中,數據通常包含雜訊,因此選擇適當的 alpha 值對於在過擬合和欠擬合模型之間取得平衡至關重要。
在這裡,我們看到 Ridge 通過對係數施加懲罰來對抗過擬合。另一個會發生的問題與訓練數據集中存在離群值有關。離群值是指與其他觀測值顯著不同的數據點。具體而言,這些離群值會影響我們之前展示的損失函數的左側項。一些其他線性模型被設計為對離群值具有穩健性,例如 HuberRegressor。您可以在 HuberRegressor 與 Ridge 在具有強離群值的數據集上的比較 範例中了解更多資訊。
腳本的總運行時間:(0 分鐘 0.745 秒)
相關範例