注意
前往末尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
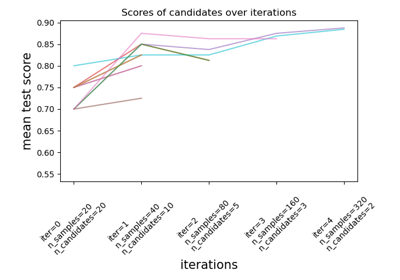
比較用於超參數估計的隨機搜尋和網格搜尋#
比較隨機搜尋和網格搜尋,以使用 SGD 訓練來最佳化線性 SVM 的超參數。同時搜尋所有影響學習的參數(估計器的數量除外,這會造成時間/品質的權衡)。
隨機搜尋和網格搜尋會探索完全相同的參數空間。參數設定的結果非常相似,而隨機搜尋的執行時間則大幅縮短。
隨機搜尋的效能可能略差,這可能是由於雜訊效應,並且不會延續到保留的測試集。
請注意,在實務上,不會使用網格搜尋同時搜尋這麼多不同的參數,而是只選擇那些被認為最重要的參數。
RandomizedSearchCV took 1.29 seconds for 15 candidates parameter settings.
Model with rank: 1
Mean validation score: 0.991 (std: 0.006)
Parameters: {'alpha': np.float64(0.05063247886572012), 'average': False, 'l1_ratio': np.float64(0.13822072286080167)}
Model with rank: 2
Mean validation score: 0.987 (std: 0.014)
Parameters: {'alpha': np.float64(0.010877306503748912), 'average': True, 'l1_ratio': np.float64(0.9226260871125187)}
Model with rank: 3
Mean validation score: 0.976 (std: 0.023)
Parameters: {'alpha': np.float64(0.727148206404819), 'average': False, 'l1_ratio': np.float64(0.25183501383331797)}
GridSearchCV took 4.06 seconds for 60 candidate parameter settings.
Model with rank: 1
Mean validation score: 0.993 (std: 0.011)
Parameters: {'alpha': np.float64(0.1), 'average': False, 'l1_ratio': np.float64(0.1111111111111111)}
Model with rank: 2
Mean validation score: 0.987 (std: 0.013)
Parameters: {'alpha': np.float64(0.01), 'average': False, 'l1_ratio': np.float64(0.5555555555555556)}
Model with rank: 3
Mean validation score: 0.987 (std: 0.007)
Parameters: {'alpha': np.float64(0.01), 'average': False, 'l1_ratio': np.float64(0.0)}
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from time import time
import numpy as np
import scipy.stats as stats
from sklearn.datasets import load_digits
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
# get some data
X, y = load_digits(return_X_y=True, n_class=3)
# build a classifier
clf = SGDClassifier(loss="hinge", penalty="elasticnet", fit_intercept=True)
# Utility function to report best scores
def report(results, n_top=3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results["rank_test_score"] == i)
for candidate in candidates:
print("Model with rank: {0}".format(i))
print(
"Mean validation score: {0:.3f} (std: {1:.3f})".format(
results["mean_test_score"][candidate],
results["std_test_score"][candidate],
)
)
print("Parameters: {0}".format(results["params"][candidate]))
print("")
# specify parameters and distributions to sample from
param_dist = {
"average": [True, False],
"l1_ratio": stats.uniform(0, 1),
"alpha": stats.loguniform(1e-2, 1e0),
}
# run randomized search
n_iter_search = 15
random_search = RandomizedSearchCV(
clf, param_distributions=param_dist, n_iter=n_iter_search
)
start = time()
random_search.fit(X, y)
print(
"RandomizedSearchCV took %.2f seconds for %d candidates parameter settings."
% ((time() - start), n_iter_search)
)
report(random_search.cv_results_)
# use a full grid over all parameters
param_grid = {
"average": [True, False],
"l1_ratio": np.linspace(0, 1, num=10),
"alpha": np.power(10, np.arange(-2, 1, dtype=float)),
}
# run grid search
grid_search = GridSearchCV(clf, param_grid=param_grid)
start = time()
grid_search.fit(X, y)
print(
"GridSearchCV took %.2f seconds for %d candidate parameter settings."
% (time() - start, len(grid_search.cv_results_["params"]))
)
report(grid_search.cv_results_)
腳本的總執行時間:(0 分鐘 5.365 秒)
相關範例