注意
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
決策樹回歸#
在這個範例中,我們示範變更決策樹的最大深度對其如何擬合資料的影響。我們在 1D 回歸任務上執行一次,在多輸出回歸任務上執行一次。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
1D 回歸任務上的決策樹#
在這裡,我們將樹擬合到 1D 回歸任務上。
使用 決策樹 來擬合具有附加雜訊觀測值的正弦曲線。因此,它學習近似正弦曲線的局部線性回歸。
我們可以看到,如果樹的最大深度(由 max_depth 參數控制)設定得太高,決策樹會學習訓練資料的過於精細的細節,並從雜訊中學習,也就是說,它們會過度擬合。
建立隨機 1D 資料集#
import numpy as np
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
擬合回歸模型#
在這裡,我們擬合兩個具有不同最大深度的模型
from sklearn.tree import DecisionTreeRegressor
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)
預測#
取得測試集的預測
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
繪製結果#
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
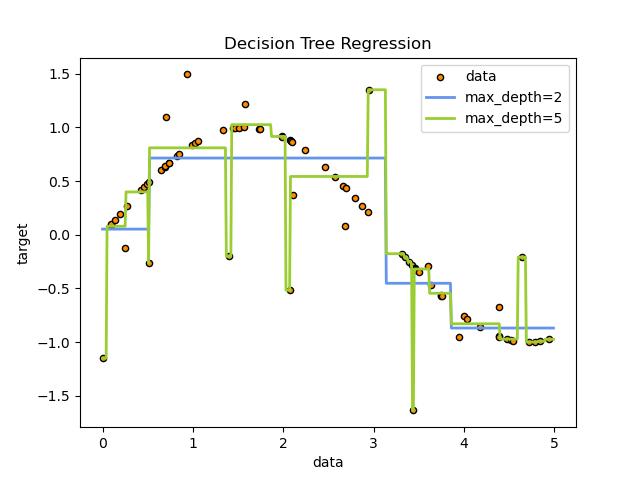
如您所見,深度為 5 的模型(黃色)學習訓練資料的細節,以至於它過度擬合雜訊。另一方面,深度為 2 的模型(藍色)很好地學習了資料中的主要趨勢,並且不會過度擬合。在實際使用案例中,您需要確保樹不會過度擬合訓練資料,這可以使用交叉驗證來完成。
具有多輸出目標的決策樹回歸#
在這裡,使用 決策樹 來同時預測給定單一基礎特徵的圓形的雜訊 x 和 y 觀測值。因此,它學習近似圓形的局部線性回歸。
我們可以看到,如果樹的最大深度(由 max_depth 參數控制)設定得太高,決策樹會學習訓練資料的過於精細的細節,並從雜訊中學習,也就是說,它們會過度擬合。
建立隨機資料集#
擬合回歸模型#
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_3 = DecisionTreeRegressor(max_depth=8)
regr_1.fit(X, y)
regr_2.fit(X, y)
regr_3.fit(X, y)
預測#
取得測試集的預測
X_test = np.arange(-100.0, 100.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
y_3 = regr_3.predict(X_test)
繪製結果#
plt.figure()
s = 25
plt.scatter(y[:, 0], y[:, 1], c="yellow", s=s, edgecolor="black", label="data")
plt.scatter(
y_1[:, 0],
y_1[:, 1],
c="cornflowerblue",
s=s,
edgecolor="black",
label="max_depth=2",
)
plt.scatter(y_2[:, 0], y_2[:, 1], c="red", s=s, edgecolor="black", label="max_depth=5")
plt.scatter(y_3[:, 0], y_3[:, 1], c="blue", s=s, edgecolor="black", label="max_depth=8")
plt.xlim([-6, 6])
plt.ylim([-6, 6])
plt.xlabel("target 1")
plt.ylabel("target 2")
plt.title("Multi-output Decision Tree Regression")
plt.legend(loc="best")
plt.show()
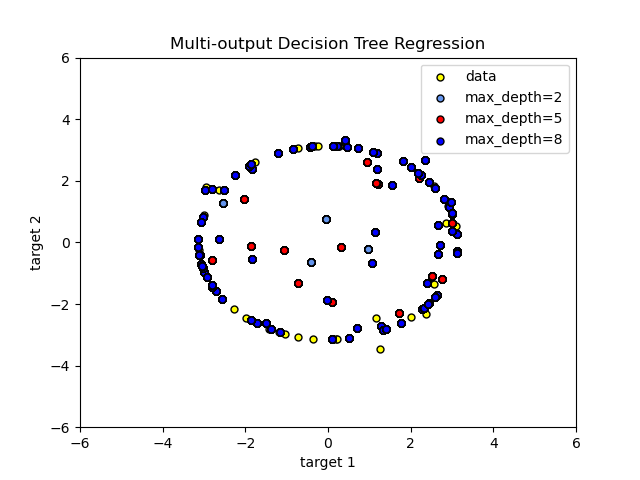
如您所見,max_depth 的值越高,模型捕獲的資料細節就越多。但是,該模型也會過度擬合資料並受雜訊影響。
腳本的總執行時間:(0 分鐘 0.314 秒)
相關範例