註記
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
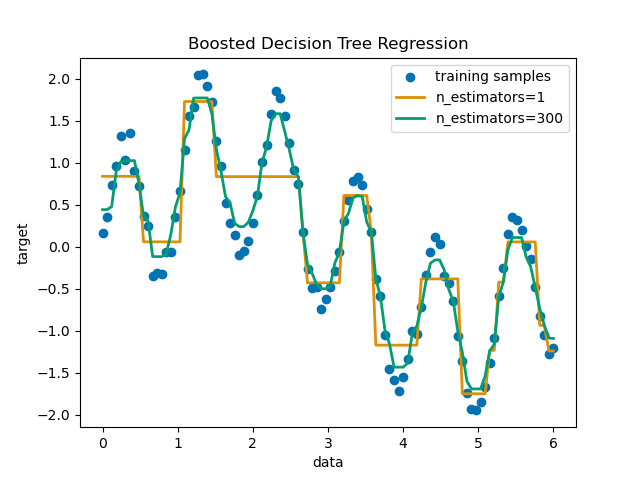
使用 AdaBoost 的決策樹迴歸#
使用 AdaBoost.R2 [1] 演算法在具有少量高斯雜訊的 1D 正弦資料集上增強決策樹。將 299 次增強(300 個決策樹)與單個決策樹迴歸器進行比較。隨著增強次數的增加,迴歸器可以擬合更多細節。
請參閱 直方圖梯度提升樹中的特徵,以取得展示使用更有效率迴歸模型(例如 HistGradientBoostingRegressor)的好處的範例。
準備資料#
首先,我們準備具有正弦關係和一些高斯雜訊的虛擬資料。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import numpy as np
rng = np.random.RandomState(1)
X = np.linspace(0, 6, 100)[:, np.newaxis]
y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0, 0.1, X.shape[0])
使用決策樹和 AdaBoost 迴歸器進行訓練和預測#
現在,我們定義分類器並將它們擬合到資料。然後我們預測相同的資料,以查看它們的擬合程度。第一個迴歸器是 DecisionTreeRegressor,其中 max_depth=4。第二個迴歸器是 AdaBoostRegressor,以 max_depth=4 的 DecisionTreeRegressor 作為基礎學習器,並將使用 n_estimators=300 個這些基礎學習器來建構。
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor
regr_1 = DecisionTreeRegressor(max_depth=4)
regr_2 = AdaBoostRegressor(
DecisionTreeRegressor(max_depth=4), n_estimators=300, random_state=rng
)
regr_1.fit(X, y)
regr_2.fit(X, y)
y_1 = regr_1.predict(X)
y_2 = regr_2.predict(X)
繪製結果#
最後,我們繪製出我們的兩個迴歸器(單個決策樹迴歸器和 AdaBoost 迴歸器)擬合資料的效果。
import matplotlib.pyplot as plt
import seaborn as sns
colors = sns.color_palette("colorblind")
plt.figure()
plt.scatter(X, y, color=colors[0], label="training samples")
plt.plot(X, y_1, color=colors[1], label="n_estimators=1", linewidth=2)
plt.plot(X, y_2, color=colors[2], label="n_estimators=300", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Boosted Decision Tree Regression")
plt.legend()
plt.show()
腳本的總執行時間:(0 分鐘 0.505 秒)
相關範例