注意
前往結尾以下載完整的範例程式碼。或通過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
譜雙叢集演算法的示範#
此範例示範如何生成棋盤資料集,並使用 SpectralBiclustering 演算法進行雙叢集。譜雙叢集演算法專門設計用於同時考慮矩陣的行(樣本)和列(特徵)來叢集資料。它的目標不僅是在樣本之間,而且在樣本的子集中識別模式,從而可以偵測資料中的局部結構。這使得譜雙叢集特別適合於特徵的順序或排列固定的資料集,例如影像、時間序列或基因組。
生成資料,然後打亂並傳遞給譜雙叢集演算法。然後重新排列打亂矩陣的行和列,以繪製找到的雙叢集。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
生成範例資料#
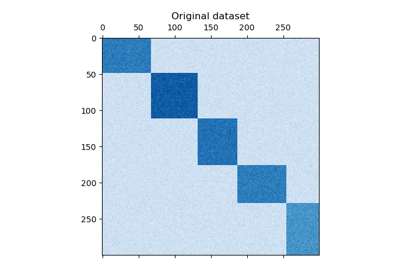
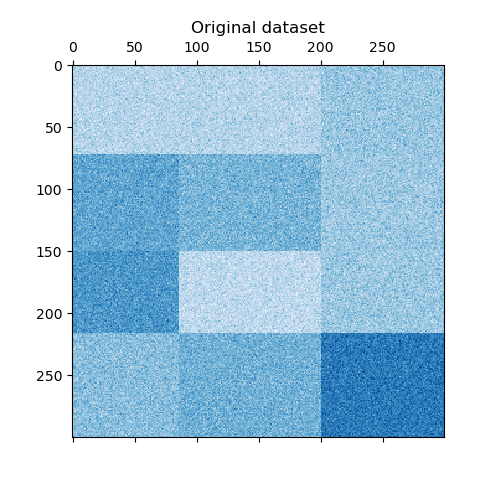
我們使用 make_checkerboard 函數生成範例資料。 shape=(300, 300) 內的每個像素都以其顏色表示來自均勻分佈的值。雜訊是從常態分佈新增的,其中為 noise 選擇的值是標準差。
如您所見,資料分佈在 12 個叢集單元格中,並且相對容易區分。
from matplotlib import pyplot as plt
from sklearn.datasets import make_checkerboard
n_clusters = (4, 3)
data, rows, columns = make_checkerboard(
shape=(300, 300), n_clusters=n_clusters, noise=10, shuffle=False, random_state=42
)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
_ = plt.show()
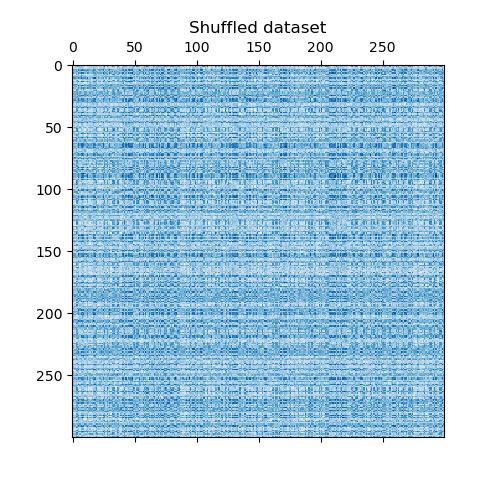
我們打亂資料,目標是之後使用 SpectralBiclustering 重建資料。
import numpy as np
# Creating lists of shuffled row and column indices
rng = np.random.RandomState(0)
row_idx_shuffled = rng.permutation(data.shape[0])
col_idx_shuffled = rng.permutation(data.shape[1])
我們重新定義打亂的資料並繪製它。我們觀察到我們失去了原始資料矩陣的結構。
data = data[row_idx_shuffled][:, col_idx_shuffled]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
_ = plt.show()
擬合 SpectralBiclustering#
我們擬合模型並將獲得的叢集與真實值進行比較。請注意,在建立模型時,我們指定了用於建立資料集的相同叢集數量(n_clusters = (4, 3)),這將有助於獲得良好的結果。
from sklearn.cluster import SpectralBiclustering
from sklearn.metrics import consensus_score
model = SpectralBiclustering(n_clusters=n_clusters, method="log", random_state=0)
model.fit(data)
# Compute the similarity of two sets of biclusters
score = consensus_score(
model.biclusters_, (rows[:, row_idx_shuffled], columns[:, col_idx_shuffled])
)
print(f"consensus score: {score:.1f}")
consensus score: 1.0
分數介於 0 和 1 之間,其中 1 對應於完美的匹配。它顯示了雙叢集的品質。
繪製結果#
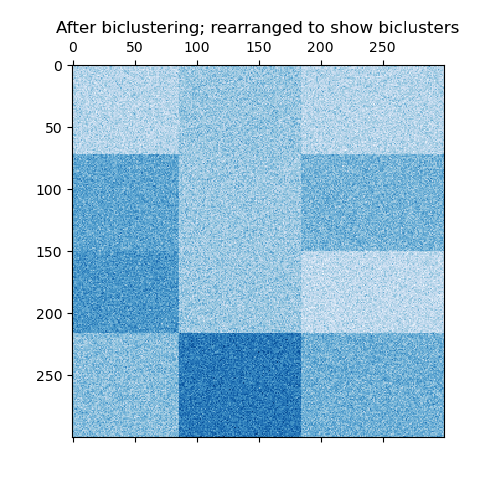
現在,我們根據 SpectralBiclustering 模型分配的行和列標籤按升序重新排列資料,並再次繪製。 row_labels_ 的範圍從 0 到 3,而 column_labels_ 的範圍從 0 到 2,表示每行總共有 4 個叢集,每列總共有 3 個叢集。
# Reordering first the rows and then the columns.
reordered_rows = data[np.argsort(model.row_labels_)]
reordered_data = reordered_rows[:, np.argsort(model.column_labels_)]
plt.matshow(reordered_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
_ = plt.show()
最後一步,我們要示範模型分配的行和列標籤之間的關係。因此,我們建立一個具有 numpy.outer 的網格,它會取得排序後的 row_labels_ 和 column_labels_,並將 1 新增到每個,以確保標籤從 1 而不是 0 開始,以便更好地視覺化。
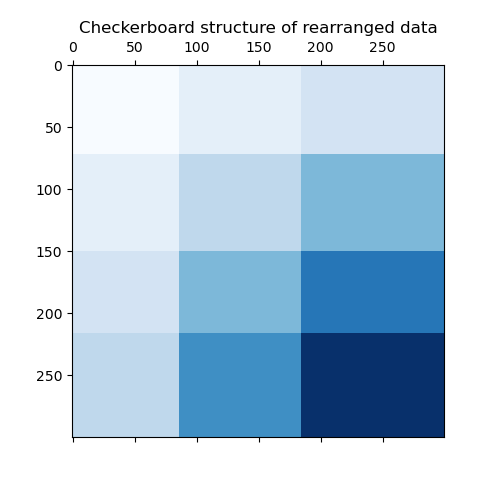
行和列標籤向量的外積顯示了棋盤結構的表示,其中行和列標籤的不同組合由不同深淺的藍色表示。
腳本總執行時間:(0 分鐘 0.576 秒)
相關範例