註
跳至結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
保險索賠的 Tweedie 迴歸#
此範例說明如何在法國汽車第三方責任索賠資料集上使用 Poisson、Gamma 和 Tweedie 迴歸,並受到 R 教學課程的啟發[1]。
在此資料集中,每個樣本都對應於一份保險單,即保險公司和個人(保戶)之間的合約。可用的特徵包括駕駛人年齡、車輛年齡、車輛功率等。
一些定義:索賠是指保戶向保險公司提出的,要求賠償保險涵蓋損失的請求。索賠金額是指保險公司必須支付的金額。曝險是指特定保險單的保險涵蓋期限,以年為單位。
這裡我們的目標是預測每個曝險單位總索賠金額的期望值,也稱為純保費。
有多種可能性可以做到這一點,其中兩種是
使用 Poisson 分佈為索賠次數建模,並以 Gamma 分佈為每次索賠的平均索賠金額建模,也稱為嚴重性,並將兩者的預測相乘,以獲得總索賠金額。
直接為每個曝險的總索賠金額建模,通常使用 Tweedie 冪 \(p \in (1, 2)\) 的 Tweedie 分佈。
在此範例中,我們將說明這兩種方法。首先,我們定義一些輔助函數,用於載入資料和視覺化結果。
from functools import partial
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.metrics import (
mean_absolute_error,
mean_squared_error,
mean_tweedie_deviance,
)
def load_mtpl2(n_samples=None):
"""Fetch the French Motor Third-Party Liability Claims dataset.
Parameters
----------
n_samples: int, default=None
number of samples to select (for faster run time). Full dataset has
678013 samples.
"""
# freMTPL2freq dataset from https://www.openml.org/d/41214
df_freq = fetch_openml(data_id=41214, as_frame=True).data
df_freq["IDpol"] = df_freq["IDpol"].astype(int)
df_freq.set_index("IDpol", inplace=True)
# freMTPL2sev dataset from https://www.openml.org/d/41215
df_sev = fetch_openml(data_id=41215, as_frame=True).data
# sum ClaimAmount over identical IDs
df_sev = df_sev.groupby("IDpol").sum()
df = df_freq.join(df_sev, how="left")
df["ClaimAmount"] = df["ClaimAmount"].fillna(0)
# unquote string fields
for column_name in df.columns[[t is object for t in df.dtypes.values]]:
df[column_name] = df[column_name].str.strip("'")
return df.iloc[:n_samples]
def plot_obs_pred(
df,
feature,
weight,
observed,
predicted,
y_label=None,
title=None,
ax=None,
fill_legend=False,
):
"""Plot observed and predicted - aggregated per feature level.
Parameters
----------
df : DataFrame
input data
feature: str
a column name of df for the feature to be plotted
weight : str
column name of df with the values of weights or exposure
observed : str
a column name of df with the observed target
predicted : DataFrame
a dataframe, with the same index as df, with the predicted target
fill_legend : bool, default=False
whether to show fill_between legend
"""
# aggregate observed and predicted variables by feature level
df_ = df.loc[:, [feature, weight]].copy()
df_["observed"] = df[observed] * df[weight]
df_["predicted"] = predicted * df[weight]
df_ = (
df_.groupby([feature])[[weight, "observed", "predicted"]]
.sum()
.assign(observed=lambda x: x["observed"] / x[weight])
.assign(predicted=lambda x: x["predicted"] / x[weight])
)
ax = df_.loc[:, ["observed", "predicted"]].plot(style=".", ax=ax)
y_max = df_.loc[:, ["observed", "predicted"]].values.max() * 0.8
p2 = ax.fill_between(
df_.index,
0,
y_max * df_[weight] / df_[weight].values.max(),
color="g",
alpha=0.1,
)
if fill_legend:
ax.legend([p2], ["{} distribution".format(feature)])
ax.set(
ylabel=y_label if y_label is not None else None,
title=title if title is not None else "Train: Observed vs Predicted",
)
def score_estimator(
estimator,
X_train,
X_test,
df_train,
df_test,
target,
weights,
tweedie_powers=None,
):
"""Evaluate an estimator on train and test sets with different metrics"""
metrics = [
("D² explained", None), # Use default scorer if it exists
("mean abs. error", mean_absolute_error),
("mean squared error", mean_squared_error),
]
if tweedie_powers:
metrics += [
(
"mean Tweedie dev p={:.4f}".format(power),
partial(mean_tweedie_deviance, power=power),
)
for power in tweedie_powers
]
res = []
for subset_label, X, df in [
("train", X_train, df_train),
("test", X_test, df_test),
]:
y, _weights = df[target], df[weights]
for score_label, metric in metrics:
if isinstance(estimator, tuple) and len(estimator) == 2:
# Score the model consisting of the product of frequency and
# severity models.
est_freq, est_sev = estimator
y_pred = est_freq.predict(X) * est_sev.predict(X)
else:
y_pred = estimator.predict(X)
if metric is None:
if not hasattr(estimator, "score"):
continue
score = estimator.score(X, y, sample_weight=_weights)
else:
score = metric(y, y_pred, sample_weight=_weights)
res.append({"subset": subset_label, "metric": score_label, "score": score})
res = (
pd.DataFrame(res)
.set_index(["metric", "subset"])
.score.unstack(-1)
.round(4)
.loc[:, ["train", "test"]]
)
return res
載入資料集、基本特徵提取和目標定義#
我們透過將包含索賠次數 (ClaimNb) 的 freMTPL2freq 表,與包含相同保單 ID (IDpol) 的索賠金額 (ClaimAmount) 的 freMTPL2sev 表合併,來建構 freMTPL2 資料集。
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import (
FunctionTransformer,
KBinsDiscretizer,
OneHotEncoder,
StandardScaler,
)
df = load_mtpl2()
# Correct for unreasonable observations (that might be data error)
# and a few exceptionally large claim amounts
df["ClaimNb"] = df["ClaimNb"].clip(upper=4)
df["Exposure"] = df["Exposure"].clip(upper=1)
df["ClaimAmount"] = df["ClaimAmount"].clip(upper=200000)
# If the claim amount is 0, then we do not count it as a claim. The loss function
# used by the severity model needs strictly positive claim amounts. This way
# frequency and severity are more consistent with each other.
df.loc[(df["ClaimAmount"] == 0) & (df["ClaimNb"] >= 1), "ClaimNb"] = 0
log_scale_transformer = make_pipeline(
FunctionTransformer(func=np.log), StandardScaler()
)
column_trans = ColumnTransformer(
[
(
"binned_numeric",
KBinsDiscretizer(n_bins=10, random_state=0),
["VehAge", "DrivAge"],
),
(
"onehot_categorical",
OneHotEncoder(),
["VehBrand", "VehPower", "VehGas", "Region", "Area"],
),
("passthrough_numeric", "passthrough", ["BonusMalus"]),
("log_scaled_numeric", log_scale_transformer, ["Density"]),
],
remainder="drop",
)
X = column_trans.fit_transform(df)
# Insurances companies are interested in modeling the Pure Premium, that is
# the expected total claim amount per unit of exposure for each policyholder
# in their portfolio:
df["PurePremium"] = df["ClaimAmount"] / df["Exposure"]
# This can be indirectly approximated by a 2-step modeling: the product of the
# Frequency times the average claim amount per claim:
df["Frequency"] = df["ClaimNb"] / df["Exposure"]
df["AvgClaimAmount"] = df["ClaimAmount"] / np.fmax(df["ClaimNb"], 1)
with pd.option_context("display.max_columns", 15):
print(df[df.ClaimAmount > 0].head())
ClaimNb Exposure Area VehPower VehAge DrivAge BonusMalus VehBrand \
IDpol
139 1 0.75 F 7 1 61 50 B12
190 1 0.14 B 12 5 50 60 B12
414 1 0.14 E 4 0 36 85 B12
424 2 0.62 F 10 0 51 100 B12
463 1 0.31 A 5 0 45 50 B12
VehGas Density Region ClaimAmount PurePremium Frequency \
IDpol
139 'Regular' 27000 R11 303.00 404.000000 1.333333
190 'Diesel' 56 R25 1981.84 14156.000000 7.142857
414 'Regular' 4792 R11 1456.55 10403.928571 7.142857
424 'Regular' 27000 R11 10834.00 17474.193548 3.225806
463 'Regular' 12 R73 3986.67 12860.225806 3.225806
AvgClaimAmount
IDpol
139 303.00
190 1981.84
414 1456.55
424 5417.00
463 3986.67
頻率模型 – Poisson 分佈#
索賠次數 (ClaimNb) 是一個正整數(包含 0)。因此,此目標可以使用 Poisson 分佈建模。然後假設為在給定時間間隔(曝險,以年為單位)內以恆定速率發生的離散事件次數。這裡我們為頻率 y = ClaimNb / Exposure 建模,這仍然是一個(縮放的)Poisson 分佈,並使用 Exposure 作為 sample_weight。
from sklearn.linear_model import PoissonRegressor
from sklearn.model_selection import train_test_split
df_train, df_test, X_train, X_test = train_test_split(df, X, random_state=0)
讓我們記住,儘管此資料集中資料點的數量看似龐大,但索賠金額非零的評估點數量卻相當少
len(df_test)
169504
len(df_test[df_test["ClaimAmount"] > 0])
6237
因此,我們預期在隨機重新取樣訓練測試分割時,我們的評估會出現顯著的變異性。
模型的參數是透過 Newton 解算器在訓練集上最小化 Poisson 偏差來估計的。某些特徵是共線性的(例如,因為我們沒有在 OneHotEncoder 中刪除任何類別等級),我們使用弱 L2 懲罰來避免數值問題。
glm_freq = PoissonRegressor(alpha=1e-4, solver="newton-cholesky")
glm_freq.fit(X_train, df_train["Frequency"], sample_weight=df_train["Exposure"])
scores = score_estimator(
glm_freq,
X_train,
X_test,
df_train,
df_test,
target="Frequency",
weights="Exposure",
)
print("Evaluation of PoissonRegressor on target Frequency")
print(scores)
Evaluation of PoissonRegressor on target Frequency
subset train test
metric
D² explained 0.0448 0.0427
mean abs. error 0.1379 0.1378
mean squared error 0.2441 0.2246
請注意,在測試集上測得的分數令人驚訝地比在訓練集上的分數好。這可能特定於此隨機訓練測試分割。適當的交叉驗證可以幫助我們評估這些結果的取樣變異性。
我們可以視覺化方式比較觀察值和預測值,並依駕駛人年齡 (DrivAge)、車輛年齡 (VehAge) 和保險獎金/懲罰 (BonusMalus) 進行彙總。
fig, ax = plt.subplots(ncols=2, nrows=2, figsize=(16, 8))
fig.subplots_adjust(hspace=0.3, wspace=0.2)
plot_obs_pred(
df=df_train,
feature="DrivAge",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_train),
y_label="Claim Frequency",
title="train data",
ax=ax[0, 0],
)
plot_obs_pred(
df=df_test,
feature="DrivAge",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_test),
y_label="Claim Frequency",
title="test data",
ax=ax[0, 1],
fill_legend=True,
)
plot_obs_pred(
df=df_test,
feature="VehAge",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_test),
y_label="Claim Frequency",
title="test data",
ax=ax[1, 0],
fill_legend=True,
)
plot_obs_pred(
df=df_test,
feature="BonusMalus",
weight="Exposure",
observed="Frequency",
predicted=glm_freq.predict(X_test),
y_label="Claim Frequency",
title="test data",
ax=ax[1, 1],
fill_legend=True,
)
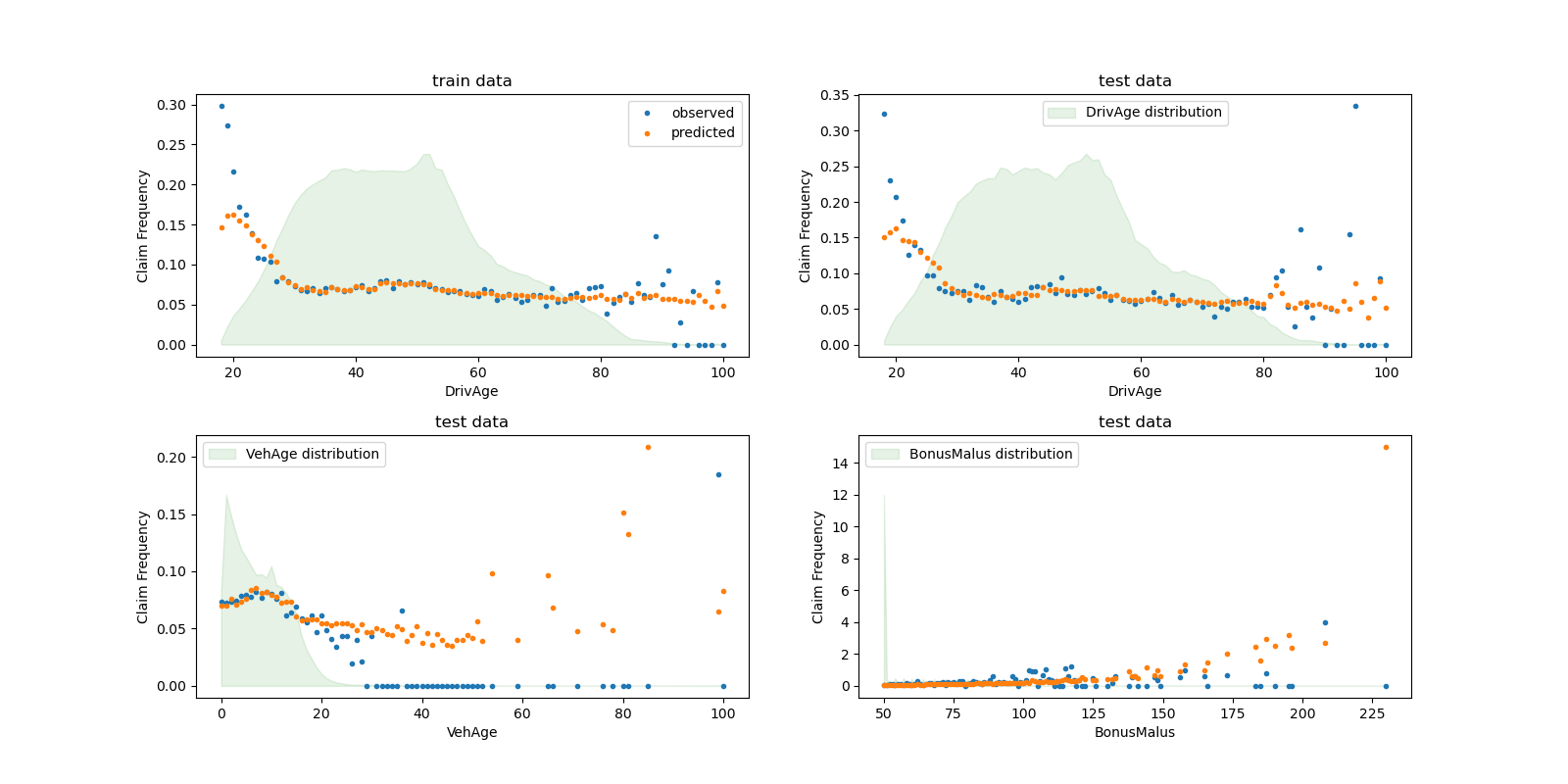
根據觀察到的資料,30 歲以下駕駛人的事故頻率較高,並且與 BonusMalus 變數呈正相關。我們的模型大多能夠正確地為此行為建模。
嚴重性模型 - Gamma 分佈#
平均索賠金額或嚴重性 (AvgClaimAmount) 可以透過經驗顯示,大致遵循 Gamma 分佈。我們使用與頻率模型相同的特徵,為嚴重性擬合 GLM 模型。
註
我們篩除
ClaimAmount == 0,因為 Gamma 分佈支援 \((0, \infty)\),而不是 \([0, \infty)\)。我們使用
ClaimNb作為sample_weight,以考慮包含多個索賠的保單。
from sklearn.linear_model import GammaRegressor
mask_train = df_train["ClaimAmount"] > 0
mask_test = df_test["ClaimAmount"] > 0
glm_sev = GammaRegressor(alpha=10.0, solver="newton-cholesky")
glm_sev.fit(
X_train[mask_train.values],
df_train.loc[mask_train, "AvgClaimAmount"],
sample_weight=df_train.loc[mask_train, "ClaimNb"],
)
scores = score_estimator(
glm_sev,
X_train[mask_train.values],
X_test[mask_test.values],
df_train[mask_train],
df_test[mask_test],
target="AvgClaimAmount",
weights="ClaimNb",
)
print("Evaluation of GammaRegressor on target AvgClaimAmount")
print(scores)
Evaluation of GammaRegressor on target AvgClaimAmount
subset train test
metric
D² explained 3.900000e-03 4.400000e-03
mean abs. error 1.756746e+03 1.744042e+03
mean squared error 5.801770e+07 5.030677e+07
這些指標的值不一定容易解釋。將它們與不使用任何輸入特徵,且始終在相同設定中預測恆定值(即平均索賠金額)的模型進行比較可能會很有見地
from sklearn.dummy import DummyRegressor
dummy_sev = DummyRegressor(strategy="mean")
dummy_sev.fit(
X_train[mask_train.values],
df_train.loc[mask_train, "AvgClaimAmount"],
sample_weight=df_train.loc[mask_train, "ClaimNb"],
)
scores = score_estimator(
dummy_sev,
X_train[mask_train.values],
X_test[mask_test.values],
df_train[mask_train],
df_test[mask_test],
target="AvgClaimAmount",
weights="ClaimNb",
)
print("Evaluation of a mean predictor on target AvgClaimAmount")
print(scores)
Evaluation of a mean predictor on target AvgClaimAmount
subset train test
metric
D² explained 0.000000e+00 -0.000000e+00
mean abs. error 1.756687e+03 1.744497e+03
mean squared error 5.803882e+07 5.033764e+07
我們得出結論,索賠金額非常難以預測。儘管如此,GammaRegressor 能夠利用輸入特徵中的一些資訊,在 D² 方面略微改善平均基準。
請注意,產生的模型是每次索賠的平均索賠金額。因此,它取決於至少有一項索賠,並且不能用於預測每份保單的平均索賠金額。為此,它需要與索賠頻率模型結合使用。
print(
"Mean AvgClaim Amount per policy: %.2f "
% df_train["AvgClaimAmount"].mean()
)
print(
"Mean AvgClaim Amount | NbClaim > 0: %.2f"
% df_train["AvgClaimAmount"][df_train["AvgClaimAmount"] > 0].mean()
)
print(
"Predicted Mean AvgClaim Amount | NbClaim > 0: %.2f"
% glm_sev.predict(X_train).mean()
)
print(
"Predicted Mean AvgClaim Amount (dummy) | NbClaim > 0: %.2f"
% dummy_sev.predict(X_train).mean()
)
Mean AvgClaim Amount per policy: 71.78
Mean AvgClaim Amount | NbClaim > 0: 1951.21
Predicted Mean AvgClaim Amount | NbClaim > 0: 1940.95
Predicted Mean AvgClaim Amount (dummy) | NbClaim > 0: 1978.59
我們可以視覺化方式比較觀察值和預測值,並依駕駛人年齡 (DrivAge) 進行彙總。
fig, ax = plt.subplots(ncols=1, nrows=2, figsize=(16, 6))
plot_obs_pred(
df=df_train.loc[mask_train],
feature="DrivAge",
weight="Exposure",
observed="AvgClaimAmount",
predicted=glm_sev.predict(X_train[mask_train.values]),
y_label="Average Claim Severity",
title="train data",
ax=ax[0],
)
plot_obs_pred(
df=df_test.loc[mask_test],
feature="DrivAge",
weight="Exposure",
observed="AvgClaimAmount",
predicted=glm_sev.predict(X_test[mask_test.values]),
y_label="Average Claim Severity",
title="test data",
ax=ax[1],
fill_legend=True,
)
plt.tight_layout()
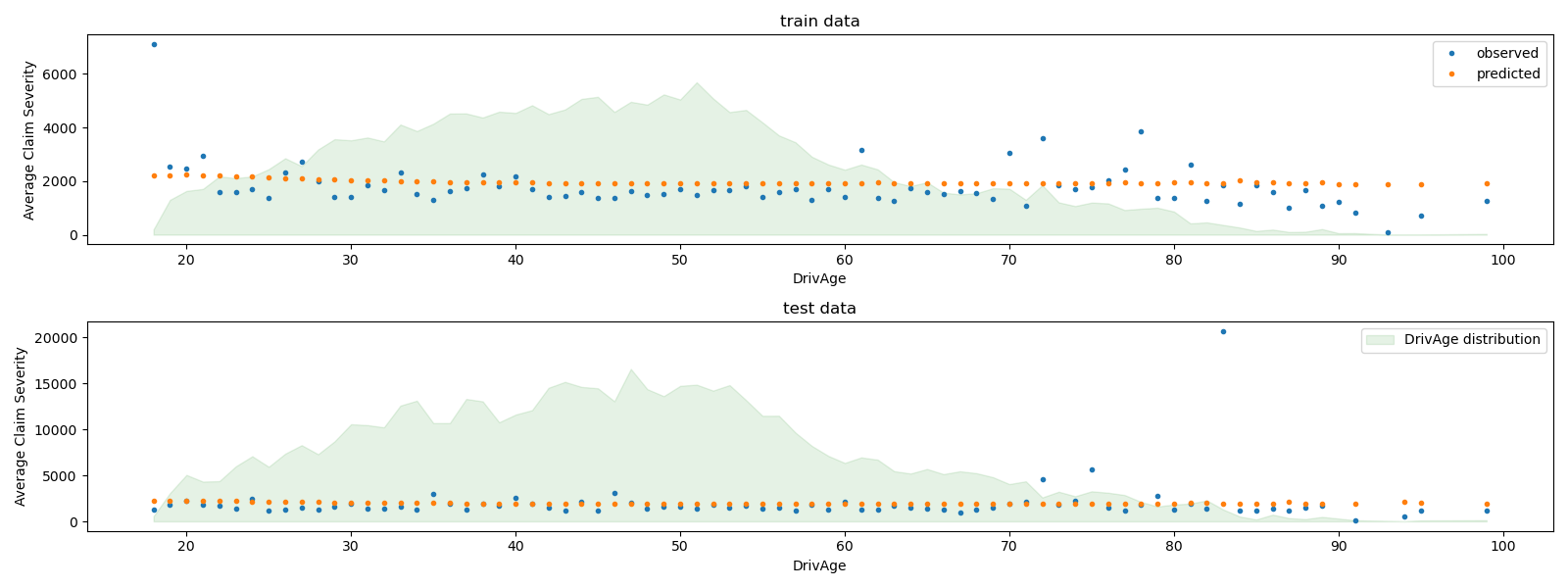
總體而言,駕駛人年齡 (DrivAge) 對索賠嚴重性的影響較小,無論是在觀察到的資料還是在預測的資料中。
透過產品模型與單個 TweedieRegressor 進行純保費建模#
如簡介中所述,每個曝險單位的總索賠金額可以建模為頻率模型的預測值乘以嚴重性模型的預測值。
或者,可以直接使用一個獨特的複合卜瓦松伽瑪廣義線性模型(具有對數連結函數)來模擬總損失。此模型是 Tweedie GLM 的一個特例,其「冪次」參數為 \(p \in (1, 2)\)。在這裡,我們預先將 Tweedie 模型的 power 參數固定為有效範圍內的某個任意值 (1.9)。理想情況下,應該透過網格搜尋來最小化 Tweedie 模型的負對數似然函數來選擇此值,但不幸的是,目前的實作尚不允許這樣做(目前還不行)。
我們將比較這兩種方法的效能。為了量化這兩個模型的效能,可以計算訓練和測試資料的平均偏差,假設總索賠金額的分布為複合卜瓦松-伽瑪分布。這等同於具有介於 1 和 2 之間的 power 參數的 Tweedie 分布。
sklearn.metrics.mean_tweedie_deviance 取決於 power 參數。由於我們不知道 power 參數的真實值,我們在此計算一系列可能值的平均偏差,並並排比較這些模型,也就是說,我們在相同的 power 值下比較它們。理想情況下,我們希望一個模型在無論 power 為何值時,都始終優於另一個模型。
from sklearn.linear_model import TweedieRegressor
glm_pure_premium = TweedieRegressor(power=1.9, alpha=0.1, solver="newton-cholesky")
glm_pure_premium.fit(
X_train, df_train["PurePremium"], sample_weight=df_train["Exposure"]
)
tweedie_powers = [1.5, 1.7, 1.8, 1.9, 1.99, 1.999, 1.9999]
scores_product_model = score_estimator(
(glm_freq, glm_sev),
X_train,
X_test,
df_train,
df_test,
target="PurePremium",
weights="Exposure",
tweedie_powers=tweedie_powers,
)
scores_glm_pure_premium = score_estimator(
glm_pure_premium,
X_train,
X_test,
df_train,
df_test,
target="PurePremium",
weights="Exposure",
tweedie_powers=tweedie_powers,
)
scores = pd.concat(
[scores_product_model, scores_glm_pure_premium],
axis=1,
sort=True,
keys=("Product Model", "TweedieRegressor"),
)
print("Evaluation of the Product Model and the Tweedie Regressor on target PurePremium")
with pd.option_context("display.expand_frame_repr", False):
print(scores)
Evaluation of the Product Model and the Tweedie Regressor on target PurePremium
Product Model TweedieRegressor
subset train test train test
metric
D² explained NaN NaN 1.640000e-02 1.370000e-02
mean Tweedie dev p=1.5000 7.669930e+01 7.617050e+01 7.640770e+01 7.640880e+01
mean Tweedie dev p=1.7000 3.695740e+01 3.683980e+01 3.682880e+01 3.692270e+01
mean Tweedie dev p=1.8000 3.046010e+01 3.040530e+01 3.037600e+01 3.045390e+01
mean Tweedie dev p=1.9000 3.387580e+01 3.385000e+01 3.382120e+01 3.387830e+01
mean Tweedie dev p=1.9900 2.015716e+02 2.015414e+02 2.015347e+02 2.015587e+02
mean Tweedie dev p=1.9990 1.914573e+03 1.914370e+03 1.914538e+03 1.914387e+03
mean Tweedie dev p=1.9999 1.904751e+04 1.904556e+04 1.904747e+04 1.904558e+04
mean abs. error 2.730119e+02 2.722128e+02 2.739865e+02 2.731249e+02
mean squared error 3.295040e+07 3.212197e+07 3.295505e+07 3.213056e+07
在此範例中,這兩種建模方法產生了可比較的效能指標。由於實作上的原因,對於乘積模型,無法取得解釋變異數的百分比 \(D^2\)。
我們還可以透過比較測試和訓練子集中觀察到的總索賠金額與預測的總索賠金額來驗證這些模型。我們看到,平均而言,這兩個模型都傾向於低估總索賠金額(但這種行為取決於正規化的程度)。
res = []
for subset_label, X, df in [
("train", X_train, df_train),
("test", X_test, df_test),
]:
exposure = df["Exposure"].values
res.append(
{
"subset": subset_label,
"observed": df["ClaimAmount"].values.sum(),
"predicted, frequency*severity model": np.sum(
exposure * glm_freq.predict(X) * glm_sev.predict(X)
),
"predicted, tweedie, power=%.2f"
% glm_pure_premium.power: np.sum(exposure * glm_pure_premium.predict(X)),
}
)
print(pd.DataFrame(res).set_index("subset").T)
subset train test
observed 3.917618e+07 1.299546e+07
predicted, frequency*severity model 3.916555e+07 1.313276e+07
predicted, tweedie, power=1.90 3.951751e+07 1.325198e+07
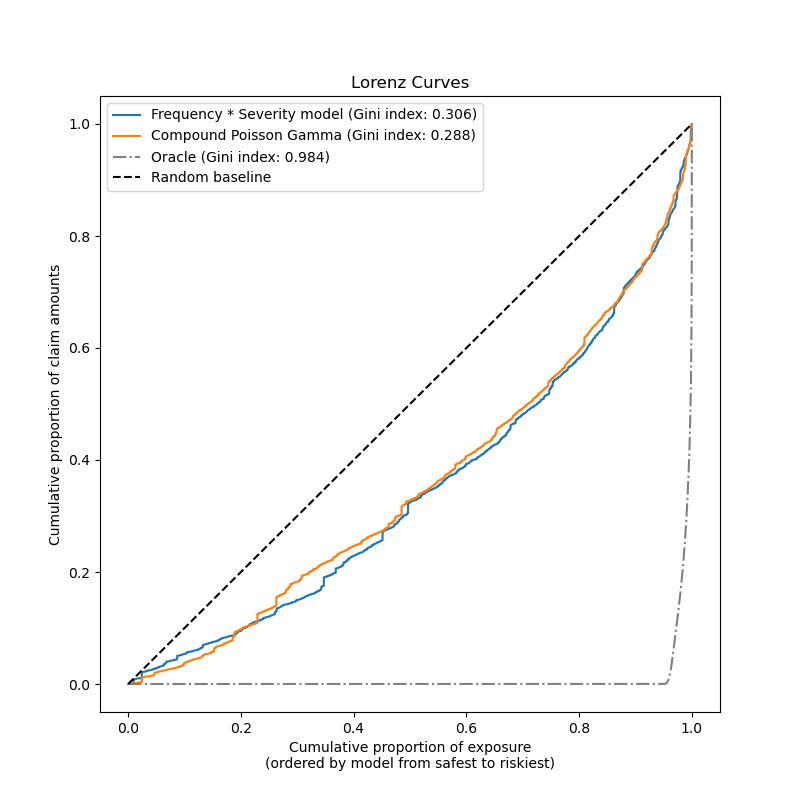
最後,我們可以透過繪製累積索賠圖來比較這兩個模型:對於每個模型,保戶會根據模型預測從最安全到風險最高進行排序,並針對累積曝險比例繪製累積索賠金額比例。此圖通常稱為模型的排序羅倫茲曲線。
吉尼係數(基於曲線和對角線之間的面積)可以用作模型選擇指標,以量化模型對保戶進行排序的能力。請注意,此指標不反映模型在總索賠金額絕對值方面做出準確預測的能力,而僅反映相對於排序指標的相對金額。吉尼係數的上限為 1.0,但即使是根據觀察到的索賠金額對保戶進行排序的預言模型也無法達到 1.0 的分數。
我們觀察到,這兩個模型都能夠根據風險顯著地優於隨機排序來對保戶進行排序,儘管由於從少數特徵預測問題的自然困難,它們也都遠離預言模型:大多數事故都是無法預測的,並且可能是由環境因素造成的,而模型的輸入特徵根本沒有描述這些因素。
請注意,吉尼指數僅描述模型的排序效能,而不描述其校準:對預測的任何單調轉換都會使模型的吉尼指數保持不變。
最後,應該強調的是,直接擬合純保費的複合卜瓦松伽瑪模型在操作上更容易開發和維護,因為它由單個 scikit-learn 估算器組成,而不是一對模型,每個模型都有自己的一組超參數。
from sklearn.metrics import auc
def lorenz_curve(y_true, y_pred, exposure):
y_true, y_pred = np.asarray(y_true), np.asarray(y_pred)
exposure = np.asarray(exposure)
# order samples by increasing predicted risk:
ranking = np.argsort(y_pred)
ranked_exposure = exposure[ranking]
ranked_pure_premium = y_true[ranking]
cumulative_claim_amount = np.cumsum(ranked_pure_premium * ranked_exposure)
cumulative_claim_amount /= cumulative_claim_amount[-1]
cumulative_exposure = np.cumsum(ranked_exposure)
cumulative_exposure /= cumulative_exposure[-1]
return cumulative_exposure, cumulative_claim_amount
fig, ax = plt.subplots(figsize=(8, 8))
y_pred_product = glm_freq.predict(X_test) * glm_sev.predict(X_test)
y_pred_total = glm_pure_premium.predict(X_test)
for label, y_pred in [
("Frequency * Severity model", y_pred_product),
("Compound Poisson Gamma", y_pred_total),
]:
cum_exposure, cum_claims = lorenz_curve(
df_test["PurePremium"], y_pred, df_test["Exposure"]
)
gini = 1 - 2 * auc(cum_exposure, cum_claims)
label += " (Gini index: {:.3f})".format(gini)
ax.plot(cum_exposure, cum_claims, linestyle="-", label=label)
# Oracle model: y_pred == y_test
cum_exposure, cum_claims = lorenz_curve(
df_test["PurePremium"], df_test["PurePremium"], df_test["Exposure"]
)
gini = 1 - 2 * auc(cum_exposure, cum_claims)
label = "Oracle (Gini index: {:.3f})".format(gini)
ax.plot(cum_exposure, cum_claims, linestyle="-.", color="gray", label=label)
# Random baseline
ax.plot([0, 1], [0, 1], linestyle="--", color="black", label="Random baseline")
ax.set(
title="Lorenz Curves",
xlabel=(
"Cumulative proportion of exposure\n"
"(ordered by model from safest to riskiest)"
),
ylabel="Cumulative proportion of claim amounts",
)
ax.legend(loc="upper left")
plt.plot()
[]
腳本的總執行時間: (0 分鐘 8.864 秒)
相關範例