注意
移至結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
梯度提升迴歸的預測區間#
此範例展示如何使用分位數迴歸來建立預測區間。請參閱 直方圖梯度提升樹狀結構中的特徵,以取得展示 HistGradientBoostingRegressor 其他一些特徵的範例。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
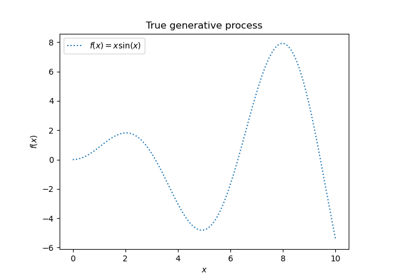
透過將函式 f 應用於均勻取樣的隨機輸入,為合成迴歸問題產生一些資料。
import numpy as np
from sklearn.model_selection import train_test_split
def f(x):
"""The function to predict."""
return x * np.sin(x)
rng = np.random.RandomState(42)
X = np.atleast_2d(rng.uniform(0, 10.0, size=1000)).T
expected_y = f(X).ravel()
為了使問題有趣,我們將目標 y 的觀察值產生為由函式 f 計算的確定性項和遵循中心 對數常態 的隨機雜訊項的總和。為了讓這個更有趣,我們考慮雜訊的振幅取決於輸入變數 x(異質性雜訊)的情況。
對數常態分佈是非對稱且長尾的:觀察大型離群值是可能的,但不可能觀察小型離群值。
sigma = 0.5 + X.ravel() / 10
noise = rng.lognormal(sigma=sigma) - np.exp(sigma**2 / 2)
y = expected_y + noise
分割為訓練和測試資料集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
擬合非線性分位數和最小平方迴歸器#
擬合使用分位數損失和 alpha=0.05、0.5、0.95 訓練的梯度提升模型。
alpha=0.05 和 alpha=0.95 獲得的模型會產生 90% 的信賴區間 (95% - 5% = 90%)。
使用 alpha=0.5 訓練的模型會產生中位數的迴歸:平均而言,預測值上方和下方應有相同數量的目標觀察值。
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_pinball_loss, mean_squared_error
all_models = {}
common_params = dict(
learning_rate=0.05,
n_estimators=200,
max_depth=2,
min_samples_leaf=9,
min_samples_split=9,
)
for alpha in [0.05, 0.5, 0.95]:
gbr = GradientBoostingRegressor(loss="quantile", alpha=alpha, **common_params)
all_models["q %1.2f" % alpha] = gbr.fit(X_train, y_train)
請注意,HistGradientBoostingRegressor 比 GradientBoostingRegressor 快得多,從中繼資料集 (n_samples >= 10_000) 開始,這不是本範例的情況。
為了比較,我們也擬合使用通常的(平均)平方誤差 (MSE) 訓練的基準模型。
gbr_ls = GradientBoostingRegressor(loss="squared_error", **common_params)
all_models["mse"] = gbr_ls.fit(X_train, y_train)
建立跨越 [0, 10] 範圍的均勻間隔輸入值評估集。
xx = np.atleast_2d(np.linspace(0, 10, 1000)).T
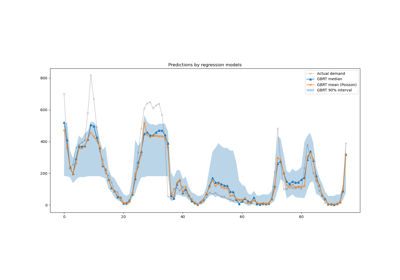
繪製真正的條件平均函式 f、條件平均的預測(損失等於平方誤差)、條件中位數和條件 90% 區間(從第 5 個到第 95 個條件百分位數)。
import matplotlib.pyplot as plt
y_pred = all_models["mse"].predict(xx)
y_lower = all_models["q 0.05"].predict(xx)
y_upper = all_models["q 0.95"].predict(xx)
y_med = all_models["q 0.50"].predict(xx)
fig = plt.figure(figsize=(10, 10))
plt.plot(xx, f(xx), "g:", linewidth=3, label=r"$f(x) = x\,\sin(x)$")
plt.plot(X_test, y_test, "b.", markersize=10, label="Test observations")
plt.plot(xx, y_med, "r-", label="Predicted median")
plt.plot(xx, y_pred, "r-", label="Predicted mean")
plt.plot(xx, y_upper, "k-")
plt.plot(xx, y_lower, "k-")
plt.fill_between(
xx.ravel(), y_lower, y_upper, alpha=0.4, label="Predicted 90% interval"
)
plt.xlabel("$x$")
plt.ylabel("$f(x)$")
plt.ylim(-10, 25)
plt.legend(loc="upper left")
plt.show()
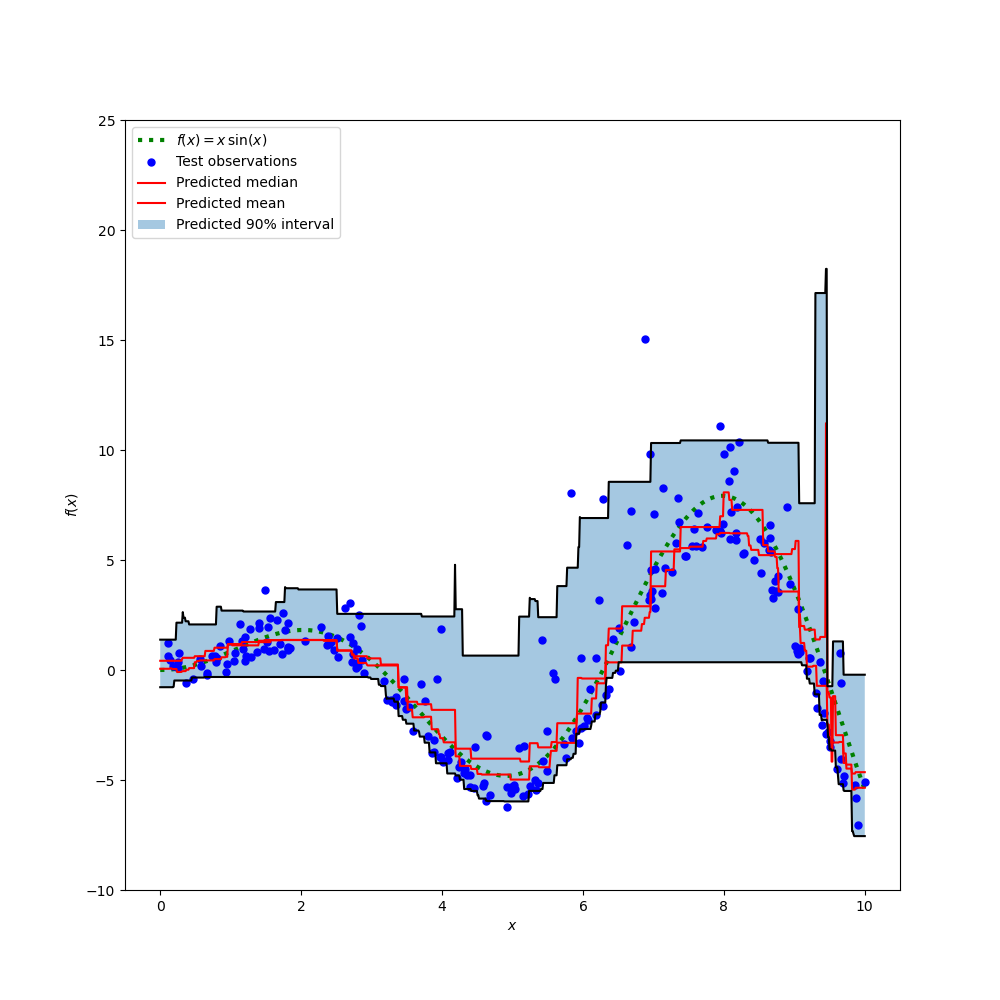
比較預測中位數和預測平均值,我們注意到中位數平均低於平均值,因為雜訊偏向高值(大型離群值)。中位數估計值似乎也更平滑,因為它自然對離群值具有穩健性。
另請注意,梯度提升樹狀結構的誘導偏差不幸地阻止我們的 0.05 分位數完全捕獲訊號的弦波形狀,尤其是在 x=8 附近。如本筆記本的最後一部分所示,調整超參數可以減少此效應。
錯誤指標分析#
使用 mean_squared_error 和 mean_pinball_loss 指標測量訓練資料集上的模型。
import pandas as pd
def highlight_min(x):
x_min = x.min()
return ["font-weight: bold" if v == x_min else "" for v in x]
results = []
for name, gbr in sorted(all_models.items()):
metrics = {"model": name}
y_pred = gbr.predict(X_train)
for alpha in [0.05, 0.5, 0.95]:
metrics["pbl=%1.2f" % alpha] = mean_pinball_loss(y_train, y_pred, alpha=alpha)
metrics["MSE"] = mean_squared_error(y_train, y_pred)
results.append(metrics)
pd.DataFrame(results).set_index("model").style.apply(highlight_min)
一欄顯示由相同指標評估的所有模型。當模型使用相同指標訓練和測量時,應該獲得一欄的最小值。如果訓練收斂,訓練集上應該始終是這種情況。
請注意,由於目標分佈是非對稱的,因此預期的條件平均值和條件中位數差異很大,因此不能使用平方誤差模型來很好地估計條件中位數,反之亦然。
如果目標分佈是對稱的且沒有離群值(例如,具有高斯雜訊),則中位數估計值和最小平方估計值將產生相似的預測。
然後我們在測試集上執行相同的操作。
results = []
for name, gbr in sorted(all_models.items()):
metrics = {"model": name}
y_pred = gbr.predict(X_test)
for alpha in [0.05, 0.5, 0.95]:
metrics["pbl=%1.2f" % alpha] = mean_pinball_loss(y_test, y_pred, alpha=alpha)
metrics["MSE"] = mean_squared_error(y_test, y_pred)
results.append(metrics)
pd.DataFrame(results).set_index("model").style.apply(highlight_min)
錯誤較高表示模型略微過擬合資料。它仍然顯示,當模型透過最小化此相同指標進行訓練時,會獲得最佳測試指標。
請注意,條件中位數估計值在測試集上的 MSE 方面與平方誤差估計值具有競爭力:這可以用平方誤差估計值對大型離群值非常敏感來解釋,這可能會導致嚴重的過擬合。這可以在上一張圖的右側看到。條件中位數估計值有偏差(對於此非對稱雜訊而言是低估),但自然對離群值具有穩健性且過擬合較少。
信賴區間的校準#
我們還可以評估兩個極端分位數估計器產生良好校準的條件 90% 信賴區間的能力。
為此,我們可以計算落在預測之間的觀察值比例
def coverage_fraction(y, y_low, y_high):
return np.mean(np.logical_and(y >= y_low, y <= y_high))
coverage_fraction(
y_train,
all_models["q 0.05"].predict(X_train),
all_models["q 0.95"].predict(X_train),
)
np.float64(0.9)
在訓練集上,校準非常接近 90% 信賴區間的預期涵蓋值。
coverage_fraction(
y_test, all_models["q 0.05"].predict(X_test), all_models["q 0.95"].predict(X_test)
)
np.float64(0.868)
在測試集上,估計的信賴區間略微過窄。但是請注意,我們需要將這些指標包裝在交叉驗證迴圈中,以評估它們在資料重新取樣下的變異性。
調整分位數迴歸器的超參數#
在上圖中,我們觀察到第 5 個百分位數迴歸器似乎欠擬合,並且無法適應訊號的弦波形狀。
該模型的超參數是針對中位數迴歸器大致手動調整的,並且沒有理由認為相同的超參數適用於第 5 個百分位數迴歸器。
為了確認此假設,我們透過交叉驗證在 alpha=0.05 的 Pinball 損失上選擇最佳模型參數,來調整第 5 個百分位數的新迴歸器的超參數
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingRandomSearchCV
from sklearn.metrics import make_scorer
from pprint import pprint
param_grid = dict(
learning_rate=[0.05, 0.1, 0.2],
max_depth=[2, 5, 10],
min_samples_leaf=[1, 5, 10, 20],
min_samples_split=[5, 10, 20, 30, 50],
)
alpha = 0.05
neg_mean_pinball_loss_05p_scorer = make_scorer(
mean_pinball_loss,
alpha=alpha,
greater_is_better=False, # maximize the negative loss
)
gbr = GradientBoostingRegressor(loss="quantile", alpha=alpha, random_state=0)
search_05p = HalvingRandomSearchCV(
gbr,
param_grid,
resource="n_estimators",
max_resources=250,
min_resources=50,
scoring=neg_mean_pinball_loss_05p_scorer,
n_jobs=2,
random_state=0,
).fit(X_train, y_train)
pprint(search_05p.best_params_)
{'learning_rate': 0.2,
'max_depth': 2,
'min_samples_leaf': 20,
'min_samples_split': 10,
'n_estimators': 150}
我們觀察到,針對中位數迴歸器手動調整的超參數與適用於第 5 個百分位數迴歸器的超參數在相同範圍內。
現在讓我們調整第 95 百分位數回歸器的超參數。我們需要重新定義用於選擇最佳模型的 scoring 評分指標,同時調整內部梯度提升估計器的 alpha 參數。
from sklearn.base import clone
alpha = 0.95
neg_mean_pinball_loss_95p_scorer = make_scorer(
mean_pinball_loss,
alpha=alpha,
greater_is_better=False, # maximize the negative loss
)
search_95p = clone(search_05p).set_params(
estimator__alpha=alpha,
scoring=neg_mean_pinball_loss_95p_scorer,
)
search_95p.fit(X_train, y_train)
pprint(search_95p.best_params_)
{'learning_rate': 0.05,
'max_depth': 2,
'min_samples_leaf': 5,
'min_samples_split': 20,
'n_estimators': 150}
結果顯示,搜尋程序所識別的第 95 百分位數回歸器的超參數,與中位數回歸器手動調整的超參數,以及第 5 百分位數回歸器透過搜尋程序識別的超參數大致在相同的範圍內。然而,超參數搜尋確實帶來了改善的 90% 信賴區間,該區間由這兩個調整後的分位數回歸器的預測組成。請注意,由於離群值的存在,較高第 95 百分位數的預測形狀比 較低第 5 百分位數的預測形狀粗糙得多。
y_lower = search_05p.predict(xx)
y_upper = search_95p.predict(xx)
fig = plt.figure(figsize=(10, 10))
plt.plot(xx, f(xx), "g:", linewidth=3, label=r"$f(x) = x\,\sin(x)$")
plt.plot(X_test, y_test, "b.", markersize=10, label="Test observations")
plt.plot(xx, y_upper, "k-")
plt.plot(xx, y_lower, "k-")
plt.fill_between(
xx.ravel(), y_lower, y_upper, alpha=0.4, label="Predicted 90% interval"
)
plt.xlabel("$x$")
plt.ylabel("$f(x)$")
plt.ylim(-10, 25)
plt.legend(loc="upper left")
plt.title("Prediction with tuned hyper-parameters")
plt.show()
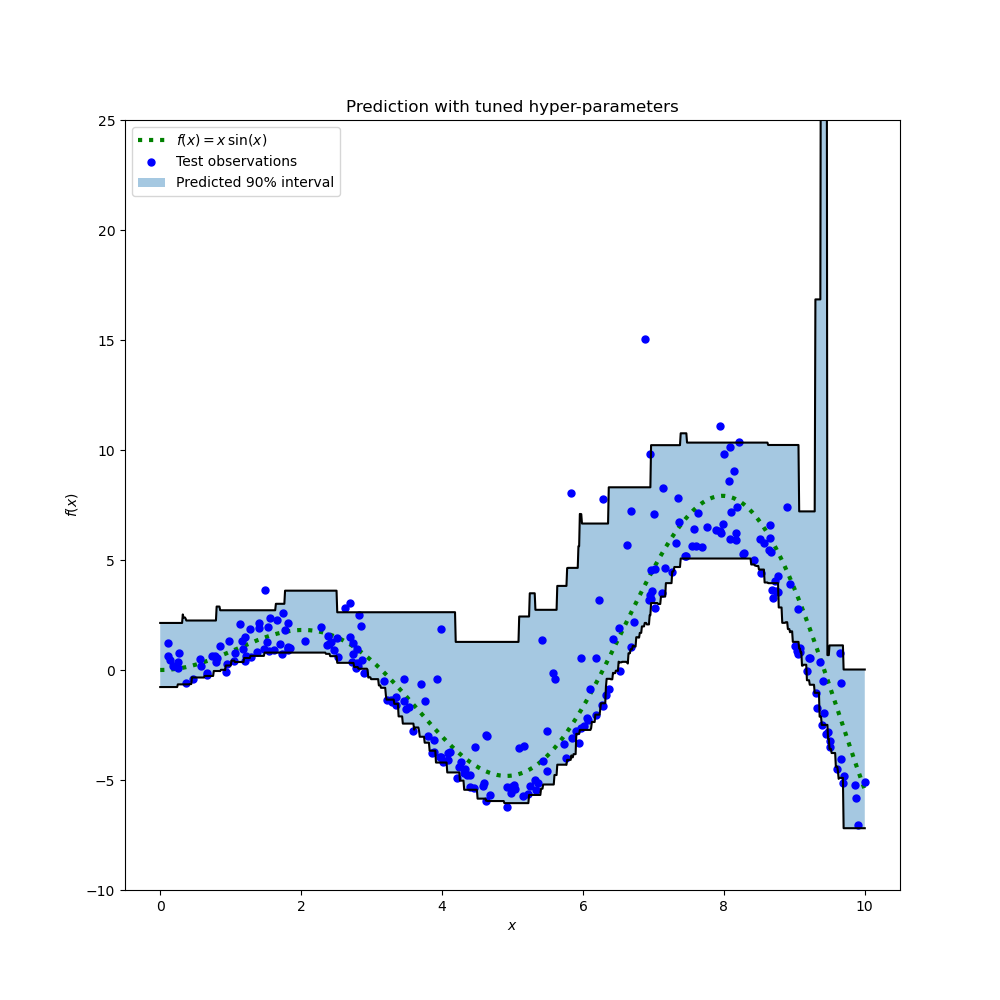
與未調整的模型相比,該圖在質量上看起來更好,尤其是對於較低分位數的形狀。
我們現在定量評估這對估計器的聯合校準情況。
coverage_fraction(y_train, search_05p.predict(X_train), search_95p.predict(X_train))
np.float64(0.9026666666666666)
coverage_fraction(y_test, search_05p.predict(X_test), search_95p.predict(X_test))
np.float64(0.796)
遺憾的是,調整後的一對估計器在測試集上的校準效果並未更好:估計的信賴區間寬度仍然太窄。
同樣地,我們需要將此研究包裝在交叉驗證迴圈中,以更好地評估這些估計值的變異性。
腳本總執行時間: (0 分鐘 12.002 秒)
相關範例