注意
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
多類別訓練元估計器概述#
在此範例中,我們討論目標變數由兩個以上類別組成的分類問題。這稱為多類別分類。
在 scikit-learn 中,所有估計器都支援開箱即用的多類別分類:為最終使用者實作最合理的策略。sklearn.multiclass 模組實作各種策略,可用於實驗或開發僅支援二元分類的第三方估計器。
sklearn.multiclass 包括 OvO/OvR 策略,用於透過擬合一組二元分類器來訓練多類別分類器(OneVsOneClassifier 和 OneVsRestClassifier 元估計器)。此範例將檢視它們。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Yeast UCI 資料集#
在此範例中,我們使用一個 UCI 資料集 [1],通常稱為 Yeast 資料集。我們使用 sklearn.datasets.fetch_openml 函數從 OpenML 載入資料集。
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=181, as_frame=True, return_X_y=True)
為了了解我們正在處理的資料科學問題類型,我們可以檢查我們想要建立預測模型的目標。
y.value_counts().sort_index()
class_protein_localization
CYT 463
ERL 5
EXC 35
ME1 44
ME2 51
ME3 163
MIT 244
NUC 429
POX 20
VAC 30
Name: count, dtype: int64
我們看到目標是離散的,由 10 個類別組成。因此,我們處理的是多類別分類問題。
策略比較#
在以下實驗中,我們使用 DecisionTreeClassifier 和具有 3 個分割和 5 個重複的 RepeatedStratifiedKFold 交叉驗證。
我們比較以下策略
:class:~sklearn.tree.DecisionTreeClassifier 可以處理多類別分類,而無需任何特殊調整。它的工作方式是將訓練資料分解為較小的子集,並專注於每個子集中最常見的類別。透過重複此過程,模型可以準確地將輸入資料分類為多個不同的類別。
OneVsOneClassifier訓練一組二元分類器,其中每個分類器都經過訓練以區分兩個類別。OneVsRestClassifier:訓練一組二元分類器,其中每個分類器都經過訓練以區分一個類別和其餘的類別。OutputCodeClassifier:訓練一組二元分類器,其中每個分類器都經過訓練以區分一組類別與其餘類別。類別組由程式碼簿定義,該程式碼簿在 scikit-learn 中隨機產生。此方法公開一個參數code_size來控制程式碼簿的大小。我們將其設定為大於一,因為我們對壓縮類別表示不感興趣。
import pandas as pd
from sklearn.model_selection import RepeatedStratifiedKFold, cross_validate
from sklearn.multiclass import (
OneVsOneClassifier,
OneVsRestClassifier,
OutputCodeClassifier,
)
from sklearn.tree import DecisionTreeClassifier
cv = RepeatedStratifiedKFold(n_splits=3, n_repeats=5, random_state=0)
tree = DecisionTreeClassifier(random_state=0)
ovo_tree = OneVsOneClassifier(tree)
ovr_tree = OneVsRestClassifier(tree)
ecoc = OutputCodeClassifier(tree, code_size=2)
cv_results_tree = cross_validate(tree, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
我們現在可以比較不同策略的統計效能。我們繪製不同策略的分數分佈。
from matplotlib import pyplot as plt
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("Accuracy score")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"Density of the accuracy scores for the different multiclass strategies"
)
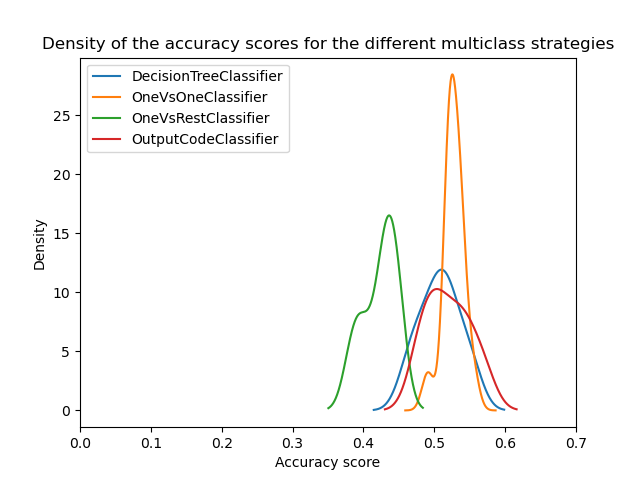
乍看之下,我們可以看到決策樹分類器的內建策略運作得相當好。一對一和錯誤校正輸出碼策略的運作效果甚至更好。但是,一對多策略的運作效果不如其他策略。
實際上,這些結果重現了文獻中報告的內容,如 [2] 所述。然而,事情並非表面上看起來那麼簡單。
超參數搜尋的重要性#
後來的研究在 [3] 中顯示,如果首先優化基礎分類器的超參數,多類別策略會顯示相似的分數。
在這裡,我們嘗試重現這樣的結果,至少要優化基礎決策樹的深度。
from sklearn.model_selection import GridSearchCV
param_grid = {"max_depth": [3, 5, 8]}
tree_optimized = GridSearchCV(tree, param_grid=param_grid, cv=3)
ovo_tree = OneVsOneClassifier(tree_optimized)
ovr_tree = OneVsRestClassifier(tree_optimized)
ecoc = OutputCodeClassifier(tree_optimized, code_size=2)
cv_results_tree = cross_validate(tree_optimized, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("Accuracy score")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"Density of the accuracy scores for the different multiclass strategies"
)
plt.show()
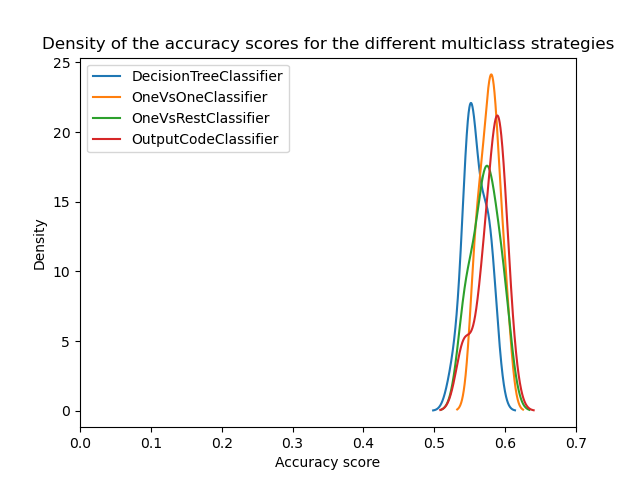
我們可以發現,一旦超參數被優化,所有多類別策略都具有相似的效能,正如 [3] 中所討論的。
結論#
我們可以對這些結果有一些直觀的理解。
首先,當超參數未優化時,一對一和錯誤校正輸出碼優於決策樹的原因在於,它們集成了大量的分類器。集成提高了泛化效能。這有點類似於為什麼在不注意優化超參數的情況下,裝袋分類器通常比單個決策樹表現更好。
然後,我們看到了優化超參數的重要性。實際上,即使集成等技術有助於減少這種影響,但在開發預測模型時也應定期探索超參數。
最後,重要的是要回顧一下,scikit-learn 中的估計器是使用特定的策略來處理多類別分類的。因此,對於這些估計器,意味著不需要使用不同的策略。這些策略主要適用於僅支援二元分類的第三方估計器。在所有情況下,我們也展示了應該優化超參數。
參考文獻#
腳本總執行時間:(0 分鐘 22.014 秒)
相關範例