注意
前往結尾以下載完整的範例程式碼。或通過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
普通最小平方法和嶺迴歸變異數#
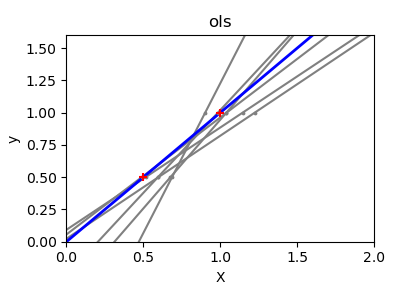
由於每個維度的點很少,並且線性迴歸使用直線來盡可能地跟隨這些點,因此觀察中的雜訊將導致很大的變異數,如第一個圖所示。由於觀察中引起的雜訊,每條線的斜率對於每個預測可能會變化很大。
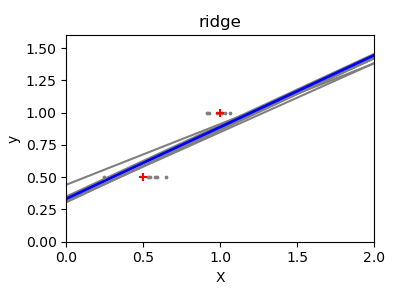
嶺迴歸基本上是最小化最小平方函數的懲罰版本。懲罰會縮小迴歸係數的值。儘管每個維度中的數據點很少,但與標準線性迴歸相比,預測的斜率更穩定,並且線本身的變異數大大降低了。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model
X_train = np.c_[0.5, 1].T
y_train = [0.5, 1]
X_test = np.c_[0, 2].T
np.random.seed(0)
classifiers = dict(
ols=linear_model.LinearRegression(), ridge=linear_model.Ridge(alpha=0.1)
)
for name, clf in classifiers.items():
fig, ax = plt.subplots(figsize=(4, 3))
for _ in range(6):
this_X = 0.1 * np.random.normal(size=(2, 1)) + X_train
clf.fit(this_X, y_train)
ax.plot(X_test, clf.predict(X_test), color="gray")
ax.scatter(this_X, y_train, s=3, c="gray", marker="o", zorder=10)
clf.fit(X_train, y_train)
ax.plot(X_test, clf.predict(X_test), linewidth=2, color="blue")
ax.scatter(X_train, y_train, s=30, c="red", marker="+", zorder=10)
ax.set_title(name)
ax.set_xlim(0, 2)
ax.set_ylim((0, 1.6))
ax.set_xlabel("X")
ax.set_ylabel("y")
fig.tight_layout()
plt.show()
腳本的總執行時間: (0 分鐘 0.304 秒)
相關範例