注意
前往末尾下載完整範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
使用樹狀森林的特徵重要性#
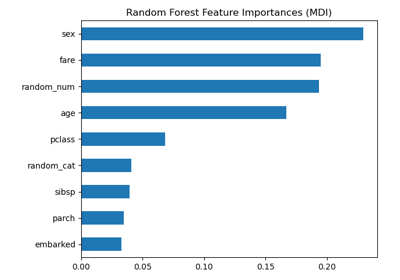
此範例顯示使用樹狀森林來評估人工分類任務中特徵的重要性。藍色長條是森林的特徵重要性,以及由誤差線表示的樹狀間變異性。
正如預期的那樣,該圖表明有 3 個特徵具有資訊性,而其餘的則沒有。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
資料產生和模型擬合#
我們產生一個只有 3 個資訊性特徵的合成資料集。我們將明確地不對資料集進行洗牌,以確保資訊性特徵將對應於 X 的前三列。此外,我們將資料集分割為訓練和測試子集。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False,
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
將擬合隨機森林分類器以計算特徵重要性。
from sklearn.ensemble import RandomForestClassifier
feature_names = [f"feature {i}" for i in range(X.shape[1])]
forest = RandomForestClassifier(random_state=0)
forest.fit(X_train, y_train)
基於平均雜質減少的特徵重要性#
特徵重要性由已擬合屬性 feature_importances_ 提供,它們被計算為每棵樹內雜質減少累積的平均值和標準差。
警告
基於雜質的特徵重要性可能會誤導高基數特徵(許多唯一值)。請參閱以下排列特徵重要性作為替代方案。
Elapsed time to compute the importances: 0.009 seconds
讓我們繪製基於雜質的重要性。
import pandas as pd
forest_importances = pd.Series(importances, index=feature_names)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
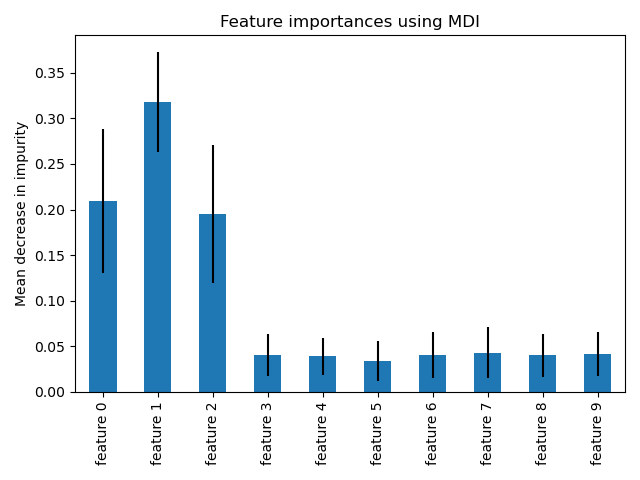
我們觀察到,正如預期的那樣,發現前三個特徵很重要。
基於特徵排列的特徵重要性#
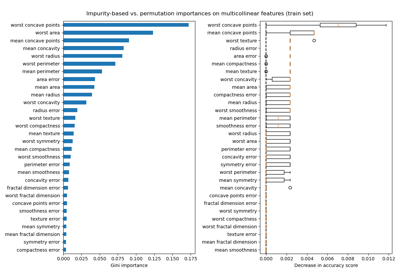
排列特徵重要性克服了基於雜質的特徵重要性的限制:它們不會偏向高基數特徵,並且可以在排除的測試集上計算。
from sklearn.inspection import permutation_importance
start_time = time.time()
result = permutation_importance(
forest, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
forest_importances = pd.Series(result.importances_mean, index=feature_names)
Elapsed time to compute the importances: 0.726 seconds
完整排列重要性的計算成本更高。特徵會被隨機洗牌 n 次,並重新擬合模型以估計其重要性。有關詳細資訊,請參閱排列特徵重要性。我們現在可以繪製重要性排名。
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=result.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_ylabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()
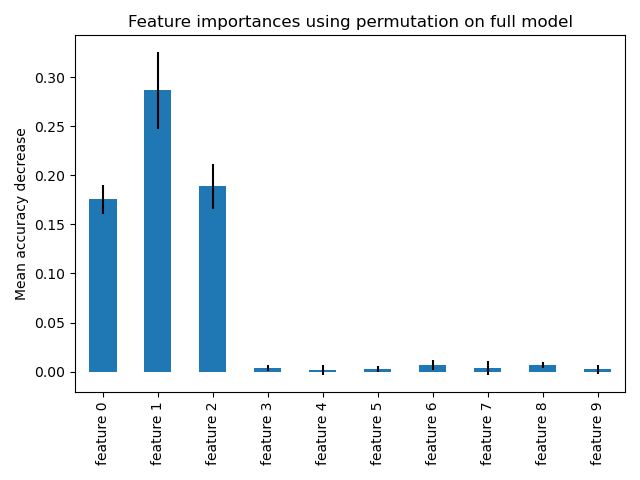
使用兩種方法檢測到的最重要特徵相同。儘管相對重要性有所不同。如圖所示,與排列重要性相比,MDI 不太可能完全省略某個特徵。
腳本的總執行時間: (0 分鐘 1.355 秒)
相關範例