注意
前往結尾下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
用於稀疏訊號的基於 L1 的模型#
本範例比較了三個基於 l1 的迴歸模型,它們使用從稀疏且相關的特徵獲得的合成訊號,這些訊號進一步被加性高斯雜訊破壞
一個 Lasso;
一個 自動相關性決定 - ARD;
一個 彈性網路。
眾所周知,當資料維度增加時,如果無關變數與相關變數的相關性不太高,則 Lasso 估計值會趨向於接近模型選擇估計值。在存在相關特徵的情況下,Lasso 本身無法選擇正確的稀疏模式 [1]。
在這裡,我們比較三個模型在 \(R^2\) 分數、擬合時間和估計係數與真實值的稀疏性方面的效能。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
產生合成資料集#
我們產生一個資料集,其中樣本數少於特徵總數。這導致一個欠定系統,即解不是唯一的,因此我們無法單獨應用普通最小平方法。正規化將懲罰項引入目標函數,這會修改最佳化問題,並有助於減輕系統的欠定性質。
目標 y 是正弦訊號的線性組合,具有交替的符號。僅使用 X 中 100 個頻率中最低的 10 個頻率來產生 y,而其餘的特徵則不提供資訊。這會導致高維稀疏特徵空間,其中需要某種程度的 l1 懲罰。
import numpy as np
rng = np.random.RandomState(0)
n_samples, n_features, n_informative = 50, 100, 10
time_step = np.linspace(-2, 2, n_samples)
freqs = 2 * np.pi * np.sort(rng.rand(n_features)) / 0.01
X = np.zeros((n_samples, n_features))
for i in range(n_features):
X[:, i] = np.sin(freqs[i] * time_step)
idx = np.arange(n_features)
true_coef = (-1) ** idx * np.exp(-idx / 10)
true_coef[n_informative:] = 0 # sparsify coef
y = np.dot(X, true_coef)
一些資訊豐富的特徵具有接近的頻率,以誘導(反)相關性。
freqs[:n_informative]
array([ 2.9502547 , 11.8059798 , 12.63394388, 12.70359377, 24.62241605,
37.84077985, 40.30506066, 44.63327171, 54.74495357, 59.02456369])
使用 numpy.random.random_sample 引入隨機相位,並將一些高斯雜訊(由 numpy.random.normal 實現)新增到特徵和目標。
for i in range(n_features):
X[:, i] = np.sin(freqs[i] * time_step + 2 * (rng.random_sample() - 0.5))
X[:, i] += 0.2 * rng.normal(0, 1, n_samples)
y += 0.2 * rng.normal(0, 1, n_samples)
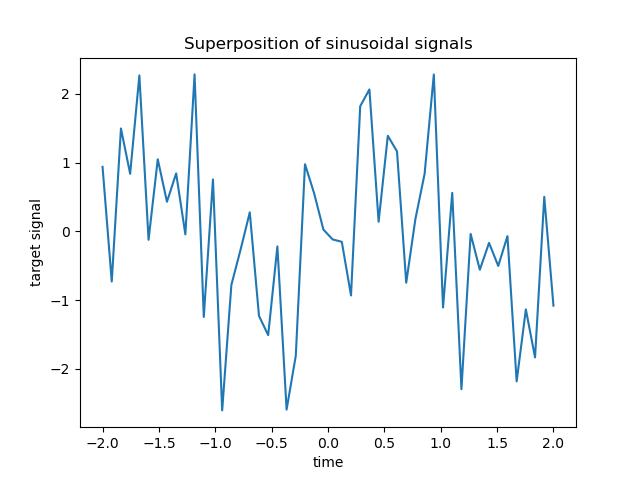
此類稀疏、雜訊和相關的特徵可以從監控某些環境變數的感測器節點獲得,因為它們通常會根據其位置(空間相關性)記錄相似的值。我們可以視覺化目標。
import matplotlib.pyplot as plt
plt.plot(time_step, y)
plt.ylabel("target signal")
plt.xlabel("time")
_ = plt.title("Superposition of sinusoidal signals")
為了簡單起見,我們將資料分割成訓練集和測試集。實際上,應使用 TimeSeriesSplit 交叉驗證來估計測試分數的變異數。在這裡,我們設定 shuffle="False",因為在處理具有時間關係的資料時,我們絕不能使用在測試資料之後的訓練資料。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
在下文中,我們計算三個基於 l1 的模型在擬合優度 \(R^2\) 分數和擬合時間方面的效能。然後,我們繪製一個圖表來比較估計係數的稀疏性與真實係數,最後我們分析先前的結果。
Lasso#
在本範例中,我們示範具有固定正規化參數 alpha 值的 Lasso。實際上,最佳參數 alpha 應透過將 TimeSeriesSplit 交叉驗證策略傳遞到 LassoCV 來選擇。為了使範例簡單且快速執行,我們在此處直接設定 alpha 的最佳值。
from time import time
from sklearn.linear_model import Lasso
from sklearn.metrics import r2_score
t0 = time()
lasso = Lasso(alpha=0.14).fit(X_train, y_train)
print(f"Lasso fit done in {(time() - t0):.3f}s")
y_pred_lasso = lasso.predict(X_test)
r2_score_lasso = r2_score(y_test, y_pred_lasso)
print(f"Lasso r^2 on test data : {r2_score_lasso:.3f}")
Lasso fit done in 0.001s
Lasso r^2 on test data : 0.480
自動相關性決定 (ARD)#
ARD 迴歸是 Lasso 的貝葉斯版本。如果需要,它可以為所有參數(包括誤差變異數)產生區間估計值。當訊號具有高斯雜訊時,這是一個合適的選項。請參閱範例 比較線性貝葉斯迴歸器,以比較 ARDRegression 和 BayesianRidge 迴歸器。
from sklearn.linear_model import ARDRegression
t0 = time()
ard = ARDRegression().fit(X_train, y_train)
print(f"ARD fit done in {(time() - t0):.3f}s")
y_pred_ard = ard.predict(X_test)
r2_score_ard = r2_score(y_test, y_pred_ard)
print(f"ARD r^2 on test data : {r2_score_ard:.3f}")
ARD fit done in 0.020s
ARD r^2 on test data : 0.543
彈性網路#
ElasticNet 是 Lasso 和 Ridge 之間的中間點,因為它結合了 L1 和 L2 懲罰。正規化量由兩個超參數 l1_ratio 和 alpha 控制。對於 l1_ratio = 0,懲罰是純粹的 L2,並且模型等效於 Ridge。同樣,l1_ratio = 1 是純粹的 L1 懲罰,並且模型等效於 Lasso。對於 0 < l1_ratio < 1,懲罰是 L1 和 L2 的組合。
與之前一樣,我們使用固定的 alpha 和 l1_ratio 值來訓練模型。為了選擇它們的最佳值,我們使用了 ElasticNetCV,這裡未顯示以使範例簡單。
from sklearn.linear_model import ElasticNet
t0 = time()
enet = ElasticNet(alpha=0.08, l1_ratio=0.5).fit(X_train, y_train)
print(f"ElasticNet fit done in {(time() - t0):.3f}s")
y_pred_enet = enet.predict(X_test)
r2_score_enet = r2_score(y_test, y_pred_enet)
print(f"ElasticNet r^2 on test data : {r2_score_enet:.3f}")
ElasticNet fit done in 0.001s
ElasticNet r^2 on test data : 0.636
結果的繪圖與分析#
在本節中,我們使用熱圖來視覺化各自線性模型的真實係數和估計係數的稀疏性。
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from matplotlib.colors import SymLogNorm
df = pd.DataFrame(
{
"True coefficients": true_coef,
"Lasso": lasso.coef_,
"ARDRegression": ard.coef_,
"ElasticNet": enet.coef_,
}
)
plt.figure(figsize=(10, 6))
ax = sns.heatmap(
df.T,
norm=SymLogNorm(linthresh=10e-4, vmin=-1, vmax=1),
cbar_kws={"label": "coefficients' values"},
cmap="seismic_r",
)
plt.ylabel("linear model")
plt.xlabel("coefficients")
plt.title(
f"Models' coefficients\nLasso $R^2$: {r2_score_lasso:.3f}, "
f"ARD $R^2$: {r2_score_ard:.3f}, "
f"ElasticNet $R^2$: {r2_score_enet:.3f}"
)
plt.tight_layout()
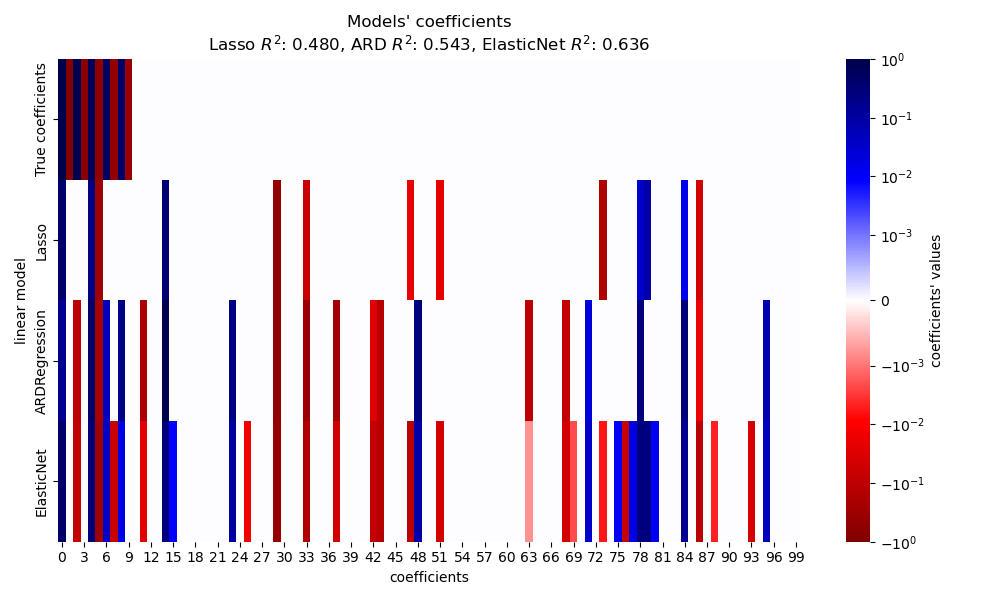
在目前的範例中,ElasticNet 產生最佳分數並捕捉到大部分的預測特徵,但仍然無法找到所有真實成分。請注意,ElasticNet 和 ARDRegression 都產生比 Lasso 稀疏度較低的模型。
結論#
已知 Lasso 可以有效地恢復稀疏資料,但在高度相關的特徵上表現不佳。事實上,如果幾個相關的特徵對目標有貢獻,Lasso 最終會選擇其中一個。對於稀疏但非相關的特徵,Lasso 模型會更適合。
ElasticNet 在係數上引入一些稀疏性,並將它們的值縮小到零。因此,在存在對目標有貢獻的相關特徵時,模型仍然能夠減少它們的權重,而不會將它們完全設定為零。這會產生一個比純 Lasso 更不稀疏的模型,並且也可能捕捉到非預測性特徵。
當處理高斯雜訊時,ARDRegression 表現較好,但仍然無法處理相關特徵,並且由於需要擬合先驗,因此需要更長的時間。
參考文獻#
腳本總執行時間: (0 分鐘 0.506 秒)
相關範例